
Terminology Change Set Exchange
1.0.0-ballot - STU1 Ballot
![]()
Terminology Change Set Exchange
1.0.0-ballot - STU1 Ballot
![]()
This page is part of the Terminology Change Set Exchange (v1.0.0-ballot: STU1 Ballot 1) based on FHIR (HL7® FHIR® Standard) R4. No current official version has been published yet. For a full list of available versions, see the Directory of published versions
| Page standards status: Informative |
Contents:
The Tinkar Reference Model is a logical model described herein using the Object Management Group (OMG) Unified Modeling Language (UML) 2.0 notation to describe the structure of integrated data representation and change management for biomedical terminologies. Tinkar provides an architecture that delivers integrated terminology to the enterprise and its information systems. In doing so, it addresses the differences in management and structure across reference terminology, local concepts, and code lists/value sets. This section describes classes of objects that support a common foundational framework for terminology and knowledge base systems (e.g., SNOMED CT®, LOINC®, RxNorm, HL7). An implementation of Tinkar can provide a single representation for all terminologies required in the U.S. and other countries, while also providing a better foundation for managing change. Tinkar could support the operation of a variety of systems intended to deliver knowledge management for terminology to vendors providers, and standards-development organizations like HL7.
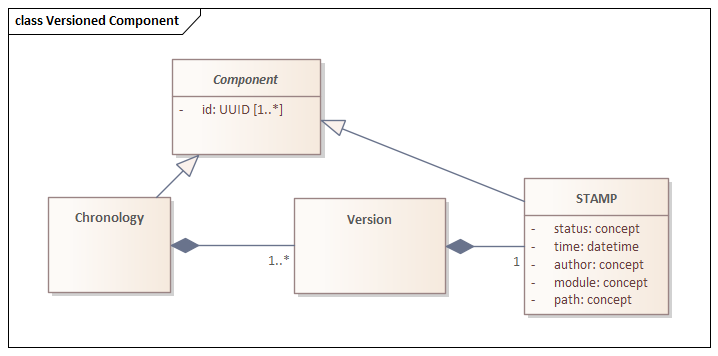
The Tinkar Reference Model fulfills the requirement of capturing a complete record of all changes, including relevant context information using versioned components as shown in the figure above. This is captured via the STAMP class using the following fields:
These elements together are referred to by the acronym “STAMP,” as described previously. Every new assertion, whether a new component or a change to an existing component, must have a STAMP to determine when it is to be used. The STAMP properties support the ability to apply terminology components for specific purposes. For example,
The Tinkar Reference Model does not merely support the ability to “STAMP” components; it asserts a requirement that all changes have a STAMP. STAMP assertions are unversioned IdentifiedComponents that are referenced by the components they scope. Since STAMP uses versioned concepts (that have a STAMP), having the STAMP as a versioned component would lead to an infinite regress.
Not all terminology systems contain all the information recorded in STAMP, but defaults can be used in cases where it is missing. For example, SNOMED CT contains the Status, Time, and Module but do not distribute the Path or Author. Since most terminologies only release a Production path, the Path could be defaulted to Production Path and the Author could be defaulted to SNOMED CT Author.
All IdentifedComponents in the knowledge base will consist of a series of change records, called ComponentVersions, (beginning with the “Create” version), all associated to an underlying ComponentChronology.
A Components Chronology only has properties attributed to it by its versions. Looking at the IdentifiedComponent through different sets of changes (published version, geographically defined set of modules, historical timestamp) may reveal substantially different IdentifedComponents.
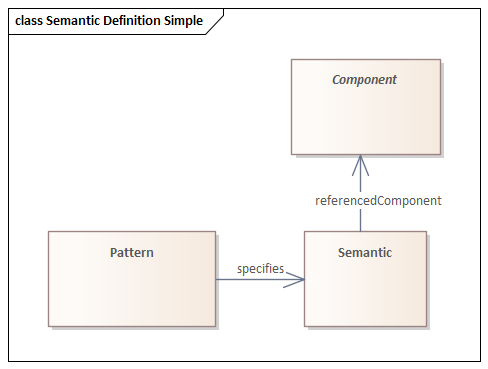
All Components in Tinkar are uniquely identified using UUIDs. A Component will be represented by an array of UUIDs with at least one UUID, but can be represented by more than one UUID in the case of a concept being derived from multiple sources as shown in the figure above. For example, the concept Acetaminophen (which exists in SNOMED CT®, LOINC, and RxNorm) could have a UUID from each terminology and be represented as an array of UUIDs for this single concept within a Tinkar implementation.
A Concept is identified using UUIDs and contains no information. To assemble groups of assertions and to provide information about Concepts, Tinkar uses a construct called a Semantic. A Semantic is a class containing a set of predicates and objects about a subject. A semantic adds meaning to the components it references, through the fields it contains as shown in the diagram below.
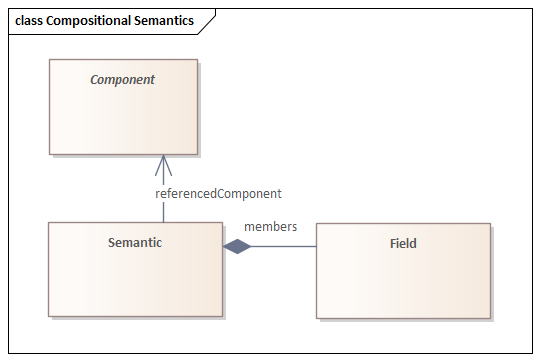
A Semantic supports the specification of value sets, compositional definitions, and other components requiring internal structure, and it specifies the nature of the compositional relationship explicitly.
The Semantic class uses a Concept to define the relationship between the value(s) and the Concept; the value itself may be either a concept or some other kind of data type, such as a string. This creates the ability to assemble assertions into more complex structures.
As discussed earlier, if an author makes a change to an IdentifiedComponent, the prior Version is unchanged, but a new version - with the appropriate STAMP information - is recorded. Users viewing the Concept and associated Semantics in the prior context (i.e., as of the prior time, if no other STAMP element has changed) will see the old values; users viewing the Concept and associated Semantics in the new context will see the new values.
Since it is versioned, a Semantic is manifested as a SemanticChronology, containing a set of SemanticVersions. SemanticVersion is a single instance of a Semantic with a STAMP, and a SemanticChronology is the set of versions having a STAMP for a Semantic. Concepts, too, are manifest as collections: a ConceptChronology consisting of a set of ConceptVersions. ConceptVersion is a single instance of an identifier for a concept with a STAMP and the ConceptChronology is the set of versions having a STAMP for a concept. A concept identifier specifies a ConceptChronology; specifying a ConceptVersion requires a rule or parameter for selecting among STAMP values.
If other IdentifiedComponents depend on the changed concept, these IdentifiedComponents can be identified by relationships in the Semantics. The Semantics can assert rules for how to manage these changes. A Semantic defining a value set for data entry might automatically accept any deactivations from the source system authority, while a Semantic defining a value set for research might automatically decline to adopt deactivations, or do so based on whether there are extant operational values. Escalating such decisions for human adjudication or review at multiple levels is also always an option. Systems might adopt any number of methods for dealing with identified changes: the important thing is to ensure the changes can be identified consistently.
Tinkar supports the following field data types for use with Semantics.
 In this output, one can see a sufficient set and necessary set. Bulleted items are properties in the
node. The output is printed as a “depth first search.” Each depth adds 3 characters of padding and
shows how OWL EL++ definitions, using only terminology and a standard property graph data structure,
are represented. The 1st one is node index 0 which has a child of node index 8. Node index 0 is the OWL
EL++ definition root. Node 8 points to Node 7, and the meaning of Node 8 is that it is a necessary set.
Node 7 is 'And' and points to Node 5,1,6. Node 5's meaning is 'Role Type', Value is 'Role group', and
its other property is 'Role Operator.' Node 5 points to Node 4. Node 4 is 'And.' Node 3 is 'Role Type.'
Node 2 is Concept Reference. 7 also points to 1 and 6 (Concept References).
In this output, one can see a sufficient set and necessary set. Bulleted items are properties in the
node. The output is printed as a “depth first search.” Each depth adds 3 characters of padding and
shows how OWL EL++ definitions, using only terminology and a standard property graph data structure,
are represented. The 1st one is node index 0 which has a child of node index 8. Node index 0 is the OWL
EL++ definition root. Node 8 points to Node 7, and the meaning of Node 8 is that it is a necessary set.
Node 7 is 'And' and points to Node 5,1,6. Node 5's meaning is 'Role Type', Value is 'Role group', and
its other property is 'Role Operator.' Node 5 points to Node 4. Node 4 is 'And.' Node 3 is 'Role Type.'
Node 2 is Concept Reference. 7 also points to 1 and 6 (Concept References).
The Tinkar Reference Model defines a first-class feature of the model, the Pattern (PatternVersion and PatternChronology) as shown in the figure below.
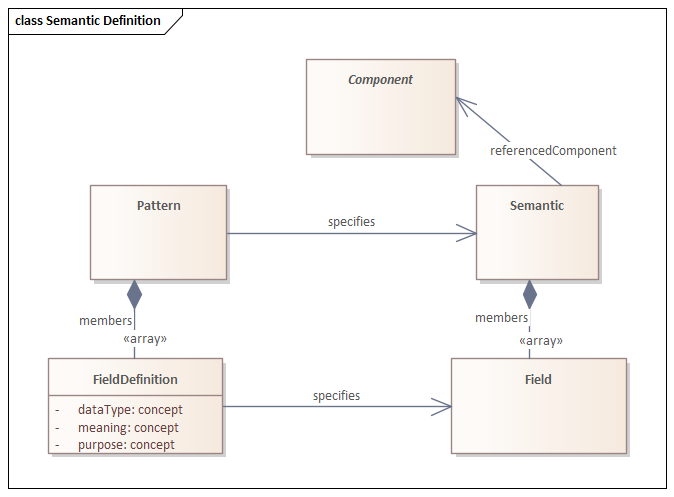
A Pattern is a class defining a set of predicates and object types that can be asserted about a class of subjects. All Semantics follow Patterns. A PatternVersion is a single instance of a pattern with a STAMP and a PatternChronology is the set of versions having a STAMP for a pattern. This feature asserts patterns that Semantic components can follow, like an XML or RDF Schema.
Using the Pattern, Semantics with varying fields and data types can be specified to represent any structure needed to provide meaning to a concept. For example, if a field within a semantic is used to describe an SDO's website, the Meaning would be “URL,” DataType of “String,” and Purpose of “Website.” The Pattern would then contain an array of these FieldDefinitions.
The full Tinkar Architecture is shown below, followed by a description of each of the classes referenced in that architecture.
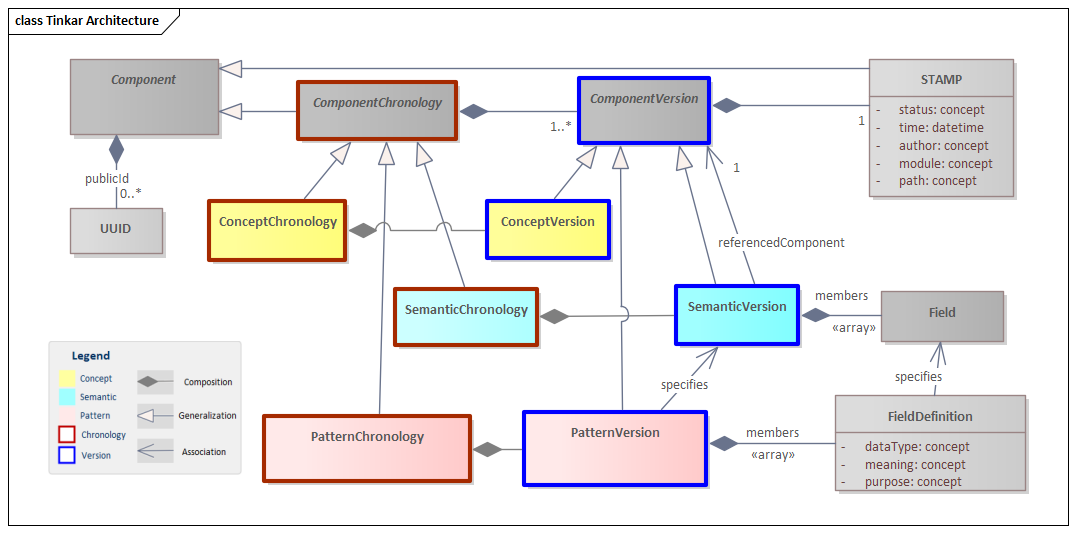

The Tinkar Reference Model supports and encourages the storage of time series data that utilizes multiple coordinates, for example, STAMP, Language, Dialect, clinical domains, etc. The ability to efficiently search, display, and navigate concepts and semantics requires the ability to calculate combinations of content based on one or more of these different coordinates.
In order to facilitate the computability of various, complex coordinates, including time series data, a graph structure is commonly used in software versioned control systems. A particular type of graph structure that is commonly used is a “version graph,” such as a directed acyclic graph. A version graph would enable a Tinkar implementation to recover the state of the graph at a particular point in time. Most graph databases do not support versioning as a first-class concept. It is possible, however, to create a versioning scheme inside the graph model whereby nodes and relationships are timestamped and archived whenever they are modified. The downside of such versioning schemes is that they leak into any queries written against the graph, adding a layer of complexity to even the simplest query.
Types of Coordinates:
As the Tinkar specification evolves towards a DSTU and Connectathons, more coordinates and detailing will be provided.
The ComponentChronology contains all the versions of a component from the date it was instantiated until the most recent version. Components only get a new version whenever something about the component changes. To calculate the latest version requires the ability to find the most recent version of each component. Utilizing the STAMP Coordinates supports calculating all other coordinates:
After the STAMP Coordinates have been calculated, additional coordinates can then be applied as well. For example, applying a language and dialect coordinate will be important not only for viewing and searching, but also to determine the appropriate preferred name for displaying a hierarchy.
| Fully Qualified Name | Definition | Origin |
|---|---|---|
| Acceptable (foundation metadata concept) | Specifies that a description is acceptable, but not preferred within a language or dialect. | DESCRIPTION_ACCEPTABILITY |
| Active status | Concept used to represent a status for components that are active. | STATUS_VALUE |
| Author | ROOT_VERTEX | |
| Canceled status | Concept used to represent a status for components that are canceled | STATUS_VALUE |
| Chinese Language | A concept representing the Chinese Language | LANGUAGE |
| Component field | A display field type that references a concept ID. | DISPLAY_FIELDS |
| Component Id list | A display field that references an ordered list of Concept IDs. | DISPLAY_FIELDS |
| Component Id set field | A display field that references an unordered list of Concept IDs. | DISPLAY_FIELDS |
| Concept Reference | The concept referred to by the is_a axiom relationship or the axiom role relationship. | IS_A; ROLE |
| Czech Language | A concept representing the Czech Language. | LANGUAGE |
| Danish Language | A concept representing the Danish Language. | LANGUAGE |
| Definition description type | Semantic value describing the description type for the description pattern is a definition | DESCRIPTION_TYPE |
| Description | Human readable text for a concept | MODEL_CONCEPT |
| Description acceptability | Whether a given human readable text for a concept is permissible | MODEL_CONCEPT |
| Description case sensitive | Assumes the description is dependent on capitalization | DESCRIPTION_CASE_SIGNIFICANCE |
| Description case significance | Specifies how to handle the description text interms of case sensitivity | MODEL_CONCEPT |
| Description not case sensitive | Value which designate character as not sensitive for a given description | DESCRIPTION_CASE_SIGNIFICANCE |
| Description semantic | Purpose and meaning for the description pattern and dialect patterns | MODEL_CONCEPT |
| Description type | Specifying what type of description it is i.e. is it fully qualified or regular and etc. | MODEL_CONCEPT |
| Development path | A path that specifies that the components are currently under development | PATH |
| Dialect | Specifies the dialect of the language. | MODEL_CONCEPT |
| DiGraph field | A display field that references a di-graph whose edges are ordered pairs of vertices. Each edge can be followed from one vertex to another vertex. | DISPLAY_FIELDS |
| Display Fields | Captures the human readable terms | MODEL_CONCEPT |
| DiTree field | A display field that references a graph obtained from an undirected tree by replacing each undirected edge by two directed edges with opposite directions. | DISPLAY_FIELDS |
| Dutch Language | A concept representing the Dutch Language. | LANGUAGE |
| EL++ Inferred terminological axioms | MODEL_CONCEPT | |
| EL++ Stated terminological axioms | MODEL_CONCEPT | |
| English Dialect | Specifies the dialect of theEnglish language | DIALECT |
| English Language | A concept representing the English Language. | LANGUAGE |
| Existential restriction | Existential restrictions describe objects that participate in at least one relationship along a specified property to objects of a specified class. | ROLE_OPERATOR |
| Float field | Represents values as high-precision fractional values. | DISPLAY_FIELDS |
| French Language | A concept representing the French Language. | LANGUAGE |
| Fully qualified name description type | Fully qualified name is a description that uniquely identifies and differentiates it from other concepts with similar descriptions | DESCRIPTION_TYPE |
| German Language | A concept representing the German Language. | LANGUAGE |
| Great Britian English dialect | Great Britain: English Langauge reference set | ENGLISH_DIALECT |
| Identifier Source | An identifier used to label the source of the identity of a unique component. | MODEL_CONCEPT |
| Identifier Value | The literal string value identifier | MODEL_CONCEPT |
| Implication Set | A set of relationships that indicate something has an implication. Not necessarily or sufficient but implicated. | EL_PLUS_PLUS_STATED_TERMINOLOGICAL_AXIOMS; EL_PLUS_PLUS_INFERRED_TERMINOLOGICAL_AXIOMS |
| Inactive Status | Concept used to represent a status for components that are no longer active | STATUS_VALUE |
| Inferred Navigation | The origins and destinations for concepts based on the reasoner generated inferred terminological axioms | MODEL_CONCEPT |
| Integer Field | data type that represents some range of mathematical integers | DISPLAY_FIELDS |
| Integrated Knowledge Management | The Root Vertex | |
| Irish Language | A concept representing the Irish Language. | LANGUAGE |
| Is-a | Designates the parent child relationship | MODEL_CONCEPT |
| Italian Language | A concept representing the Italian Language. | LANGUAGE |
| Korean Language | A concept representing the Korean Language. | LANGUAGE |
| Language | Specifies the language of the description text. | MODEL_CONCEPT |
| Language for Description | The semantic value indicating which language is used in the description text | MODEL_CONCEPT |
| Lithuanian Language | A concept representing the Korean Language. | LANGUAGE |
| Logical Definition | The semantic value describing the purpose of the stated and inferred terminological axioms. | MODEL_CONCEPT |
| Master path | A default path “branch” for components. This path represents those finalized or published components in production | PATH |
| Meaning | The interpretation or explanation field for a pattern/semantics | MODEL_CONCEPT |
| Model concept | ROOT_VERTEX | |
| Module | A module is identified by a concept and may be annotated with additional information such as organizing content for maintenance and publication purposes. | ROOT_VERTEX |
| Necessary set | A set of relationships that is always true of a concept. A concept that only contains necessary conditions is considered primitive | EL_PLUS_PLUS_STATED_TERMINOLOGICAL_AXIOMS; EL_PLUS_PLUS_INFERRED_TERMINOLOGICAL_AXIOMS |
| Path | A set of assets under version control that can be managed distinctly from other assets. Paths “branch” from other paths when established, and can be “merged” with other paths as well. | ROOT_VERTEX |
| Polish Language | A concept representing the Polish Language. | LANGUAGE |
| Preferred | Specifies that a description is preferred within a language or dialect. There will be one preferred description for each description type. | DESCRIPTION_ACCEPTABILITY |
| Primordial module | MODULE | |
| Prerequisite path | A path that contains components that are shared across all paths and contain infrastructure components. | PATH |
| Premundane status | Concept used to represent a status for components that have not yet been released and exist in their most basic form. | STATUS_VALUE |
| Purpose | The reason for which a Tinkar value in a pattern was created or for which it exist. | MODEL_CONCEPT |
| Regular name description type | There may be descriptions/synonyms marked as “regular.” | DESCRIPTION_TYPE |
| Relationship destination | Signifies path to child concepts which are more specific than the Tinkar term | MODEL_CONCEPT |
| Relationship origin | Signifies path to parent concepts which are more general than the Tinkar term | MODEL_CONCEPT |
| Role | Is an abstract representation of a high-level role for a therapeutic medicinal product; the concepts are not intended to describe a detailed indication for therapeutic use nor imply that therapeutic use is appropriate in all clinical situations. | ROLE_GROUP; EL_PLUS_PLUS_STATED_TERMINOLOGICAL_AXIOMS; EL_PLUS_PLUS_INFERRED_TERMINOLOGICAL_AXIOMS |
| Role group | An association between a set of attribute or axiom value pairs that causes them to be considered together within a concept definition or postcoordinated expression. | EL_PLUS_PLUS_STATED_TERMINOLOGICAL_AXIOMS; EL_PLUS_PLUS_INFERRED_TERMINOLOGICAL_AXIOMS |
| Role operator | Concept that is used to describe universal vs existential restrictions. | ROLE_GROUP |
| Role type | Refers to a concept that represents a particular kind of realtionship that can exist between two entities. It defines the specific function or responsibility that one entity plays in relation to another. | ROLE |
| Russian Language | A concept representing the Russian Language. | LANGUAGE |
| Sandbox path | A path for components under testing. | PATH |
| Spanish Language | A concept representing the Spanish Language. | LANGUAGE |
| Stated Navigation | The origins and destinations for concepts based on the reasoner generated stated terminological axioms | MODEL_CONCEPT |
| Status value | The status of the STAMP Coordinate(Active, Cancelled, Inactive, Primordial) | ROOT_VERTEX |
| String Field | a sequence of characters, either as a literal constant or as a variable. Strings could be used to represent terms from code systems or URLs, textual definitions, etc. | DISPLAY_FIELDS |
| Sufficient set | A set of relationships that differentiate a concept and its subtypes from all other concepts. A concept that contains at least one set of necessary and sufficient conditions is considered defined. | EL_PLUS_PLUS_STATED_TERMINOLOGICAL_AXIOMS; EL_PLUS_PLUS_INFERRED_TERMINOLOGICAL_AXIOMS |
| Swedish Language | A concept representing the Swedish Language. | LANGUAGE |
| Text for description | Captures the human readable text for a description in Komet | MODEL_CONCEPT |
| United States of America English dialect | Particular form of language specific form of English language, particular to US | ENGLISH_DIALECT; US_DIALECT_PATTERN |
| Universal Restriction | Universal restrictions constrain the relationships along a given property to concepts that are members of a specific class. | ROLE_OPERATOR |
| UNIVERSALLY_UNIQUE_IDENTIFIER | A universally unique identifier that uniquely represents a concept in Tinkar | IDENTIFIER_SOURCE |
| User | AUTHOR | |
| Withdrawn status | Concept used to represent a status for components that are withdrawn. | STATUS_VALUE |
[15] Abstract syntax tree. Wikipedia; 2020. Available from: https://en.wikipedia.org/wiki/Abstract_syntax_tree.
IG © 2024+ HL7 International / Terminology Infrastructure. Package hl7.fhir.uv.termchangeset#1.0.0-ballot based on FHIR 4.0.1. Generated 2024-08-14
Links: Table of Contents |
QA Report
| Version History |
 |
Propose a change
|
Propose a change