At its core, FHIR contains two primary components:
Resources - a collection of information models that define the data elements, constraints and relationships for the “business objects” most relevant to healthcare. From a model-driven architecture perspective, FHIR resources are notionally equivalent to a physical model implemented in XML or JSON. See the formal definition.
APIs – a collection of well-defined interfaces for interoperating between two applications. Although not required, the FHIR specification targets RESTful interfaces for API implementation. See details on FHIR RESTful interfaces.
In the healthcare domain, the set of “business objects” is not universally defined, but there is a notional and ongoing evolutionary,
consensus-based process for standardizing on a core set of common business objects including things like “a patient”, “a procedure”,
“an observation”, “an order”, etc. (see a list of defined resources). The FHIR specification provides
a framework for defining these healthcare business objects (“resources”), for relating them together in a compositional manner, for
implementing them in a computable form, and for sharing them across well-defined interfaces. The framework contains a verifiable and
testable syntax, a set of rules and constraints, methods and interface signatures for “FHIR-aware” APIs, and specifications for the
implementation of a server capable of requesting and delivering FHIR business objects.
From an operational perspective, HL7’s internal standards development and governance processes determine what constitutes a
resource and which resources exist. In addition, the FHIR specification also provides a mechanism for contextualizing resources for
specific needs within specific bounds (see Profiling Resources).
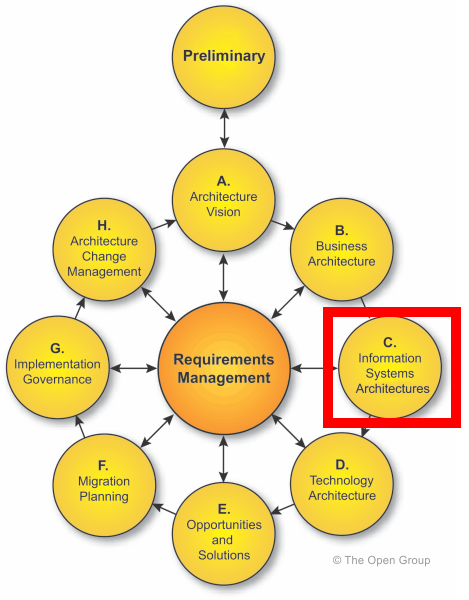
2.16.1 Architecture Frameworks and FHIR Alignment
FHIR resources fit firmly within the information architecture domain and the FHIR APIs for data exchange
address aspects of application architecture.
From a TOGAF perspective , FHIR addresses aspects of architecture
views related to information model definition and data exchange, which are described in the Information Systems Architectures portion
of the TOGAF Architecture Development Method.
With regards to the Zachman Framework , FHIR fits
within the What and the How dimensions of the Architect, Engineer and Technician Perspectives
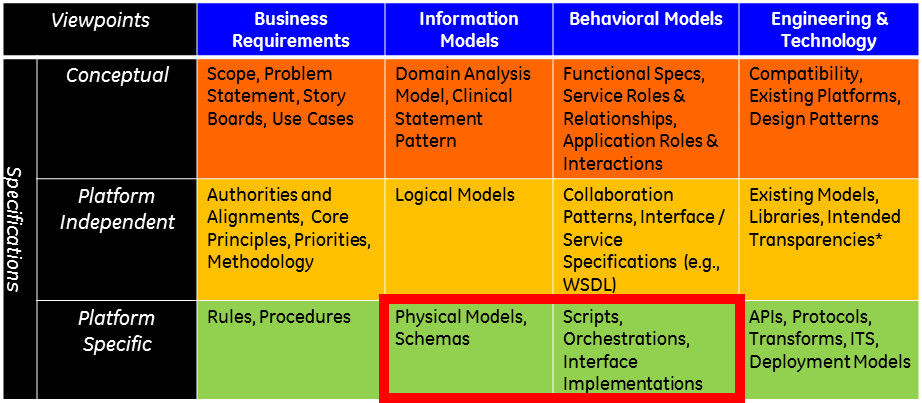
When considering the HL7 Services Aware Interoperability Framework (SAIF) ,
FHIR resources and RESTful APIs represent the “Physical Models” and “Interface Implementations” within the Platform Specific Specifications layer of the
Information Models and the Behavioral Models Viewpoints, respectively.
2.16.2 FHIR and Architectural Principles
FHIR’s primary purpose is to address interoperability with well-structured, expressive data models and simple, efficient data exchange mechanisms.
In addition, FHIR aligns to the following architectural principles:
Reuse and Composability – FHIR resources are designed with the 80/20 rule in mind – focus
on the 20% of requirements that satisfy 80% of the interoperability needs. To this end,
resources are designed to meet the general or common data requirements of many use cases
to avoid the proliferation of numerous, overlapping and redundant resources. Extension and customizations exist
(see FHIR Profiles) to allow common, somewhat generic resources to be adopted
and adapted as needed for specific use case requirements. In addition, FHIR resources are highly composable
in that resources commonly refer to other resources. This further promotes reuse and allows for complex structures
to be built from more atomic resources.
Scalability – Aligning FHIR APIs to the REST architectural style ensure that all transactions are stateless which
reduces memory usage, eliminates the needs for “sticky” sessions within a server farm and therefore supports horizontal scalability.
Performance – FHIR resources are lean and suitable for exchange across the network. Highly optimized formats are available, which has the potential to
improve performance in complex transactions across multiple systems connected via a shared and finite network, though most implementers find the standard
JSON / XML formats adequate.
Usability – FHIR resources are understood by technical experts and non-technical people alike. Even if the details of
XML or JSON syntax are not understood, non-technical people can view these in any browser or text reader and understand the contents within them.
Data Fidelity – FHIR is strongly typed and has mechanisms built in for clinical terminology linkage and validation. In addition,
XML and JSON documents can be validated syntactically as well as against a defined set of business rules. This promotes high data
fidelity and goes a long way towards using FHIR to achieve semantic interoperability.
Implementability – One of the driving forces for FHIR is the need to create a standard with high adoption across disparate developer communities.
FHIR is easily understood and readily implemented using industry standards and common mark-up and data exchange technologies.
There are additional architecture principles related to consistency, granularity, referential integrity, and others that are not as
well established or proven. See the section below on Outstanding Issues for details.
2.16.3 FHIR Decomposition
As discussed, FHIR’s principal components are resources and RESTful APIs. However, there is more to the FHIR specification including the components depicted below.
NOTE: The term “component” is used loosely to mean a part of something and does not intend to carry the specific meanings for this term
provided by rigorous ontologies, modeling frameworks, or other architectural and organizational constructs. Diagrammatically, the components
below are depicted below as UML classes. This is done purely to take advantage of the semantics afforded using this notation. FHIR is neither
objected oriented in its modeling approach nor are the components that make up the FHIR specification UML classes or objects in the formal sense.
Likewise, the UML packages shown below are notional and used for organizational purposes only.
As shown in the diagram below, it is convenient to think of the FHIR specification as having components that address the following:
Information Model – the components of FHIR related to the creation of FHIR resources
Constraints – the components of FHIR addressing constraints and validity
Terminology – the components of FHIR related to clinical terminologies and ontologies
Usage – the component of FHIR addressing the use of FHIR in a run-time capacity
The following list provides general guidelines that apply when FHIR resources are defined. Most of these items are not enforced programmatically
requiring human due diligence and governance to ensure adherence.
Resources should have a clear boundary; one that matches one or more logical transaction scopes
Resources should differ from each other in meaning, not just in usage (e.g., each different way to use a lab report should not result in a different resource)
Resources need to have a natural identity
Most resources should be very common and used in many different business transactions
Resources should not be specific or detailed enough to preclude support for a wide range of business transactions
Resources should be mutually exclusive [this is a very important consideration that helps to reduce redundancy and ambiguity]
Resources should use other resources, but they should be more than just compositions of other resources; each resource should introduce novel content
Resources should be organized into a logical framework based on the commonality of the resource and what it links to (see resource framework below)
Resources should be large enough to provide meaningful context; resources that contain only a few attributes are likely too small to provide meaningful business value
Resources should reflect general usage:
if most systems treat something as a single concept, that suggests a single resource; if most systems treat something as distinct concepts, then that suggests multiple resources
if two different uses of a "resource" would result in wildly different interpretations of what constitutes "core" then that suggests two resources might be appropriate.
There is a bias towards fewer resources rather than more
2.16.5 Organizing FHIR Resources
It is impractical to model the entirety of health data in a single information model. Every modeling
initiative in healthcare from HL7 version 2 message specifications to FHIR resources decomposes the
healthcare domain into smaller, more manageable sub-domains or information model snippets. With FHIR,
each resource is essentially a snippet of the larger healthcare information domain.
When breaking down the healthcare information model into smaller chunks (or resources for FHIR), it
is important to have a framework and set of guidelines to promote consistency and integrity within
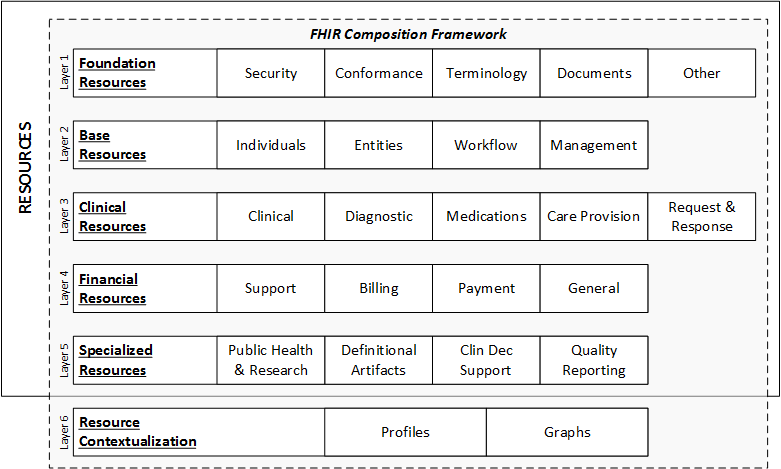
the resource structures and in the way resources reference each other. The framework shown below
includes health information model sub-categories organized into layers based on their degree of
commonness. The layers and categories are useful for identifying which parts of healthcare information
are the most common and therefore need to be the most consistently defined and tightly governed. The
categories at the top layers are the most common and contain the FHIR resources that support the
largest number of common healthcare transactions.
Descriptions of the layers in the framework:
Foundation Resources: Foundation resources are the most rudimentary, foundational resources. They are often used for infrastructural tasks.
Although not prohibited, they are not always referenced by other resources.
Base Resources: Layer two consists of base resources. These are often the leaf nodes of a resource graph. In other words, they are often
referenced by other resources, but don't typically reference other resources themselves. These resources are typically the most commonly used, and
therefore require the highest degree of consistency and architectural rigor. Governance is greatest for resources in layers one and two.
Clinical Resources: Layer 3 includes the resources that are clinical in nature but are also very common across many use cases. This
includes resources for clinical observations, clinical treatment, care provision, and medications. These resources can be used by themselves, but
typically build on the resources in layer two. For example, an observation resource will reference the patient resource from layer two. These resources
are also frequently contextualized when they are referenced by resources in layers three, four and five.
Financial Resources: Layer four is dedicated to financial resources. Logically, financial resources build on clinical and base resources.
For example, a billing resource will reference clinical events and activities as well as base resources like a patient.
Specialized Resources: In layer five, we find more specialized resources for less common use cases. These resources almost always reference
resources in lower layers. Given that FHIR places priority on satisfying the most common use cases, there are fewer resources in this layer.
Resource Contextualization: Layer 6 does not contain resources. However, it does extend the composition framework made up by the first
five layers of resources. Layer 6 includes profiles and graphs. Profiles are used to extend, constrain, or otherwise contextualize resources for
a given purpose. Graphs are compositions of resources, or webs of resource, that contain attributes of their own.
The complete set of FHIR resources organized against this framework is found on the Resources page.
The framework serves three primary purposes:
Organize resource for navigation and identification
Classify resources into categories based on common sense groupings or patterns describing expected structures and/or behaviors amongst resources in the same category
Disseminate resources across layers to stratify relative common-ness with the most common resources in the top layers
Purposes 2 and 3 set the foundation for future architectural rigor and resource governance to optimize
consistency, integrity and predictability of new or refined resources in the future. The actual rules
and patterns will be defined and refined in future FHIR releases. However, one general guideline to
state now is that resources generally reference resources in the same layer or higher. In other words,
a layer 4 resource will typically only reference resources in layers 4, 3, 2 or 1. There is nothing
prohibiting a layer 4 resource from referencing a layer 5 resource, but this is not as common.
Given this guideline, it is possible to identify the resources that are likely to be most common
across use cases and therefore demand the highest degree of consistency and governance. Further, the
framework helps identify the areas where creating new FHIR resources is the highest priority. It is
generally a higher priority to create FHIR resources in the higher layers (layers 1, 2 and 3) than
it is to create FHIR resources in the lower layers (layers 4 and 5) because the higher layer resources
will provide the greatest value across the largest number of use cases and stakeholders. This is not
to say that the business transactions needed for the higher layers are not important, it’s just that
they are not as common across the whole healthcare space.
The 6th layer of the framework are not actually resources. Profiles and Graphs are extensions of resources
or resource compositions that continue the progression through the FHIR Composition Framework. They provide
additional contextualization required to satisfy certain use cases.
There are several benefits expected from aligning the creation of FHIR resources to this framework, including:
Organization and manageability of health domains - the framework provides a basis for decomposition and modularity
Identifying commonality - the framework teases out the common areas from the less common areas
FHIR resources prioritization - the framework provides a structure for determining priorities and delegating work
Tiered governance levels - the framework separates the areas needing the most stringent and universal governance from those that require more context-specific governance
Another useful tool for visualizing how FHIR resources are organized relative to each other can be found using the Resource Reference
Visualization tool on clinFHIR .
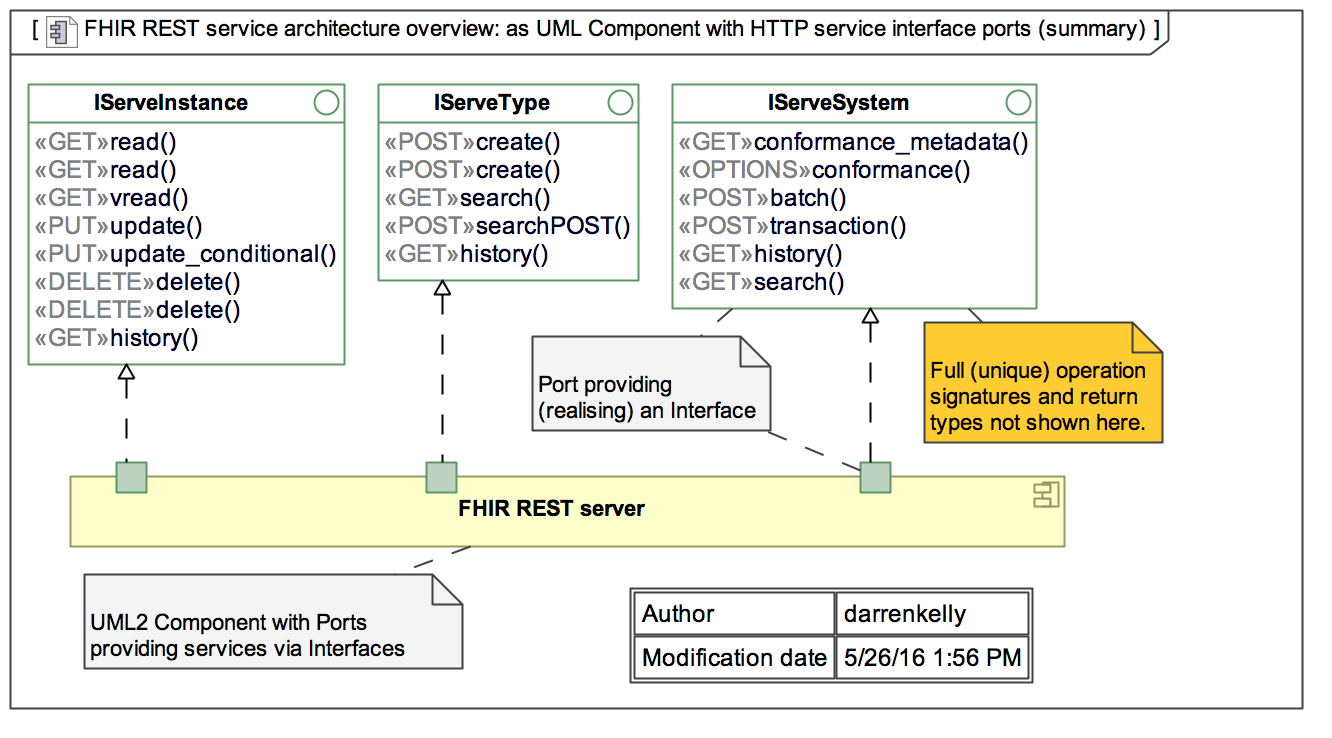
A FHIR REST server is any software that implements the FHIR APIs and uses FHIR resources to exchange data. The diagram below describes the FHIR interface definitions. The methods are classified as:
iServeInstance – methods that perform Get, Put or Delete operations on a resource
iServeType – methods that get type information or metadata about resources
iServeSystem – methods that expose or enable system behaviors.
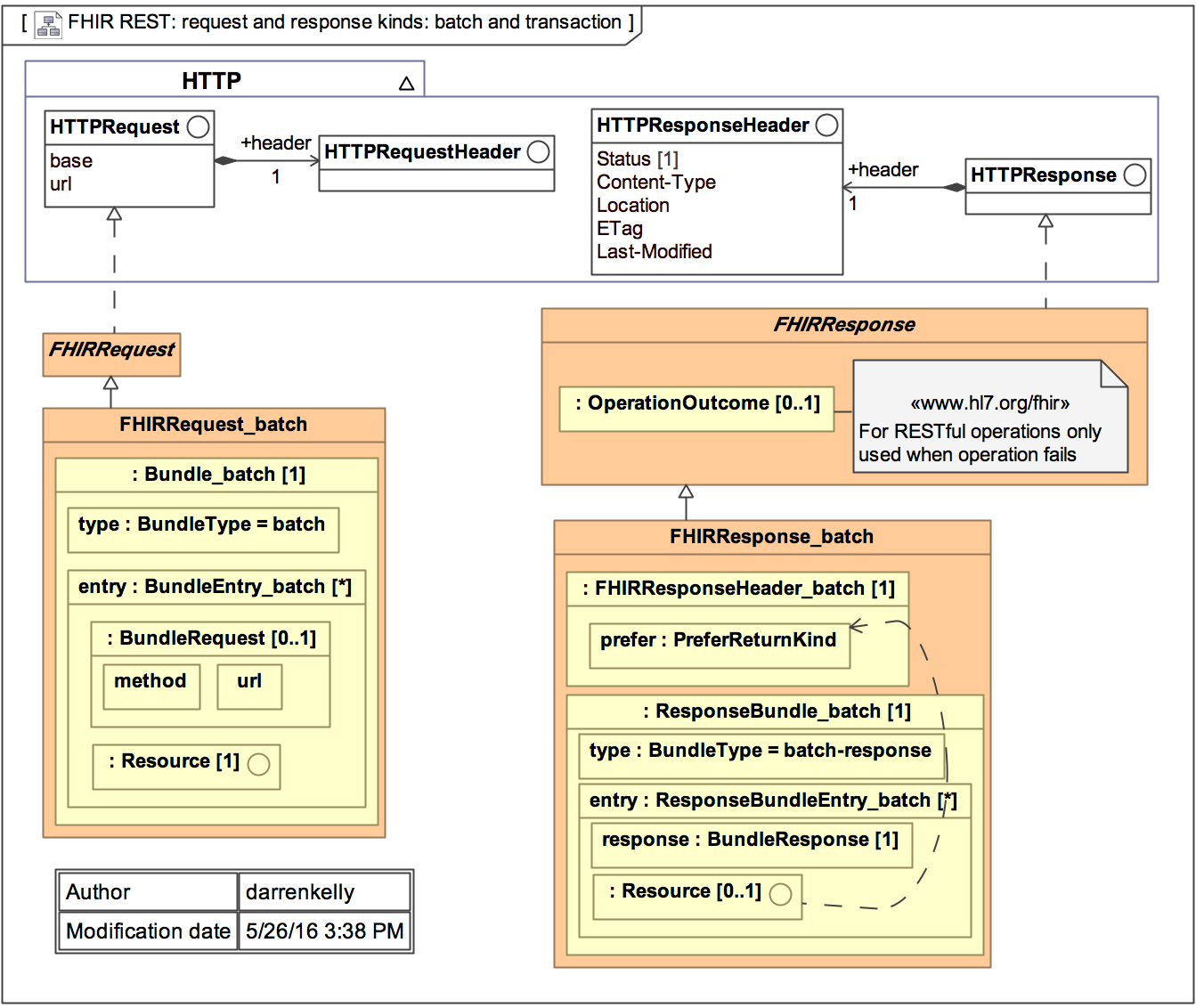
As mentioned, FHIR resources are optimized for stateless transactions with RESTful APIs. Although this is not the only way FHIR resources can be used, these types of transactions are the only ones with defined interfaces and behaviors in the FHIR specification.
FHIR transactions follow a simple request and response transaction pattern. The request and response can be for a single payload or can operate as batch. The payload or a request and response consist of a header and the content of interest. See diagram below for details.
2.16.6.3 Security
(section to be filled out) (but see Security in the meantime).
Example Use Cases Using FHIR
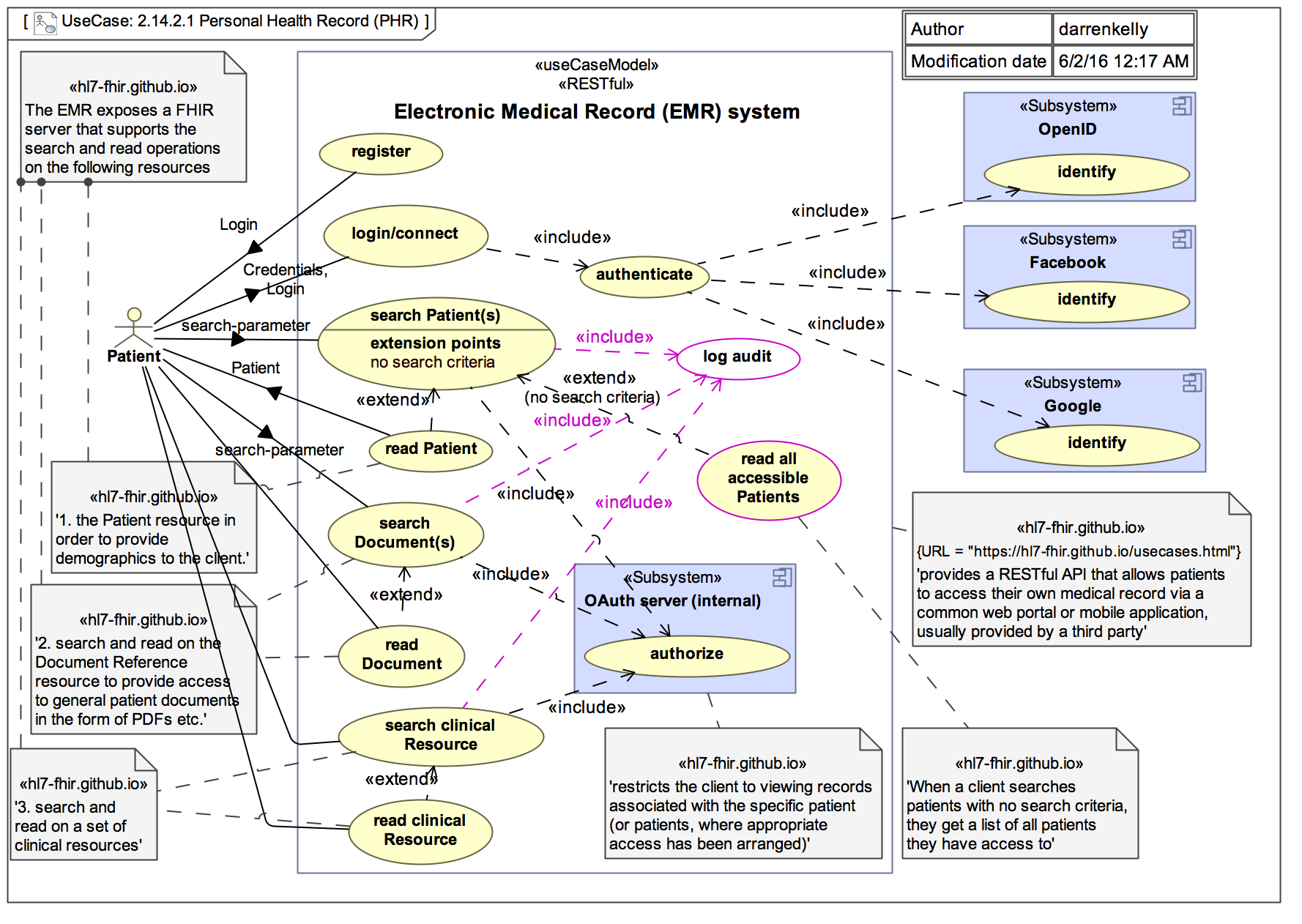
For illustrative purposes, the following diagram depicts a simple use case of a patient accessing their personal health record
(portal) enabled by an underlying electronic medical record (EMR) system. The EMR plays the role of the FHIR server in this example.
The pre-conditions for this use case are:
the EMR implements the necessary FHIR APIs
the EMR implements the necessary authentication and authorization mechanisms
the patient is successfully authenticated and authorized to access FHIR resources
The basic flow of the use case is that the patient registers (if required), logs in, enters search criteria to identify a patient or
patients of interest (the patient is most like themselves in this use case), retrieves clinical documents for the patient and
retrieves clinical resources for the patient. The use cases utilize the GET methods on the iServeInstance interface and works
with the following types of FHIR resources:
The Patient resource
One or more document resource(s)
One or more clinical resource(s)
Although this example use case is very simple, more complex transactions using a combination of GETs, PUTs and DELETEs against resources and metadata can be envisioned. However, the exact details of these use cases including which methods are used, the orchestration of methods and the specific resources involved are outside the scope of the FHIR specification.
2.16.7 Outstanding Issues
Resource Consistency and Granularity – there is nothing intrinsically prohibiting one resource from duplicating the same information
as another resource. Further, there is nothing prohibiting resources with the same information from defining and modeling the data elements
differently.
HL7 has a number of processes to ensure that resources are consistently designed, but the question is when to be consistent within the
specification, and when to be consistent with the real world practices of healthcare - these are sometimes in conflict with each other.
Resource granularity is a related potential problem as there are variations in the size, complexity and comprehensiveness of the existing resources.
Further, the degree to which the FHIR specification can impose consistency is limited to how much agreement can be gained across various communities.
While the Implementers Safety Check List and the Considerations for
FHIR Resource Considerations provide guidance and promote consistency,
rules for achieving complete consistency of both content and granularity amongst resources are neither completely defined nor completely enforced.
Considering that FHIR is still a new and emerging standard, an over-abundance of constraint and rigor has been avoided to maximize
initial adoption. Further, there is a natural tension between consistency and an architectural virtue and the practicalities of supporting the real
practice of health care. Considering that FHIR ultimately is a reflection of the health
business processes it supports, FHIR will always carry forward some of the data discrepancies, inconsistencies and gaps that are present in the
practice of healthcare across different organizations and practitioners. Nonetheless, the
issues of resource consistency and granularity is a topic that gets considerable ongoing discussion, and may change as FHIR approaches a final
normative standard and as FHIR adoption approaches a level
where more control is warranted, or more information/process consistency emerges in the existing healthcare systems.
Resource References – there are currently a lack of strict rules for what resources should be referenced by other resources and under what circumstance.
There is potential for ambiguity, duplication, inaccurate and/or conflicting information communicated by a resource graph (a collection of linked resources).
Imagine the scenario where Resource Type A (e.g., procedure) references Resource Type B (e.g., encounter) and Resource Type C (e.g., patient), and Resource Type B (e.g., encounter)
also references Resource Type C (e.g., patient). In this scenario, is a reference to Resource A to Resource C meant to provide the same information as the reference
from Resource B to Resource C? If so, is this duplication of information problematic? Note that this is not unique to FHIR - it is an innate property of information systems.
If an actual instance of A, and the B that it references, reference different instances of Resource C (e.g. the procedure references patient X and an encounter for patient Y),
how does the system know that the references are intentionally different versus an error or data anomaly? The problem is that there is limited ability to describe the
intent of the reference which leads to the possibility of ambiguity and error. The Linkage resource can be used to help with this problem,
but additional capabilities may be considered in the future to allow systems to address referential integrity.
Conditional Semantics – Currently, the constraints for element definitions including things like data types, value sets, optionality and cardinality are
defined at design time with limited consideration for variable run-time semantics. Imagine the scenario where the value of Data Element Y (e.g., “intolerance type”) is
constrained differently depending on the value of Data Element X (e.g., “causative agent”) in a given instance of a resource. For example, if the instance of
an Intolerance Resource has the “intolerance type” data element populated with “food intolerance”, then “causative agent” should be constrained to only valid
values for this value set (e.g., valid foods instead of medications or environmental agents). Tools for addressing deep semantic consistency in this
regard are only gradually developing.
Business Rule Enforcement and Validation – As governance increases and more resource rules are defined, it may be advantageous to have a resource validation
tool that checks for things like resource consistency, duplication, referential integrity, circular or nonsensical references, and other defined and approved
validation rules. Once rules are agreed to, this level of automation can help address the other issues outlined above. These kinds of facilities are planned
for the future.

 Foundation
Foundation . Page versions: R5 R4B R4 R3
. Page versions: R5 R4B R4 R3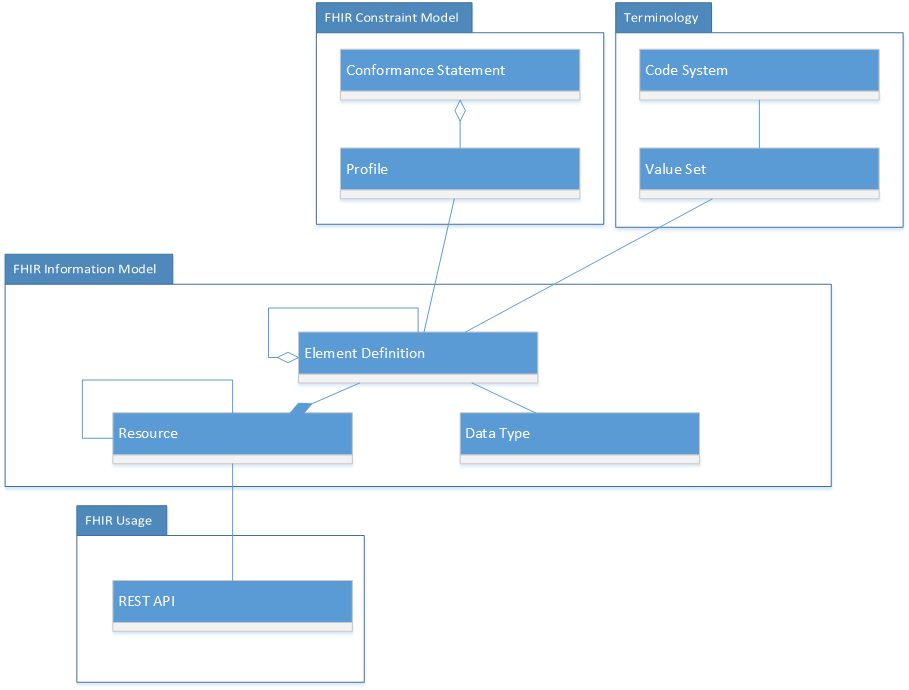
 |
Propose a change
|
Propose a change