 . Page versions: R5 R4B R4 R3 R2
. Page versions: R5 R4B R4 R3 R2This page is part of the FHIR Specification (v0.01: Historical Archive Draft). The current version which supercedes this version is 5.0.0. For a full list of available versions, see the Directory of published versions . Page versions: R5 R4B R4 R3 R2
In this specification, resources are described in a simple XML format. This page documents how the XML content for resources is described and controlled. The XML may be validated by schema, and schemas are provided, but validation is not required in operational systems (though the XML must always be valid against this specification). In addition, W3C Schema and UML models are provided that may be a useful aid for system implementation.
All the content model definitions provided in this specification follow the same general pattern:
<name xmlns="...">
<nameA> opt type description of content <nameA>
<nameB> mand type Zero+ description </nameB>
<nameC> <!-- One+ -->
<nameD mand type="?">Relevant records </nameD>
</nameC>
<name>
Notes:
Every resource contains the following common elements:
<[Name] xmlns="http://www.hl7.org/fhir"> <id> mand id Master Resource Id, always first. Never changes after creation</id> <extensions> opt See Extensions </extensions> <text> mand Narrative Text summary of resource, for human interpretation</text> </[Name]>
The id element is always mandatory except in the case that a resource is posted to a server to create it, and the id of the resource is not yet known. In this case, the id element is absent. The use of the id element is discussed further below. The use of the extensions element is discussed under "Extensibility". The text ("Narrative") is discussed below. In addition to these data elements, there are several pieces of metadata about a resource that are not part of the resource content, but are delegated to the infrastructure:
| Metadata Item | Type | Usage |
|---|---|---|
| Version Id | id | Changed each time the content of the resource changes. Can be referenced in a resource reference (see below). Can be used to ensure that updates are based on the latest version of the resource |
| Last Modified Date | dateTime | Change each time the content of the resource changes. Can be used by a system or a human to judge the currency of the resource content |
| Master Location | uri | Reports the location of the master for the resource. Useful when a resource is re-used by another system - it can report the location of the master should any system need to know this. |
In any environment where the resources are used, the technical details of the delegation will have to be resolved. For further details, see Implementation Details.
Data Quality - or the lack thereof- is a ubiquitious issue in healthcare. In order to handle this, every element defined as part of a resource data structure may have a dataAbsentReason attribute, which is used to specify why the normally expected content of the data element is missing.
<x dataAbsentReason=""/>
The dataAbsentReason attribute can have one of the following values:
| unknown | The value is not known |
| asked | The source human does not know the value |
| temp | There is reason to expect (from the workflow) that the value may become known |
| notasked | The workflow didn't lead to this value being known |
| masked | The information is not available due to security, privacy or related reasons |
| unsupported | The source system wasn't capable of supporting this element |
| astext | The content of the data is represented as text (see below) |
| error | Some system or workflow process error means that the information is not available |
Notes:
Every element has a control flags which is used to control the degree to which missing or poor quality data is tolerated on a per element basis. The control flag must have one of the following values:
| mand | The element must be present, and must be populated with correct data. i.e. Resource.id. No dataAbsentReason is allowed. |
| req | The element must be present, but may have a dataAbsentReason (todo: when would this be used?) |
| cond | The element may not be present, but if it is, may not have a dataAbsentReason. The condition must be explained in the notes that follow the definition |
| opt | The element doesn't have to be present. If it is present, it might have a dataAbsentReason. If the normal structure can be replaced with text, it might be. |
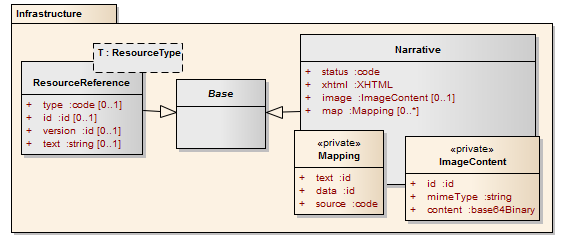
Every resource includes a human readable narrative that contains a summary of the resource, and may be used to represent the content of the resource to a human. The narrative need not encode all the structured data, but is required to contain sufficient detail to make it "clinically safe" for a human to just read the narrative. Each resource will define what content must be represented in the narrative to ensure clinical safety
The narrative for a resource is allowed to contain additional information that is not in the structured data, including human edited content. Such additional information must be in the scope of the definition of the resource.
Each narrative has a flag that specifies the relationship of the narrative from the structured data, which may have one of the following codes:
| generated | The contents of the narrative are entirely generated from the structured data in the resource. |
| extensions | The contents of the narrative are entirely generated from the structured data in the resource, and some of the structured data is contained in extensions |
| additional | The contents of the narrative contain additional information not found in the structured data |
In addition to this general flag that specifies the status of the narrative, there is an optional mapping between the narrative and the structured data. Each mapping has narrative id, and structured data id which map to xml:id attributes found in the narrative and the structured data respectively, and a flag for whether the text was generated from the data, or the data was generated from the text (by some form of retrospective processing, whether human or computer), or whether both come from an external source. The structured data target may be an empty element with a dataAbsentReason of "astext"; this means that the value of the text could not be properly represented in the data type. Any element defined as part of the resource content, or any repeating element inside a data type, may carry an id attribute to serve as the target of a narrative mapping. When using xml:id attributes, the comments in the aggregation section about the value of the xml:id attribute should be kept in mind.
The narrative is an xhtml fragment that also includes images if appropriate:
<x xmlns="http://www.hl7.org/fhir"> <status> cond code generated | extensions | additional</status> <div xmlns="http://www.w3.org/1999/xhtml"mand limited xhtml content</div> <image> opt <!-- Zero+ --> <mimeType> mand code mime type of image</mimeType> <content> mand base64Binary base64 image data</content> </image> <map> opt <!-- Zero+ --> <text> mand xml:ID Narrative source (xml:id)</text> <data> mand xml:ID Data source (xml:id)</data> <source> mand code text | data</source> </map> </x>
Terminology Bindings
| generated | The contents of the narrative are entirely generated from the structured data in the resource. | |
| extensions | The contents of the narrative are entirely generated from the structured data in the resource, and some of the structured data is contained in extensions | |
| additional | The contents of the narrative contain additional information not found in the structured data | |
| text | The text is the original data | |
| data | The data is the original data | |
The status is required when the narrative is the full resource narrative, but not required in resource references (see below).
The contents of the xhtml element are an XHTML fragment containing only the basic html formatting elements described in chapters 7-11 (except section 4 of chapter 9) and 15 of the HTML 4.0 standard, <a> elements (either name or href), images, and internally contained stylesheets. The XHTML content may not contain a head, a body element, external stylesheet references, scripts, forms, base/link/xlink, frames, iframes, and objects. Technically, the content of the text element is a union of the XHTML Schema types "block", and "inline", with the additional rules above applied.
<narrative>
<div xmlns="http://www.w3.org/1999/xhtml">This is a simple
example with only plain text</div>
</narrative>
<narrative>
<div xmlns="http://www.w3.org/1999/xhtml">
<p>
This is an <i>example</i> with some <b>xhtml</b> formatting.
</p>
</div>
<narrative>
An additional address scheme is defined for use within the xhtml for image location:
<img src="fhir:#45"/>
This is a reference to an id attribute on an element in the same resource, either in the image attachments on the text element directly, or an element of type "Attachment".
<narrative>
<html xmlns="http://www.w3.org/1999/xhtml">
<p>
<img src="fhir:#a1/>.
</p>
</html>
<image id="a1">
<mimeType>image/png</mimeType>
<data>MEKH....SD/Z</data>
</image>
<narrative>
Applications processing the html should always be able to strip external images (images not using the alternative "fhir" scheme above), and still be able to present the information correctly to a human reader (since these images are not part of the resource, their presence cannot be assured). Additionally, applications processing the html should always be able to strip the HTML tags completely (correcting for implicit paragraph elements such as headers) and still be clinically safe (so where internal images are used, they must include an appropriate caption).
The dataAbsentReason is not used on the narrative element, or any elements contained in it. The xhtml element must have some non-whitespace content.
The "Resource" type indicates a reference from one resource to another. Since each resource is identified by a master id that never changes (a different id implies a different resource), references are done by id.
<x>
<type> cond ResourceType Resource Type</type>
<id> cond id Id of the reference</id>
<version> opt id Specific version Id of resource referenced</version>
<text> opt string Text alternative for the resource</text>
</x>
The resourceType type is the name of one of the resources defined in this specification, such as "Patient". Whether or not the type of the resource is fixed for a particular element, the reference includes the resource type (this is to assist with future prooting the specification).
A specific version of the resource may be referenced by specifying a version Id in addition to the resource identifier. The version identifier is only known to be unique in the context of a given resource, so the resource Id is always required. Note that locating and retrieving a particular version of a resource is implementation specific, like accessing the latest version of the resource.
<id>
<type>Patient</type>
<id>034AB16</id>
<id>
The id type can take one of the following forms:
| A whole number in the range 0 to 2^64-1. May be represented in hex | |
| A uuid (guid) (in lowercase, without wrapping with the characters "{}[]" which sometimes occur) | |
| An ISO OID (reference) | |
| Any other combination of letters, numerals, "-" and "." | |
Resource ids must be represented in lowercase. Ids are always opaque, and systems should not and need not attempt to determine their internal structure. However the id is represented, it must always be represented in the same way in resource references and URLs.
Some narrative may be provided that describes the resource in addition to the resource reference (or in place of, unless the resource reference is mandatory).
<id>
<type>Organisation</type>
<id>1234</id>
<text>HL7, Inc</text>
<id>
Use
Unless the resource reference element has a dataAbsentReason flag, it must contain a valid type and id, or, if it is not mandatory, a text alternative.
There is no explicit version marker in the XML. Subsequent versions of this specification may introduce new elements at any point in the content models, but the path or meaning of existing data elements will not be changed.
Given that in a typical scenario, mixed versions may need to exist, applications would best ignore elements that they do not recognize. However in a healthcare context, many application vendors are unwilling to consider this approach because of concerns about clinical risk. Applications are not required to ignore unknown elements, but must declare whether they will do so in their conformance statements.
This specification provides schema definitions for all the content models described here. The base schema is called "fhir-base.xsd" and defines all the datatypes and also the base infrastructure types described on this page. In addition, there is a schema for each resource, and a common schema fhir-all.xsd that includes all the resource schemas.
XML that is exchanged must be valid against the schema, though there is no requirement to validate instances against the schema, nor is being valid against the schema sufficient to be a conformant instance (this specification makes many rules that cannot be checked by schema). Exchanged content must not specify the schema or even the schema instance namespace in the resource XML.
Should schema based validation or code generation be of interest, applications can define their own schemas that more closely match the working content mode given their conformance statement. These schemas can eliminate elements not used by the application, and explicitly define extensions that are used. However the xml format they describe must be consistent with the XML and rules defined in this specification.
Though the formal representation of the resources is in XML, many systems wish to use JSON to exchange the resources, and it is useful to standardise a single JSON format for this use. The JSON format for the resources follows the standard XML format closely:
<name xmlns="...">
<nameA> opt type description of content <nameA>
<nameB> mand type Zero+ description </nameB>
<nameC> <!-- One+ -->
<nameD mand type="?">Relevant records </nameD>
</nameC>
<name>
is represented in JSON as
{"name":
"nameA" : {...},
"nameB" :
[
{...},
{...}
],
"nameC" :
[
{ "nameD" : {...} }
}
}
Notes:
In addition to the schema, this specification also provides object models defined in UML that may be of assistance in defining systems that work with the resources defined here.
Although the UML models provided express the same contents as the xml formats, because of the wide variation in how different architectures and tools map from UML to XML, there should be no expectation that any particular tool will produce compatible XML from these UML diagrams. Systems are welcome to use these object models as a basis for serialization internally, or even between trading partner systems, with any form of exchange technology (including JSON). Systems that use this form of exchange cannot claim to be conformant with this specification, but can describe themselves as using "FHIR consistent object models".
 This is an old version of FHIR retained for archive purposes. Do not use for anything else
This is an old version of FHIR retained for archive purposes. Do not use for anything else
Implementers are welcome to experiment with the content defined here, but should note that the contents are subject to change without prior notice.
© HL7.org 2011 - 2012. FHIR v0.01 generated on Mon, May 14, 2012 09:48+1000.