
Terminology Change Set Exchange
1.0.0-ballot - STU1 Ballot
![]()
Terminology Change Set Exchange
1.0.0-ballot - STU1 Ballot
![]()
This page is part of the Terminology Change Set Exchange (v1.0.0-ballot: STU1 Ballot 1) based on FHIR (HL7® FHIR® Standard) R4. No current official version has been published yet. For a full list of available versions, see the Directory of published versions
| Page standards status: Informative |
Contents:
Tinkar provides the foundation of a knowledge architecture that is intended to integrate reference terminology from distributors (e.g., SNOMED CT®, LOINC®, RxNorm) with local concepts to support interoperable information semantics across the enterprise.
This specification introduces an agile approach to terminology design and formatting that promotes the use of self- describing data. It is a shift from hard-coded models that have been favored due to their prescriptive nature but have shown limited flexibility and extensibility. Like FHIR, this specification places the focus on a self-describing, extensible approach to representing terminology. Therefore, Tinkar aims to be both self-describing and completely machine processed:
This specification describes the requirements and characteristics of systems required to manage terminology produced by a variety of organizations across a healthcare enterprise. This foundation must allow enterprise to extend terminology standards and implement extensions in a timely fashion.
This specification is intended to support healthcare organizations' standard terminology modules, value sets, and coding systems as well as local terms and equivalence mappings.
A standard-based Tinkar specification is necessary to support the operation of a variety of systems intended to deliver knowledge management for terminology to vendors, providers, and even standards-development organizations, like HL7.
Previous efforts have attempted to create a common set of terminology capabilities and services by specifying a single predefined structure for managing terminology. Unfortunately, a hardwired structure that works for one standard may not work for another. The inability to integrate content across terminology standards is a barrier to implementing services and modules that can deliver integrated concepts, code lists, and value sets required by enterprise systems for treatment, research, business process automation, quality measures, and outcome analysis.
The Unified Medical Language System (UMLS) Metathesaurus is a compilation of multiple sources organized into 'concepts' that contain terms from many sources. The terms within a concept are declared synonyms by UMLS editors. However, its use in terminology systems has limited utility for several reasons. First, UMLS concepts are created on lexically-based rules and use very little of the additional information (relationships between concepts) that may be available from the source terminology. It does not permit classification to identify cases of possible missed synonymy. Second, issues of currency occur because of dyssynchrony of release dates between source terminologies and the UMLS itself. Third, the UMLS does not support a contribution model. That is, it is a static file that cannot be amended to support additional terms that may be required to fill gaps in existing terminologies subsumed by the Metathesaurus; it does not support extensions. Lastly, there is no efficient format for sharing integrated Metathesaurus content (though there is Rich Release Format [RRF]). The UMLS is not an architecture for terminology management. It may only serve as a reference, noting the aforementioned limitations. An implementation of Tinkar may help address these limitations.
CTS2 is an architecture for terminology management that supports history retrieval, though it does not support an arbitrarily granular change set model for versioning. The Tinkar specification, in contrast, provides that every new assertion, whether a new component or a change to an existing component, must have a precise version coordinate that govern granular change control. CTS2 asserts a specific terminology model and does not support unanticipated properties with a self-describing model.
The USCDI is an amalgamation of various encoding standards. The standards being identified for specific data elements do not themselves provide consistency for how encoding is represented, how those encoding standards change over time, and how those encoding standards are distributed. As demonstrated by COVID-19 data needs, coordinated extension of content, timely distribution of updates, and consistency of representation are required to effectively respond to needs of public health and syndromic surveillance. Tinkar could help make it easier to standardize the representation, distribution, version and configuration management, and ability to share extensions to the USCDI as well as the underlying terminology systems themselves.
Tinkar is self-describing and completely machine-processed. A self-describing architecture is defined in a report from Queensland University of Technology as follows: “[t]he idea is that self-descriptions of data and other techniques would allow context-understanding programs to selectively find what users want, or for programs to work on behalf of humans and organizations to make them more scalable, efficient and productive.” [1] Key advantages of a self- describing architecture (or metadata driven architecture) [2] include the following details:
Changes can be reviewed immediately - Every action or change by end users can be immediately previewed or tested, without needing any compilation or deployment process. The review can also be done before saving or publishing the changes, which makes it an interactive development environment for designers to create functionality in an iterative manner.
Version control with easy rollback - Every time any changes are made to published terminology artifacts, the historic versions of the metadata files are maintained. This enables easy version control and rollback when necessary. Every time a change is made to any artifact, the prior version that existed is archived. When a developer needs to roll back to the prior version, it can be achieved easily.
Any data source can be added - A self-describing architecture facilitates the ability for multiple types of terminology data sources to be connected to the system.
Define granular coordinates and configuration management - The functionality for defining granular, user-defined settings and controls for granular elements of clinical terminology management is supported. This includes create, read, and append settings, as well as management of individual elements, like fields or other controls.
Faster extensions - A benefit of a self-describing architecture is that it can abstract a lot of the deep internal complexities that makes development of standard terminologies complicated. This approach can improve processes around extensions to terminology.
Increased reliance on computerized health records, including Electronic Health Records Systems, requires standardized medical terminology to encode health information consistently across systems and enterprises. Clinicians require not only objective quantitative measurements (e.g., 90 beats per minute for a patient's pulse), but also procedural context (e.g., pulse oximetry, manual) about past observations or requests for future interventions. While two quantitative measurements may be the same, the procedural information could indicate meaningful semantic differences and lead to different clinical interpretation and treatment. As information is exchanged across systems, the solution requires a common understanding of data, a method to support knowledge-representation, and clinical decision rules based on common terminology and statements. Each component must address an aspect, and together need to address the requirements of clinicians. Current HL7 standard implementations rely on profiles and templates to disambiguate statement and terminology, and provide sufficient precision for transactions, documents, and standards- based APIs. Therefore, the architectural approach described here is applicable to standards organizations developing interoperability for enterprise and project-specific implementations in equal measure.
Functional decomposition—often referred to as a Separation of Concerns (SoC)—across components or sections with a specific purpose is a foundational design principle for complex system architecture. SoC allows a complete system to be subdivided into distinct sections or components with well-defined functionality and dependencies. If successful, this approach allows individual sections to be able to be reused, as well as designed, implemented, and updated independently to address emerging requirements. This is especially useful and important in a medical context given how many different health information and clinical terminology projects are ongoing at any given time. Efforts are often uncoordinated and led by disparate and unrelated standards development organizations. In these cases, SoC allows teams to work independently, in coordination with each other, and reuse the resulting artifacts.
Separation of Concerns is an architectural design principle, whereby a system is divided into distinct sections, such that each section can address separate concerns. In this case, each architectural layer may build upon artifacts from lower layers.
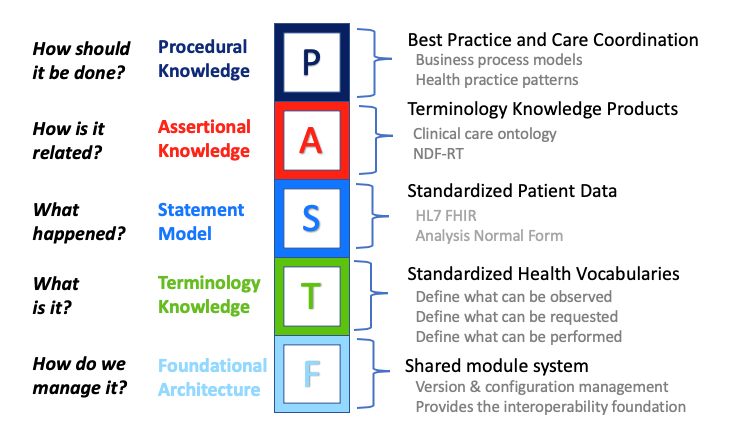
Foundational Architecture - The Foundational layer of the Knowledge Architecture provides the common elements of interoperability, such as: object identity, versioning, modularity, and knowledge representation. It includes (a) the foundation and building blocks of the common model; (b) how the repeatable transformation process of disparate standards into the common model promotes interoperability with other environments; and (c) how the modules of the architecture are tightly version controlled over time. The Tinkar Reference Model belongs in this layer.
Terminology Knowledge - The Terminology Knowledge layer is responsible for structured sets of medical terms and codes that define concepts of interest, including descriptions, dialects, language, and semantic hierarchy. SNOMED CT®, LOINC®, and RxNorm are part of this layer. It defines what valid codes or expressions may be used by higher level layers.
Statement Model - The Statement Model layer is responsible for defining how data elements are combined to create a statement. This layer reuses the artifacts defined in the Terminology Knowledge layer. The ANF Reference Model [3] belongs in this layer.
Assertional Knowledge - The Assertional Knowledge layer makes use of the Terminology Knowledge layer concepts to specify non-defining facts that may be used by procedural knowledge algorithms. An example fact might be that “thiazide diuretics treat hypertension.” Assertional Knowledge may also indicate what symptoms may be associated with a disorder.
Procedural Knowledge - The Procedural Knowledge layer, also known as imperative knowledge, is the knowledge exercised in the performance of some task. An example would be determining a hypertension treatment plan by analyzing a combination of a patient's clinical statements and the available assertional knowledge. The procedural knowledge is responsible for information about standard ways to carry out specific procedures, as well as other procedural guidelines, (e.g., treatment protocols for diseases and order sets focused on certain patient situations). Procedural knowledge, together with assertional knowledge, enables clinical decision support, quality measurement, and patient safety. This layer relies on the architectural foundation and terminology layers, incorporates the statement model for information retrieval, and uses the assertional knowledge. Procedural knowledge artifacts may include clinical alert rules, reminders, etc., that trigger actions or recommend interventions.
Examining a clinical procedure for controlling hypertension illustrates each of the layers of the informatics architectural separation of concerns.
A clear separation of concerns enables the isosemantic transformation of standards-based clinical statements to normal form in the Statement Model layer by decoupling structure from semantics and workflow.
HL7 relies on implementation guides (for V2, CDA, and FHIR) to add sufficient terminology knowledge to standards- based clinical statements. Terminology constraints documented as profiles or templates are the mechanism to create interoperable implementation guides from health IT standards. Only after the Terminology Knowledge is fully defined can the standards-based statements be used to support business and workflow decision points consistent with the Assertional and Procedural layers described above.
[1] Oaks, P. Towards Self Describing Web Services. Lecture Notes in Computer Science. 2003. 2722. 10.1007/3-540-45068-8_90. Available from: https://www.researchgate.net/ publication/27482447_Towards_Self_Describing_Web_Services.
[2] Tharakan V. Metadata Driven Architecture For Application Development. ClaySys Technologies; 2019. Available from: https://www.claysys.com/blog/metadata-driven-application-development/.
[3] Analysis Normal Form Informative Ballot. HL7 CIMI Work Group. Sept 2019. http://www.hl7.org/ documentcenter/public/ballots/2019SEP/downloads/HL7_CIMI_LM_ANF_R1_I1_2019SEP.pdf. mirror link: http:// solor.io/wp-content/uploads/2020/01/ANF-Ballot-Jan-2020.pdf.
IG © 2024+ HL7 International / Terminology Infrastructure. Package hl7.fhir.uv.termchangeset#1.0.0-ballot based on FHIR 4.0.1. Generated 2024-08-14
Links: Table of Contents |
QA Report
| Version History |
 |
Propose a change
|
Propose a change