
MedMorph Research Data Exchange Content IG
0.1.0 - STU 1 Ballot
MedMorph Research Data Exchange Content IG
0.1.0 - STU 1 Ballot
This page is part of the Making EHR Data MOre available for Research and Public Health (MedMorph) Research Content IG (v0.1.0: STU 1 Ballot 1) based on FHIR (HL7® FHIR® Standard) R4. No current official version has been published yet. For a full list of available versions, see the Directory of published versions
The section identifies the business needs and specific user stories outlining the research data exchange needs.
User Story #1: As a research network administrator, there is a need to on-board research data partners to join the research network and contribute data that can be used for research. The data partners extract, transform and load the data from data sources such as EHRs, HIEs, Other data respositories. The current processes used to extract, transform, load the data and then contribute the data involve many non-standardized mechanisms (e.g SFTP, Excel Files, Stored procedures), different structures (formats) and different semantics. As a result of these non-standardized processes, the length of time to on-board a data partner varies from weeks to months. These processes (extraction, transformation and loading) when standardized will expedite on-boarding processes and deliver better quality data at a lower cost.
User Story #2: Once a data partner joins a research network and contributes data, a researcher should be able to perform queries to filter specific data sets and analyze the data to improve treatments and outcomes. Currently researchers are able to query data marts on a limited basis because of the variations in the data models (e.g., PCORnet CDM, i2b2, OMOP, FHIR Resources) and the technologies (e.g., Microsoft SQL, Postgres SQL, SAS, etc.) used to host the data mart. Standardizing these data access mechanisms will help overcome the hurdles faced by researchers in accessing data from data partners and EHRs.
The focus of the MedMorph Research Content IG is User Story #1. This is based on extensive discussions with the PCORnet Front Door team, the MedMorph RA WG and the CDC MedMorph team. The reasons for choosing User Story #1 is as follows
The current state is as shown in the Figure below:
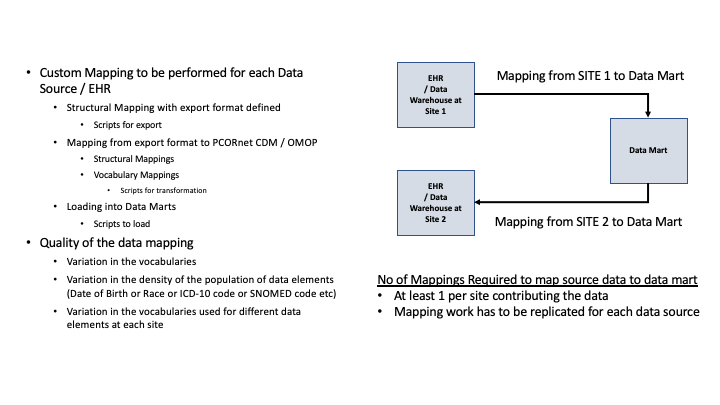
The usage of FHIR during the on-boarding process and expected efficiencies are documented below
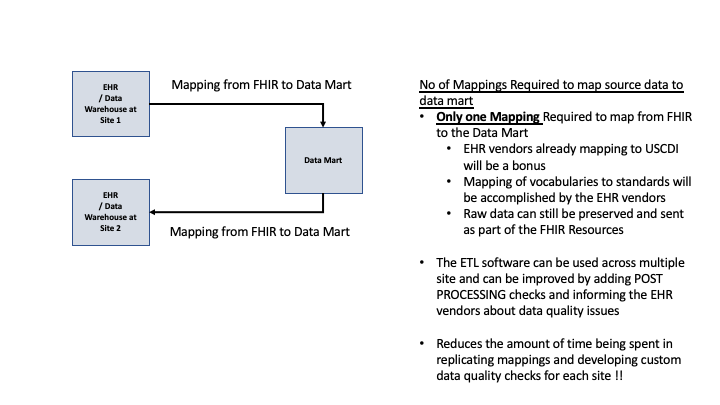
Figure 2.3 below shows the research abstract model to onboard a data partner who can contribute data from their EHR system to populate a data mart.

As shown in Figure 2.3 above, the Backend Service App will extract data from an EHR for one or more patients and use the Data/Trust Services to perform translation, masking and populate the data mart. In the above diagram the data mart exists within the health care organization. The Data Mart and the Backend Service App could reside outside the health care organization as shown in Figure 2.4 below.

This section defines the Actors and Systems that interact within the MedMorph Reference Architecture to realize the capabilities of the use cases listed above.
Electronic Health Record (EHR): A system used in care delivery for patients and that captures and stores data about patients and makes the information available instantly and securely to authorized users. While an EHR does contain the medical and treatment histories of patients, an EHR system is built to go beyond standard clinical data collected in a provider’s provision of care location and can be inclusive of a broader view of a patient’s care. EHRs are a vital part of health IT and can:
A FHIR Enabled EHR exposes FHIR APIs for other systems to interact with the EHR and exchange data. FHIR APIs provide well defined mechanisms to read and write data. The FHIR APIs are protected by an Authorization Server which authenticates and authorizes users or systems prior to accessing the data.
Data Mart: Data Mart represents a system that will hold data that is to be accessed by researchers. Typically researchers do not access the EHR or operational data stores directly as they are used for clinical operations. In order to facilitate access to researchers healthcare organizations populate data stores that can be accessed by researchers. These data stores are called Data Marts in our abstract model. Typically these data stores are present within the healthcare organization, but could also be hosted externally to the healthcare organization. The data models that are used to store the data may depend on the types of research studies. The following are the commonly used data models for research.
Backend Service App: For research use cases, the Backend Service App represents a system that resides within the clinical care setting and interacts with the EHRs, Data Marts and the systems used by the researchers. The system will use specific Knowledge Artifact resources to identify when data has to be extracted, when data has to be queried and how results have to be returned. The term “Backend Service” is used to refer to the fact that the system does not require user intervention to perform reporting. The term “App” is used to indicate that it is similar to SMART on FHIR App which can be distributed to clinical care via EHR vendor-specified processes. The EHR vendor-specified processes enable the Backend Service App to use the EHR’s FHIR APIs to access data. The healthcare organization is responsible for choosing/developing and maintaining the Backend Service App within the organization.
Trust Service Provider: Trust Service Provider affords capabilities that can be used to translate data between different models, map terminologies between different data models, pseudonymize, anonymize, de-identify, hash, or re-link data that is submitted to public health and/or research organizations. These capabilities are called Trust Services. Trust Services are used, when appropriate, by the Backend Service App.
Research Organization: An organization that can access the data from clinical care or data repositories for research purposes with appropriate data use agreements, authorities, and policies.
IG © 2019+ HL7 International - Public Health Work Group. Package hl7.fhir.us.medmorph-research-dex#0.1.0 based on FHIR 4.0.1. Generated 2021-12-09
Links: Table of Contents |
QA Report
| Version History |
Search |
 |
Propose a change
|
Propose a change