
Data Types
The data types include primitive types imported from XML schema, and also additional data types that capture patterns that are ubiquitious throughout the scope of the healthcare data that will be exchanged.
Data Types defined on this page:
| Data | Quantity | HumanDate | HumanId | Contact |
| Concept | Money | Interval | Name | Location |
| Identifier | Ordinal | Address |
TODO: RTO, uncertainty, URG and GTS, iCal, KML
Primitive Types
The following table summarises the primitive types that are used in the exchange specifications.
| boolean | |
| integer | |
| decimal | |
| base64Binary | |
| datetime | Note: For system times, not human times (see below). Timezone is always required |
| string | |
| uri | |
The posssible values for these types are those specified in the W3C Schema specification part 2. Implementations that convert the xml described in this specification to other formats such as JSON or some object based notation will have to find equivalent types.
String Patterns
In addition to these assumed primitive types, this specification define a few simple string patterns that are commonly used:
| code | a string which has at least one character and no leading or trailing whitespace |
| oid | An ISO oid [ref ISO std] |
| sid | A Code or identifier system Id. All values are lowercase, and must be taken from the list of known defining systems |
Data
This type is for referring to data defined in other formats. The most common use of this to include images or reports in some report format such as PDF, but it can be used for any data that has a mime type.
<x> <mimeType type="code">the mime type of the content</mimeType> <data type="base64Binary"> data inline, base64ed</data> <url type="uri">url where the data can be found</url> <hash type="base64Binary">base64 sha-256 hash of the data</hash> <lang type="code">ISO 6133 language code</lang> <title type="string">A name to display in place of the data</title> <thumbnail type="Data">An abbreviated rendition for quick display</thumbnail> </x>
The mimeType element must always be populated with a valid mime type [rfc xx]. The actual content of the data can be conveyed directly using the data element, or a url reference can be provided. If both are provided, they must point to the same content. The reference can never be reused to point to different data (which means that the reference is version specific).
The hash is included so that applications can verify that the contents of a location have not changd, and also so that a signature of the xml content can implicitly sign the content of an image without having to include the data or reference the url in the signature. The lang element can help a consumer choose between multiple different Data elements.
The thumbnail can be used to provide the user with a quick display of the content, in order to help them decide whether they want a display of the full content. The thumbnail element cannot itself contain a thumbnail.
In many cases where Data is used, the cardinality is >1; repeats are used to convey the same data in different mime types and languages, or to provide a thumbnail of a large image.
Use
Unless the Data element has a dataAbsentReason flag, it must contain a data or a url. If neither data nor a url is provided, the value should be understood as an assertion that no content for the specified mimeType and/or lang is available.
The context of use may frequently make rules about the kind of data (and therefore, the kind of mime types) that can be used.
Examples
A PDF document:
<x> <mimeType>application/pdf</mimeType> <data>/9j/4...KAP//Z</data> <!-- covers many lines --> <lang type="code">en-us</lang> <title type="string">Definition of Procedure</title> </x>
A reference to a DICOM image:
<x>
<mimeType>application/dicom</mimeType>
<url>http://10.1.2.3:1000/wado?requestType=WADO&wado details...</url>
<hash>>EQH/..AgME</hash>
<thumbnail>
<mimeType type="code">the mime type of the content</mimeType>
<data>/9j/4AA..AP//Z</data>
<hash type="base64Binary">sha-256 hash of the data</hash>
</thumbnail>
</x>
Concept
A concept represents a reference to a terminology or ontology.
<x>
<coding type="list"> <!-- Zero+ -->
<code type="code">Symbol in syntax defined by the system</code>
<system type="oid|uri|sid">Id of the system that defines the concept</system>
<version type="string">Version of the defining system</version>
</coding>
<valueSet type="oid|uri">value set the concept was chosen from</valueSet>
<valueSetVersion type="oid|uri">version of the valueSet</valueSetVersion>
<text type="Narrative">a textual representation of the narrative</source>
<source type="uri">reference to where the concept came from</source>
<x>
This data type captures a single concept. The concept may be coded multiple times in different code systems (or even in the same code systems, where multiple forms are possible, such as with Snomed-CT).
For each coding, there must be a system the identifies the terminology or ontology the coding is against and may either be an oid (locally defined or registered in the HL7 OID registry), a uri that references a definition of the sytem, or a sid taken from the named systems list. Where the system is a URI, it must reference a service that returns a definition of the system at the nominated URL, and a definition of the instance at the URL generated by appending the code or identifier to the system URL. Further, appropriate governance arrangements must be in place to ensure that these URLs are extremely stable over a long term period. TODO: fix a protocol?
If present, the code must be a syntactically correct symbol as defined by the system. If no code is present, the coding means that the concept cannot be encoded in the identified system. A version is allowed because almost all code systems occasionally redefine codes from version to version and the full meaning of the code may be version specific. The meaning of the version depends on the identified system.
Whether or not coding elements are present, the source or text defines content that represents a human processible representation. The source is a reference to some text somewhere on which the concept is based.
Value Set
The valueSet is the set of concepts that the Concept is allowed to represent in a particular context. Every data item represented by a Concept is bound to a value set by the time it is used. Binding can occur in the following ways:
- This specification binds to a value set directly
- This specification binds to a Concept Domain, which is bound to a value set by a realm
- This specification binds to a Concept Domain, which is bound to a value set in the conformance statement
- None of the specification, realm, or conformance statement bind to a value set; the application must do so
The value set specifies a set of acceptable concepts and their representation as codes. The codes may come from multiple different systems. Because a user (or language processing robot) must choose a code from the value set, the value set may influence the meaning of the concept in the context in which it used. As a consequence, the valueSet may be specified in the Concept as an aid to interpretation, though it is never required to use it. The meaing of valueSetVersion is defined by the definition of the value set.
Use
Unless the Concept element has a dataAbsentReason flag other than "astext", it must contain at least one coding, or a text or a source. A Concept element may contain text and no other content without having a dataAbsentReason of astext, though only if the control flag is "text". If the Concept does have dataAbsentReason of "astext", a text must be provided, and this indicates that the source application has not attempted to code the content.
The context of use may frequently make rules about applicable value sets. The value sets may make rules about what kind of codes may be used from what kind of systems.
Examples
A simple code for headache, in ICD-10, with the text on which the coding is based:
<x>
<coding>
<code>G44.1</code>
<system>icd-10</system>
</coding>
<text>general headache</text>
</x>
A concept represented in an institutions local coding systems for which no snomed equivalent exists:
<x>
<coding>
<code>burn</code>
<system>2.16.840.1.113883.19.5.2</system>
</coding>
<coding>
<system>snomed-ct</system>
</coding>
<text>
<plain>Burnt ear with iron. Burnt other ear calling for ambulance</plain>
</text>
</x>
A Snomed-CT expression:
<x>
<coding>
<code>128045006:{363698007=56459004}</code>
<system>snomed-ct</system>
</coding>
<text>
<plain>Cellulitis of the foot</plain>
</text>
</x>
Identifier
An identifier defined by some external system.
<x> <system type="oid|uri|sid"> Identity of the system that owns the id</system> <id type="string"> the value of the identifier</id> <quality type="code"> whether the id has been checked</quality> </x>
The system may be either a specific application, or a recognised concept for which the specific application may be implicit. Where the system is a URI, it must reference either a service that returns a definition of the system at the nominated URL, and a definition of the instance at the URL generated by appending the code or identifier to the system URL. Further, appropriate governance arrangements must be in place to ensure that these URLs are extremely stable over a long term period.
The system may not be known. In this case, no useful matching may be perfomed unless the context makes it known.
The quality element allows for representation that the identifier has been actively checked against the source using some non-human based interaction, and is not subject to data entry error. It may contain either "checked" or "unchecked".
Use
Unless the Identifier element has a dataAbsentReason flag, it must contain a system and an id.
Examples
A primary key from an application table (an OID in the space allowcated by HL7 to some organisation to further sub-allocate):
<x> <system>2.16.840.1.113883.16.4.3.2.5</system> <id>123</id> </x>
An identifier of a resource defined by this specification, on a particular system:
<x> <system>http://pas-server/xxx/patients</system> <id>443556</id> <quality>checked</quality> </x>
A guid:
<x> <system>guid</system> <id>A76D9BBF-F293-4FB7-AD4C-2851CAC77162</id> <quality>checked</quality> </x>
Quantity
A measured amount (or an amount that can potentially be measured).
<x>
<value type="decimal">Numerical value (with implicit precision)</value>
<status type="code">See notes below</status>
<unit type="code">UCUM unit</unit>
<x>
The unit is taken from UCUM [reference] and therefore a canonical value can be generated for purposes of comparison between quantities. If no UCUM unit is specified, the default UCUM value of "1" applies, which represents a countable entity. Note that UCUM only includes precise physical units. Customary units such as "tablets" are not included - these should be represented as qualifiers on the thing to which the quantity applies.
The status indicates how the value should be understood and represented. If no status is specified, the value is a point value. The status can have the following values:
| < | The actual value is less than the given value |
| <= | The actual value is less than or equal to the given value |
| =>> | The actual value is greater than or equal to the given value |
| > | The actual value is greater than the given value |
| ~ | The actual value is somewhat imprecise, but how imprecise is not known (i.e. a human guess) |
The status element can never be ignored.
Use
Unless the Quantity element has a dataAbsentReason flag, it must contain at a value.
The context of use may frequently define what kind of quantity this is, and therefore what kind of units can be used. The context of use may also restrict the values for status.
Defined Variations on Quantity
These are used as types, but they are really just Quantity with rules
| Duration | The unit must be some amount of time. |
| Distance | The unit must be some amount of length. |
| Count | The unit must missing (i.e. 1) and the value a whole number |
Examples
A duration:
<x>
<value>25</value>
<unit>s</unit>
</x>
A concentration where the value was out of range:
<x>
<value>40000</value>
<status>></status>
<unit>U/L</unit>
</x>
Money
A value in a recognised financial currency.
<x>
<value type="decimal">Numerical value (with implicit precision)</value>
<currency type="code">ISO xx code</currency>
<x>
The context of use may constrain the currency to a particular type, but a value should always be specified explicitly.
Use
Unless the Money element has a dataAbsentReason flag, it must contain both a value and a currency.
Examples
A price:
<x>
<value>25.45</value>
<currency>USD</currency>
</x>
When the price is unknown (and not mandatory):
<x dataAbsentReason="unknown"/>
Ordinal
A code from a set of ordered codes. These are generally used for things like pain scales, questionnaires or formally defined assessment indexes.
<x>
<value type="decimal">Numerical value (with implicit precision)</value>
<code type="code"> Symbol in syntax defined by the system</code>
<system type="oid|uri|cid">Id of the system that defines the concept</system>
<version type="string">Version of the defining system</version>
</x>
The value is of type decimal because a few such scales generate real number values; the vast majority are simple whole numbers. In addition to a value, a code and a system may be specified. The code has the same meaning as the value. Refer to Concept for further information on code, system and version. Codes are usually appropriate on questionnaires.
Use
Unless the Ordinal element has a dataAbsentReason flag, it must contain either a value or a code.
Example
Where the choice "poor" is assigned a vaue of 1 and also coded in a local coding system:
<x>
<value>1</value>
<code>poor</code>
<system>2.16.840.1.113883.2.6.15.1.1</system>
</x>
HumanDate
While system dates are precise to the second (at least) humans don't work like this - dates reported or remembered are imprecise, and the imprecision is generally calendar based. This type captures this notion.
<x>
<date type="string">Partial Date in XML notation</date>
<text type="Narrative">Text explanation of date</text>
</x>
The date is either a known year, a known month, a known day, or a known time. Generally, there is no timezone, though one may be populated if hours and minutes are specified. The format is a union of the schema types gYear, gYearMonth, date, time. (Note by this definition, it is ambiguous whether the seconds are meaningful or not. It's generally safest to assume that they are not).
This type is used for some data points where the data may either come from a human or by known precisely by the system. In such cases, systems should not use sub-second precision.
Humans often recall dates in approximate terms that cannot be properly encoded using date. As an alternative, the date can be expressed as a free text explanation of the time where allowed.
Use
Unless the HumanDate element has a dataAbsentReason flag, it must contain a date and not a text. When text is provided, the dataAbsentReason must be "astext" or "error".
Examples
Standard date of birth:
<x>
<date>1951-06-04</date>
</x>
An estimated operation date (note that this is an advanced use; not all systems are expected to be capable of this):
<x dataAbsentReason="astext">
<date>2005-07</date>
<text>
<plain>Summer 2005</plain>
</text>
</x>
Interval
A set of ordered values defined by a low and high limit.
An interval may be applied to Quantity, Money, Ordinal, and HumanDate. The context where the type is used must specify which of these types is used.
<x> <low type="[param]">Text or elements from specified type</low> <lowEdge type="code">Whether the actual low is included</lowEdge> <high type="[param]">Text or elements from specified type</high> <highEdge type="code">Whether the actual high is included</highEdge> <text type="Narrative">Text alternative to the Interval</text> </x>
If the low or high elements are missing, the meaning is that the low or high boundaries are not known. A dataAbsentReason flag may be used on the low or high elements in this case. On time intervals, if the high is missing, it means that the interval is current and ongoing.
If the interval applies to the Quantity type, the status flag on the quantity cannot have the values <, <=, =>, or >.
The lowEdge and highEdge elements specify whether the given low and high values are included in the interval. They have the following possible values:
| included | Any matching value is included [default value for dates] |
| includedPrecise | Any matching is included without considering imprecision [default value for other types] |
| excluded | Any matching value is excluded |
| excludedPrecise | Any matching value is excluded without considering imprecision |
For example:
| 1.5[included] to 2.5 [excluded] | includes 1.50, 1.45, 2.44 but not 2.45, 2.5 |
| 1.5[includedPrecise] to 2.5 [excludedPrecise] | includes 1.50, 2.44, 2.45, 2.49999 but not 2.5, 1.45 |
| 2011-05-23[includedPrecise] to 2011-05-27[includedPrecise] | includes all the times of 23rd May through to precisely midnight on 27th May, but not any time more than a millisecond after that. |
| 2011-05-23[includedPrecise] to 2011-05-27[excludedPrecise] | includes all the times of 23rd May through to midnight on 27th May, but not actually midnight |
| 2011-05-23[included] to 2011-05-27[included] | includes all the times of 23rd May through to all the times on 27th May |
This complexity arises from the way humans use dates. In practice, the edge elements are rarely used because the default values are usually appropriate.
Use
Unless the Interval element has a dataAbsentReason flag, it must contain a low and, if it does not apply to a HumanDate, a high.
The text element may be used in place of the interval if the Interval element has a dataAbsentReason "astext" or "error".
Examples
Interval of Quantity (distance):
<x>
<low>
<value>2.8</value>
<unit>m</unit>
</low>
<high>
<value>4.6</value>
<unit>m</unit>
</high>
</x>
23rd May 2011 to 27th May, including 27th May:
<x>
<low>
<date>2011-05-23</date>
</low>
<high>
<date>2011-05-27</date>
</high>
</x>
A less precise interval:
<x dataAbsentReason="astext">
<text>
<plain>Winter 2009-2010</plain>
</text>
</x>
HumanId
An identifier that humans use. This is different to a system identifier because such identifiers are regularly changed or retired due to human intervention and error. Note that an human identifier may be a system identifier on some master system, but becomes a human identifier elsewhere due to how it is exchanged between humans. Driver's license nunmbers are a good example of this. Also, because human mediated identifiers are often invoked as implicit links to external business processes, such identifiers are often associated with multiple different resources. Human identifiers often have some type associated with them that is important to allow the identifier to be picked as a basis for exchange elsehwere, either in other electronic interchanges, or paper forms.
<x>
<type type="code">Code for identifier type</type>
<identifier type="Identifier">Actual identifier</identifier>
<period type="Interval(HumanDate)">Time period during
which identifier was valid for use</period>
<assigner type="resource(Organisation)">Organisation
that manages the identifier</assigner>
</x>
The code for identifier type must be taken from the list of defined identifier types.
The content models often use HumanId for an identifier that be an external human mediated reference, or that may also come from a direct unambiguous reference to a resource, or be from a seperate workflow, possibly human mediated. When the identifier is actually a direct resource reference, the use should be "resource", the type of should be the resource type, the identifier.system should be "xxx", and the identifier.id should be the resource id.
Use
An identifier with an id element is required unless a dataAbsentReason flag is provided on the identifier element. In some cases, the type of the identifier will be known, but not the identifier.system. For instance, a driver's license number, where the state, province or country that issues the license identifier is unknown.
The assigner.id may be replaced with assigner.text when used with the dataAbsentReason "astext".
Examples
A US SSN:
<x>
<type>ssn</type>
<identifier>
<system>ssn-us</system>
<id>000111111</id>
</identifier>
</x>
Notes:
- US SSNs are often presented like this: 000-11-1111, the dashes are for presentation and should be removed, as specified in the definition of ssn-us
- There is apparent duplication between type and system; the type says that this is a national social security identifier from some country, whiel the system specifically identifies the US SSN. Not all countries will have a registered system id like USA does; it might be useful to also reference the country in the assigning authority
A medical record number assigned on 5-July 2009:
<x>
<type>mrn</type>
<identifier>
<system>0.1.2.3.4.5.6.7</system>
<id>2356</id>
</identifier>
<period>
<low>
<date>2009-06-05</date>
</low>
</period>
</x>
Name
Names are associated with many things. Names may be changed, or repudiated, or things may have different names in different contexts.
Further, many names may be divided into parts, though the division into parts does not always matter. With personal names, the different parts may or may not be imbued with some implicit meaning; various cultures associate different importance with the name parts, and the degree to which systems must care about name parts around the world varies widely.
<x>
<use type="list(code)">codes for use of name</use>
<text type="Narrative">Text representation of the name</text>
<part type="list"> <!-- Zero+ -->
<use type="list(code)">codes for use of name part</use>
<type type="code">Type of name part (see below)</type>
<value type="string">The content of the name part</value>
<code type="code">code for the name part</code>
<system type="oid|uri|cid">id of the system that defines the code</system>
</part>
<period type="Interval(HumanDate)">Time period during
which name was in use</period>
</x>
The text element specifies the entire name as it should be represented. This may be provided instead of or as well as specific part elements. Every part must have a value.
Some name part types may need to be coded in some jurisdictions. The code represents the same concept as the value, and if it would be the same literal string value, may be omitted, and just the system defined.
The type of the name part (family, given, title, etc) must come from the list of name part types. The use codes for a part (middle, initial, nickname, etc) are space separated list and must come from the list of name part use codes. The use codes for a name (usual, official, temp, maiden, old, etc) are space separated list and must come from the list of name use codes. Note that applications are not generally required to support all of these codes. The choice of codes to support will be driven by the cultural context in which an application is implemented.
Use
Either text or at least one part is required unless a dataAbsentReason flag is provided on the name element.
Example
Full name of Peter James Chalmers, with a preferred name of James.
<x>
<use>usual official</use>
<part>
<type>given</type>
<value>Peter</value>
</part>
<part>
<use>callme</use>
<type>given</type>
<value>James</value>
</part>
<part>
<use></use>
<type>family</type>
<value>Chalmers</value>
</part>
</x>
See further examples
Address
There is a variety of postal address formats defined around the world. This format defines a superset that can be used in all locations to describe all known addresses. Note: address is for *postal addresses*. For pysical locations, see below.
<x>
<use type="list(code)">codes for use of address</use>
<text type="Narrative">Text representation of the address</text>
<part type="list"> <!-- Zero+ -->
<type type="code">Type of address part (see below)</type>
<value type="string">The content of the address part</value>
<code type="code">code for the address part</code>
<system type="oid|uri|cid">Id of the system that defines the code</system>
</part>
<period type="Interval(HumanDate)">Time period during
which address was/is in use</period>
</x>
The text element specifies the entire address as it should be represented. This may be provided instead of or as well as specific part elements.
Some address part types may need to be coded in some jurisdictions. The code represents the same concept as the value, and if it would be the same literal string value, may be omitted, and just the system defined.
The type of the address part (line, suburb, zip, state, etc) must come from the list of address part types. The use codes for a name (home, work, temp, etc) are a space separated list and must come from the list of address use codes. Note that applications are not generally required to support all of these codes. The choice of codes to support will be driven by the cultural context in which an application is implemented.
Country specific notes:
- In english language countries, most systems collect 1-3 lines of address ("addressline"), a locality name, a zip code, and a state or province Example:
- other....
Use
Either text or at least one part is required unless a dataAbsentReason flag is provided on the address element.
Example
HL7 office's address.
<x>
<use>work primary</use>
<text>
<html xmlns="http://www.w3.org/1999/xhtml">
1050 W Wishard Blvd<br/>RG 5th floor<br/>Indianapolis, IN 46240
</html>
</text>
<part>
<type>city</type>
<value>Indianapolis</value>
</part>
<part>
<type>state</type>
<value>IN</value>
</part>
<part>
<type>zip</type>
<value>46240</value>
</part>
</x>
See further examples
Contact
TODO: this follows the ISO 21090 URI model, which does have it's price. Would a less formal model be better?
All kinds of technology mediated contact details for a person or organisation, including telephone, email, etc.
<x>
<use type="list(code)">codes for use of address</use>
<capabilities type="list(code)">what the endpoint can do</capabilities>
<value type="uri">The actual contact details</value>
<period type="Interval(HumanDate)">Time period during
which address was/is in use</period>
</x>
The value must be from one of the following schemes:
| tel | telephone numbers. See [rfc 3966 and rfc 2806] |
| email addresses. See [rfc 2368] | |
The use codes for a contact (home, work, temp, etc) are a space separated list and must come from the list of contact use codes. The capabilities codes for a contact (voice, sms, etc) are a space separated list and must come from the list of capabilities use codes. Note that applications are not generally required to support all of these codes. The choice of codes to support will be driven by the context in which an application is implemented.
Use
A value is required unless a dataAbsentReason flag is provided on the contact element.
Example
Phone number for some one who works at home:
<x> <use>home work primary</use> <capabilities>voice fax</capabilities> <value>tel:+15556755745</value> </x>
See further examples
Location
TODO: Location (google KML)
UML Summary
This UML diagram provides a summary of the data types defined here and in the Resource XML section. The UML diagram defines some additional abstract types that are required for the purposes of managing type substitution.
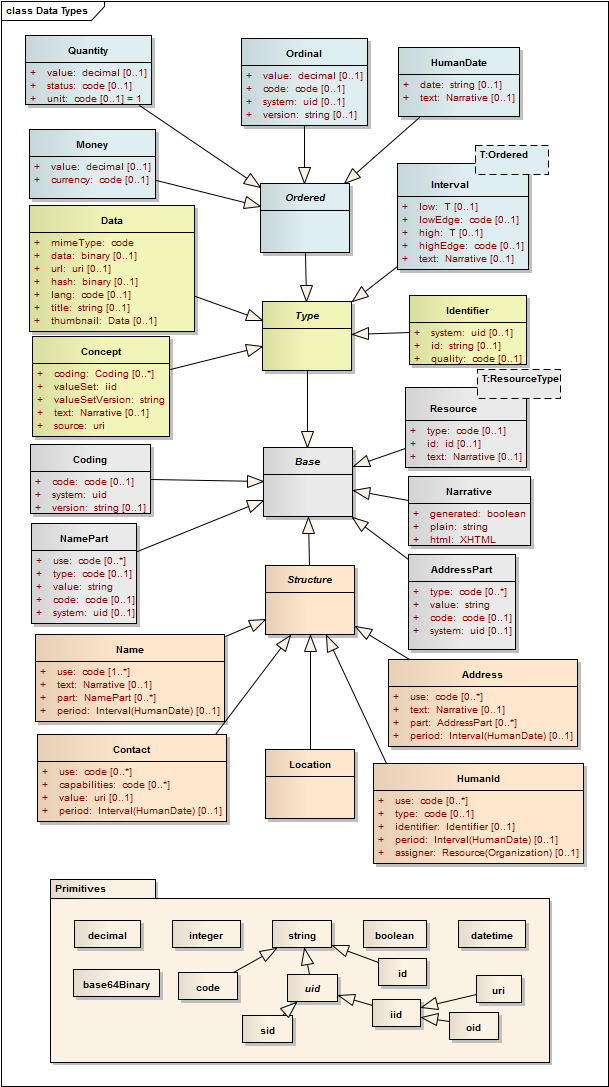
See notes about the UML Object models, and particularly the note regarding the UML representation of dataAbsentReason
© 2011 ![]()