 . Page versions: R5 R4B R4 R3 R2
. Page versions: R5 R4B R4 R3 R2This page is part of the FHIR Specification (v0.05: DSTU 1 Draft). The current version which supercedes this version is 5.0.0. For a full list of available versions, see the Directory of published versions . Page versions: R5 R4B R4 R3 R2
In this specification, resources are described in a simple XML format. This page documents how the XML content for resources is described and controlled. The XML may be validated by schema and schemas are provided, but validation is not required in operational systems (though the XML must always be valid against this specification). In addition to the simple XML description, W3C Schema, UML models, and other definitional models are provided that may be a useful aid for system implementation.
To provide a visual sense of what the end resource instances will look like, all resources include documentation of their allowed content in a pseudo-XML syntax that uses the following notation:
<name xmlns="http://hl7.org/fhir" [xml:lang]>
<nameA><!-- 1..1 type description of content --><nameA>
<nameB d?><!-- 0..1 type description --></nameB>
<nameC> <!-- 1..* -->
<nameD d?><!-- 1..1 type>Relevant records --></nameD>
</nameC>
<name>
Notes:
Every resource contains the following common elements:
<[Name] xmlns="http://hl7.org/fhir"> <id><!-- 0..1 id Master Resource Id, always first in all resources --></id> <extension><!-- 0..* Extension See Extensions --></extension> <text><!-- 1..1 Narrative Text summary of [x], for human interpretation --></text> </[Name]>
The id element is always mandatory except in the case that a resource is posted to a server to create it, and the id of the resource is not yet known. In this case, the id element is absent. The use of the id element is discussed further below. The use of the extensions element is discussed under "Extensibility". The text ("Narrative") is discussed below. In addition to these data elements, there are several pieces of metadata about a resource that are not part of the resource content, but are delegated to the infrastructure:
| Metadata Item | Type | Usage |
|---|---|---|
| Version Id | id | Changed each time the content of the resource changes. Can be referenced in a resource reference (see below). Can be used to ensure that updates are based on the latest version of the resource. |
| Last Modified Date | dateTime | Changed each time the content of the resource changes. Can be used by a system or a human to judge the currency of the resource content. |
| Master Location | uri | Reports the location of the master for the resource. Useful when a resource is re-used by another system - it can report the location of the master should any system need to know this. |
In any environment where the resources are used, the technical details of how these metadata elements are represents will need to be resolved. For further details, see Implementation Details.
Data Quality - or the lack thereof - is a ubiquitious issue in healthcare. In order to handle this, many elements defined as part of a resource may have a dataAbsentReason attribute. This attribute may be used to specify why the normally expected content of the data element is missing.
<x dataAbsentReason=""/>
The dataAbsentReason attribute can have one of the following values:
| unknown | The value is not known |
| asked | The source human does not know the value |
| temp | There is reason to expect (from the workflow) that the value may become known |
| notasked | The workflow didn't lead to this value being known |
| masked | The information is not available due to security, privacy or related reasons |
| unsupported | The source system wasn't capable of supporting this element |
| astext | The content of the data is represented as text (see below) |
| error | Some system or workflow process error means that the information is not available |
Notes:
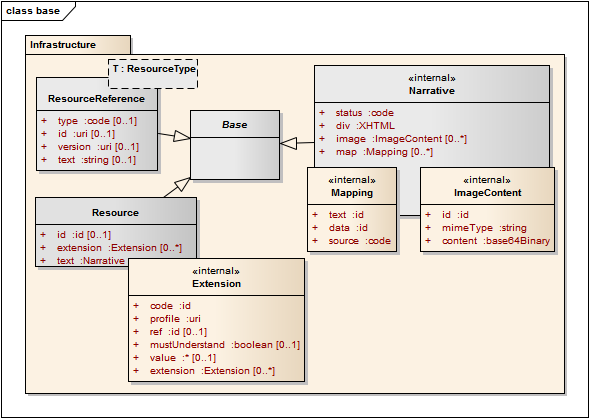
Every resource SHALL include a human readable narrative that contains a summary of the resource, and may be used to represent the content of the resource to a human. The narrative need not encode all the structured data, but is required to contain sufficient detail to make it "clinically safe" for a human to just read the narrative. Resources may define what content should be represented in the narrative to ensure clinical safety.
The narrative for a resource is allowed to contain additional information that is not in the structured data, including human-edited content. Such additional information must be in the scope of the definition of the resource. In small, closed trading partner environments, there may be no need for a narrative text. In such cases, implementations are allowed to populate the narrative with text equivalent to "No human readable text provided for this resource" (other languages are allowed). Implementers should note that small, closed traing partner environments are very likely to open up during the lifetime of the resources they define.
Each narrative has a flag that specifies the relationship between the narrative and the structured data. This flag may have one of the following codes:
| generated | The contents of the narrative are entirely generated from the structured data in the resource. |
| extensions | The contents of the narrative are entirely generated from the structured data in the resource and some of the narrative is generated from extensions |
| additional | The contents of the narrative contain additional information not found in the structured data |
In addition to this general flag that specifies the status of the narrative, there is an optional mapping between the narrative and the structured data. Each mapping has narrative id and structured data id which provide internal references to the narrative and the structured data respectively, and a flag for whether the text was generated from the data, or the data was generated from the text (by some form of retrospective processing, whether human or computer), or whether both come from an external source. The structured data target may be an empty element with a dataAbsentReason of "astext"; this means that the value of the text could not be properly represented in the data type. Any element defined as part of the resource content, or any repeating element inside a data type may carry an id attribute to serve as the target of a narrative mapping.
The narrative is an xhtml fragment that also includes images if appropriate:
<x xmlns="http://hl7.org/fhir"> <status><!-- 1..1 code generated | extensions | additional --></status> <div xmlns="http://www.w3.org/1999/xhtml"> <!-- Limited xhtml content< --> </div> <image> <!-- 0..* Images referenced in xhtml --> <mimeType><!-- 1..1 code Mime type of image --></mimeType> <content><!-- 1..1 base64Binary base64 image data --></content> </image> <map> <!-- 0..* --> <text><!-- 1..1 idref Narrative source (by id attribute) --></text> <data><!-- 1..1 idref Data source (by id attribute) --></data> <source><!-- 1..1 code text | data --></source> </map> </x>
Terminology Bindings
| generated | The contents of the narrative are entirely generated from the structured data in the resource. | |
| extensions | The contents of the narrative are entirely generated from the structured data in the resource and some of the content is generated from extensions | |
| additional | The contents of the narrative contain additional information not found in the structured data | |
| text | The text is the original data | |
| data | The data is the original data | |
The contents of the div element are an XHTML fragment containing only the basic html formatting elements described in chapters 7-11 (except section 4 of chapter 9) and 15 of the HTML 4.0 standard, <a> elements (either name or href), images and internally contained style attributes. The XHTML content must not contain a head, a body element, external stylesheet references, scripts, forms, base/link/xlink, frames, iframes, and objects.
<narrative>
<div xmlns="http://www.w3.org/1999/xhtml">This is a simple
example with only plain text</div>
</narrative>
<narrative>
<div xmlns="http://www.w3.org/1999/xhtml">
<p>
This is an <i>example</i> with some <b>xhtml</b> formatting.
</p>
</div>
<narrative>
The image source may be a local reference within the resource:
<img src="#a5"/>
This is a internal reference to an id attribute on an element in the same resource, either in the image attachments on the text element directly, or an element of type "Attachment".
<narrative>
<html xmlns="http://www.w3.org/1999/xhtml">
<p>
<img src="#a1/>.
</p>
</html>
<image id="a1">
<mimeType>image/png</mimeType>
<data>MEKH....SD/Z</data>
</image>
<narrative>
Since the presence of images that are not part of the resource is not guaranteed, images that are an essential part of the narrative should always be embedded.
The dataAbsentReason is not used on the narrative element or any elements contained in it. The xhtml element must have some non-whitespace content.
Note: the XHTML is contained in general XML, and there is no support for HTML entities like or © etc. Unicode characters should be used instead. Note that   substitutes for .
The XHTML fragment in the narrative may be styled using CSS in the normal fashion, using a mix of classes, ids and in-line style elements. Specific CSS stylesheets will be applied to the XHTML when it is extracted from the resource to be displayed to a human to create the presentation desired in the context of use. Authors may fix the following styling aspects of the content:
These style properties are specified in-line using the style attribute. If an equivalent html element exists, such as "i", or "pre", it may be used instead, but note that some of these elements are deprecated in HTML 4 and must not be used in Narrative XHTML (including "u", and "font").
Rendering systems are required to respect any of these rendering styles when they are specified in the XHTML, though appropriate interpretation is allowed (e.g. a low-contrast display for dark room contexts may adjust colors accordingly).
Authors are allowed to specify additional styles and style properties as specified in the CSS specification, but these are extensions to this specification and renderers are not required to honor them. Note, however, the additional rules around styling that apply in the context of documents.
There are 4 cases where elements inside a resource reference each other:
These references are done using an id/idref based approach, where a source element indicates that it has the same content as the target element. The target element has an attribute "id" which must have a unique value within the resource with regard to any other id attributes. The "id" attribute is not in any namespace. The source element has no content (text or children elements) and just a single attribute named "idref". The value of the idref attribute must match the value of an id attribute in the same resource (or, for a CodeableConcept, inside the same datatype).
<example>
<target id="a1">
<child>content</child>
</target>
<-- other stuff -->
<source idref="a1">
</example>
In a single resource, this works exactly like xml:id/idref, but there is an important difference: the uniqueness and resolution scope of these id references is within the resource that contains them. If multiple resources are combined into a single piece of XML, such as an atom feed, duplicate values may occur between resources. This must be managed by applications reading the resources.
The "Resource" type indicates a reference from one resource to another.
<x xmlns="http://hl7.org/fhir"> <type><!-- 0..1 code Resource Type --></type> <id><!-- 0..1 uri URL/Id of the reference --></id> <version><!-- 0..1 uri Specific version URL/Id of resource referenced --></version> <text><!-- 0..1 string Text alternative for the resource --></text> </x>
Terminology Bindings
Whether or not the type of the resource reference is fixed for a particular element, the reference includes the resource type.
Both the id and the version are URL based references - they must be literal URLs that resolve to the location of the resource. Both URLs may be relative URLS, in which case they are interpreted to contain the logical id and versionId respectively of the resource in question, and the resolution of the logical reference is a matter of implementation logic. Using absolute URLs provides a stable scalable approach suitable for a cloud/web context, while using relative/logical references provides a flexible approach suitable for use when trading between separated eco-systems. Absolute URLs do not need to point to a FHIR RESTful server, though this is the preferred approach.
A resource reference may contain either a version independent reference ("id") or a version dependent reference ("version") or both. If both are provided, it is at the descretion of the processor of the data which to use in a particular context. If relative references are used, a version cannot be provided without an id, since the version may be scoped by the id.
A relative reference to the patient "034AB16" in an element named "context":
<context>
<type>Patient</type>
<id>034AB16</id>
<context>
An absolute reference to a resource profile in an element named "profile":
<profile>
<type>Profile</type>
<id>http://fhir.hl7.org/svc/profile/@c8973a22-2b5b-4e76-9c66-00639c99e61b</id>
<profile>
Note that HL7 has not yet actually created a profile registry, nor decided on a URL for it.
The logical id and version id of a Resource can take one of the following forms:
| A whole number in the range 0 to 2^64-1. May be represented in hex | |
| A uuid (guid) (in lowercase, without wrapping with the characters "{}[]" which sometimes occur) | |
| An ISO OID | |
| Any other combination of letters, numerals, "-" and "." | |
Resource ids must be represented in lowercase. Ids are always opaque, and systems should not and need not attempt to determine their internal structure. However the id is represented, it must always be represented in the same way in resource references and URLs. Note that absolute URLs that do not point to FHIR RESTful servers do not need to include the id in the URL, though this is good practice. If the id is in the URL, it must be present in lower case. Irrespective of whether the URL points to a FHIR RESTful server or includes the logical id in the URL, URLs are always considered to be case-sensitive and lowercase is preferred.
Plain text narrative may be provided that describes the resource in addition to the resource reference (or in place of, if a dataAbsentReason is allowed).
<id>
<type>Organisation</type>
<id>1234</id>
<text>HL7, Inc</text>
<id>
Use
Unless the resource reference element has a dataAbsentReason flag, it must contain a valid type and (id or version).
There is no explicit version marker in the XML. Subsequent versions of this specification may introduce new elements at any point in the content models, but the path and meaning of existing data elements will not be changed. Given that, in a typical scenario, mixed versions may need to exist, applications SHOULD ignore elements that they do not recognize unless those elements are marked with a "must understand" attribute. However, in a healthcare context, many application vendors are unwilling to consider this approach because of concerns about clinical risk. Applications are not required to ignore unknown elements, but must declare whether they will do so in their conformance statements using the acceptUnknown element.
This specification provides schema definitions for all of the content models described here. The base schema is called "fhir-base.xsd" and defines all of the datatypes and also the base infrastructure types described on this page. In addition, there is a schema for each resource and a common schema fhir-all.xsd that includes all the resource schemas. A customized atom schema fhir-atom.xsd is provided for validating bundles.
In addition to the w3c schema files, this specification also provides Schematron files that enforce the various constraints defined for the datatypes and resources. These are packaged as files for each resource as well as a combined fhir-atom.sch file that incorporates the rules for all resources.
XML that is exchanged must be valid against the w3c schema and Schematron, though there is no requirement to validate instances against either, nor is being valid against the schema and Schematron sufficient to be a conformant instance. (This specification makes several rules that cannot be checked by either mechanism.) Exchanged content must not specify the schema or even the schema instance namespace in the resource itself.
In addition to the schema, this specification also provides object models defined in UML that may be of assistance in defining systems that work with the resources defined here.
Although the UML models provided express the same contents as the resource formats, because of the wide variation in how different architectures and tools map from UML to XML, there should be no expectation that any particular tool will produce compatible XML from these UML diagrams. Systems are welcome to use these object models as a basis for serialization internally or even between trading partner systems, with any form of exchange technology (including JSON). Systems that use this form of exchange cannot claim to be conformant with this specification, but can describe themselves as using "FHIR consistent object models".
Informative Section: Due to a series of issues around the formal standardization of the JSON representation, the standard JSON representation for resources is only informative.
Though the formal representation of the resources is in XML, many systems wish to use JSON to exchange the resources and it is useful to standardise a single JSON format for this use. The JSON format for the resources follows the standard XML format closely so XPath queries can easily be mapped to query the JSON structures:
There are differences too:
These differences - particularly the repeating element one, which cannot be avoided - ensure that generic XML --> JSON converters are not able to perform correctly. The reference platforms will provide XML <--> JSON conversion functionality.
FHIR elements with primitive values are represented as JSON object members of the same name, with their value encoded as a string. Native JSON types other than "string" are never used to guarantee equivalence of the serialized representation between XML and JSON.
Primitive elements used inside the FHIR datatypes cannot have an 'id' or 'dataAbsentReason' attribute, so they are rendered in JSON as a property and value:
<date>1972-11-30</date>
is represented in JSON as
"date": "1972-11-30"
Primitive elements inside resources can have 'id' or (if allowed) 'dataAbsentReason' attributes, so their JSON representation uses a JSON object with members '_id', 'dataAbsentReason' and 'value', which contains the actual primitive value as string. Note that in most cases, the primitive will not have a value when there is a dataAbsentReason present, in which case the special 'value' member must not be present. So,
<dob id='314159'>1972-11-30</dob>
is represented in JSON as:
"dob": { "_id": "314159", "value": "1972-11-30" }
while this example would look like this in the case of a dataAbsentReason:
"dob": { "_id": "314159", "dataAbsentReason": "Unknown" }
Repeating elements are rendered withing a JSON array with the name of the element, so a repeating <dob> element in
<dob>2011-11-30</dob> <dob id='314159'>1972-11-30</dob>
is represented in JSON like so:
"dob": [
{ "value": "2011-11-30" },
{ "_id": "314159", "value": "1972-11-30" }
]
Resources and other composite datatypes (types that contain named elements of other types) are represented using a JSON object, containing a member for each element in the datatype. Composites can have id's and dataAbsentReasons, therefore these attributes get converted to JSON members values, in the same manner as described for primitives. These members will be placed before all other members. For example:
<Person>
<id>34234</>
<name>
<use>official</use>
<part>
<type>given</type>
<value>Karen</value>
</part>
<part id="n1">
<type>family</type>
<value>Van</value>
</part>
</name>
<text>
<status>generated</status>
<div xmlns="http://www.w3.org/1999/xhtml">...</div>
</text>
</Person>
is represented in JSON as:
{
"Person" : {
"id" : { "value" : "34234" },
"name" : [{
"use" : "official",
"part" : [
{
"type" : "given",
"value" : "Karen"
},
{
"_id" : "n1",
"type" : "family",
"value" : "van"
}]
}],
"dob" : { "dataAbsentReason" : "notasked" },
"language" : [
{
"code" : { "_id" : "lang-1", "value" : "dut" },
"use" : { "value" : "fluent" }
},
{
"code" : { "value" : "cmn" },
"use" : { "value" : "useable" }
}],
"text" : {
"status" : "generated",
"div" : "<div xmlns='http://www.w3.org/1999/xhtml'>...</div>"
}
}
Things to note here are:
 This is an old version of FHIR retained for archive purposes. Do not use for anything else
This is an old version of FHIR retained for archive purposes. Do not use for anything else
Implementers are welcome to experiment with the content defined here, but should note that the contents are subject to change without prior notice.
© HL7.org 2011 - 2012. FHIR v0.05 generated on Sun, Sep 9, 2012 03:28+1000. License