
FHIR for FAIR - FHIR Implementation Guide
0.1.0 - STU 1 Ballot
FHIR for FAIR - FHIR Implementation Guide
0.1.0 - STU 1 Ballot
This page is part of the FHIR for FAIR - FHIR Implementation Guide (v0.1.0: STU 1 (FHIR R4b) Ballot 1) based on FHIR v4.1.0. The current version which supercedes this version is 1.0.0. For a full list of available versions, see the Directory of published versions 
The MIMIC-IV-ED (MIMIC-ED) (https://physionet.org/content/mimic-iv-ed/1.0/) dataset is a module of the MIMIC-IV (https://physionet.org/content/mimiciv/0.4/) dataset, the latter of which is published in August 2020 and contains clinical data on hospital stays sourced from hospital information systems. MIMIC-ED, published in June 2021, contains emergency department (ED) admissions at the Beth Israel Deaconess Medical Center (Boston, MA, USA) between 2011 and 2019. At the time of writing, version 1.0 of MIMIC-ED contains de-identified data from 448,972 ED stays. The dataset is made available freely via PhysioNet (https://physionet.org/), a repository for medical research data, and is intended for both research and educational purposes.
MIMIC-ED follows a star-like structure (Figure 1) around the edstays table, which contains two identifiers through which the other tables are linked (subject_id referring to a patient and stay_id referring to an ED stay of a patient). The other five tables contain information that was documented during a patient’s stay at the ED: discharge diagnoses (diagnosis), medication taken prior to the ED stay (medrecon), medication dispensed during the ED stay (pyxis), information collected at the time of triage (triage), and aperiodic vital signs measured during the ED stay (vitalsign). A description of each table and its elements, including background, license, access, and citation information is provided through the MIMIC-ED page at PhysioNet.
Data (ZIP file, when access is provided): https://physionet.org/content/mimic-iv-ed/get-zip/1.0/
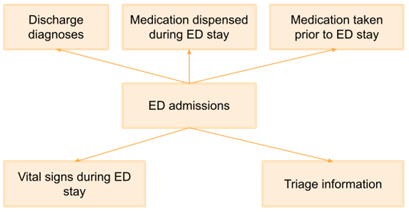
Figure 1. MIMIC-ED table structure.
MIMIC-ED can be used for educational and research purposes. PhysioNet distributes the data to its credentialed users that, after signing a data use agreement, can download the raw data (CSV) and/or access the data through services such as the Google Cloud Platform. The objective of this exercise is to create an HL7 FHIR version of MIMIC-ED and assess the data FAIRness before and after implementing HL7 FHIR. For the FAIRness assessment, we use the RDA FAIR Data Maturity Indicators. By doing so, we can 1) contribute to the MIMIC-ED community by creating an HL7 FHIR model of the data and providing an exemplar implementation of an HL7 FHIR server that can serve MIMIC-ED data, and 2) showing what parts of FAIR can be addressed in this particular case when using HL7 FHIR. The lessons learned can be used for other cases where the implementation of the FAIR principles using HL7 FHIR is desirable.
We assessed the FAIRness of MIMIC-ED before the implementation of HL7 FHIR. In other words, the FAIRness of MIMIC-ED as it is being distributed by PhysioNet. In summary, MIMIC-ED passed most (except one) indicators for Findability and Accessibility. The one indicator that it did not pass is the requirement for metadata to be available when the data is no longer available, we can assume this is true but it has not been specified by PhysioNet. When we look at Interoperability and Reusability we can see a clear use case for using HL7 FHIR. MIMIC-ED does not use any FAIR-compliant vocabularies for annotating its data semantics, nor does it comply with a standard data model. Hence, implementing HL7 FHIR would probably contribute to the Interoperability and Reusability aspects of FAIR in the case of MIMIC-ED.
Table 1. FAIRness assessment of MIMIC-ED before implementing HL7 FHIR.
| Findable | Accessible | Interoperable | Reusable | |
|---|---|---|---|---|
| Passed RDA indicators | 7 / 7 Fully implemented |
11 / 12 Fully implemented |
7 / 12 Partly implemented |
2 / 10 Not/partly implemented |
| Positives |
|
|
|
|
| Negatives |
|
|
|
By using HL7 FHIR we want to improve the machine-readability/interoperability/FAIRness of the MIMIC-ED dataset. We took the following steps.
Model the data and metadata conforming the HL7 FHIR data model (using the Patient, Encounter, Condition, MedicationStatement, MedicationDispense, Observation, and Procedure resources)
Set up an HL7 FHIR facade server that can serve the (meta)data via the HL7 FHIR REST API
Enable SEARCH operations that allow queries such as “retrieve all ED stays of patient X” or “which patients were discharged from the ED with diagnose Y”

Figure 2. Exemplar implementation of an HL7 FHIR facade for serving MIMIC-ED data.
We assessed the FAIRness of MIMIC-ED again after modeling the (meta)data as HL7 FHIR resources and setting up an HL7 FHIR facade server. The goal of this assessment is to help identify where HL7 FHIR improves or does not improve FAIRness, and to formulate best practices and lessons learned. Important note: the indicators RDA-I3-02M and RDA-I3-02D ((meta)data includes (qualified) references to other data) were considered to be ‘not applicable’ for the post assessment, as those were not implemented despite that HL7 FHIR provides the tools to satisfy these indicators.
Table 2. FAIRness assessment of MIMIC-ED after implementing HL7 FHIR.
| Findable | Accessible | Interoperable | Reusable | |
|---|---|---|---|---|
| Passed RDA indicators | 5 / 7 Partly implemented |
8 / 12 Partly implemented |
11 / 12 Partly implemented |
5 / 10 Partly implemented |
| Positives |
|
|
|
|
| Negatives |
|
|
|
|
Overall, using HL7 FHIR for expressing and distributing the data in MIMIC-ED improves the interoperability and reusability and poses some extra challenges in terms of findability and accessibility. Findability requires ample metadata that is offered in such a way that it can be harvested and indexed. Some of the metadata that PhysioNet publishes for MIMIC-ED became redundant, as all HL7 FHIR resources are self-descriptive. For instance, when using a MedicationStatement resource it is not necessary to seperately describe that there is data about medication consumed by a patient, as this information is captured in the definition and scope of the resource. Other metadata, such as author information, provenance, license, and access information, have to be captured in separete resources such as Library. Metadata discoverability in challenging when only using HL7 FHIR, as details on how to reach an HL7 FHIR server should be published outside of that server anyway. Hence, it is recommended to keep an indexable, publicly available, page to expose such metadata. The PhysioNet repository is a good example here. Such a page would also be necessary to satisfy indicators RDA-A1-02M and RDA-A1-02D (manual access to (meta)data). In short:
To satisfy indicator RDA-F4-01M (metadata discoverability), using a separate public repository for certain metadata is recommended.
Some metadata is captured in resources used for the data (e.g., Patient or Observation) while other resources are used specifically for metadata (e.g., Library).
HL7 FHIR improves interoperability by providing a (meta)data model, machine-readible representations, and REST API. Modeling MIMIC-ED using HL7 FHIR resources was relatively easy to do.
HL7 FHIR does not solve the lack of a standard licence, references to other (meta)data, or provenance data. However, once present those data can be modeled and exposed with HL7 FHIR.
IG © 2020+ Health Level Seven International - SOA Work Group. Package hl7.fhir.uv.fhir-for-fair#0.1.0 based on FHIR 4.1.0. Generated 2021-12-05
Links: Table of Contents |
QA Report
| Version History |
Search |
 |
Propose a change
|
Propose a change