

Consolidated CDA (C-CDA)
5.0.0 - STU5
![]()
Consolidated CDA (C-CDA)
5.0.0 - STU5
![]()
This page is part of the CCDA: Consolidated CDA Release (v5.0.0: CCDA 5.0) generated with FHIR (HL7® FHIR® Standard) v5.0.0. This is the current published version. For a full list of available versions, see the Directory of published versions
Clinical Document Architecture (CDA) is the underlying standard that Consolidated Clinical Document Architecture (C-CDA) is derived from. The HL7 CDA is a document markup standard that specifies the structure and semantics of a clinical document (such as a discharge summary, progress note, procedure report) for the purpose of exchange. A CDA document is a defined and complete information object that can include text, images, sounds, and other multimedia content. It can be transferred within a message, and can exist independently, outside the transferring message.
CDA documents are encoded in Extensible Markup Language (XML). They derive their machine processable meaning from the HL7 RIM and use the HL7 Version 3 data types. CDA incorporates concepts from standard coding systems such as Systemized Nomenclature of Medicine Clinical Terms (SNOMED CT) and Logical Observation Identifiers Names and Codes (LOINC).
The CDA specification is richly expressive and flexible and is designed to be broad enough to cover the domain of clinical documents. Templates and implementation guides are used to constrain the CDA specification within a particular implementation and to provide validation rule sets that check conformance to these constraints.
For more detail about CDA, C-CDA’s underlying standard, please see the CDA Overview.
CDA can be constrained through creating rules which provide the semantic and syntactic rules for representing data elements. The “templated CDA” approach uses a library of modular CDA template definitions. Templates can be reused across any number of CDA document types, as shown in the following figure. Each template meets a defined purpose. Templates are managed over time through versioning. A template version is a specific set of conformance constraints (rules) designed to meet the template’s purpose.
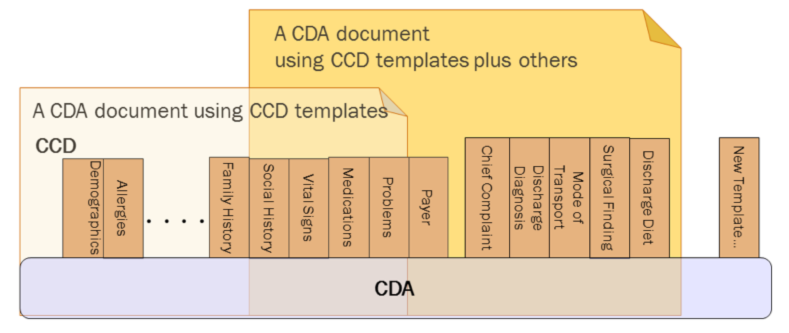
The types of templates defined in this guide are Document, Section, Entry, and Participation and Other:
A CDA implementation guide (such as this one) defines templates of these various types specifying them to represent particular use cases and/or data elements.
Regarding implementation, the creator of a CDA instance populates the template identifier (templateId) field to assert conformance to a given template version. On the receiving side, the recipient can then not only test the instance for conformance against the CDA Extensible Markup Language (XML) schema, but also test the instance for conformance against asserted templates, historically, using custom schematron.
StructureDefinition publishing provides inherent validation and versioning without needing to develop custom schematron. However, the validity and reliability of this has not been fully tested and there is wide use of schematron in the industry. This current publication retains the templateIds, as a secondary StructureDefininition.id, but the publication does not rely on it for QA and validation within the specification itself. Tooling is being investigated to support instance validation using inherent processes that can be made available for the industry to leverage in sending and receiving instances.
C-CDA templates are identified with a templateId. The templateId is a two-part identifier that consists of a root that is an Object Identifier (OID) and an optional date extension. The root identifies the named template and the extension identifies the version of that template. Initially C-CDA templates did not include versions so the templateId/@extension attribute was not used. Some of these templates are still present on C-CDA 3.0. See Template Versioning for more explanation of the differences in versioning from previous versions of the guide.
In CDA. templates are declared to be either Open or Closed templates. In Open templates, all of the features of the CDA R2 base specification are allowed except as constrained by the templates. Open templates allow HL7 CDA implementers to develop additional structured content not constrained within this guide. HL7 encourages implementers to bring their use cases forward as candidate requirements to be formalized in a subsequent version of the standard to maximize the use of shared semantics. By contrast, a Closed template specifies everything that is allowed and nothing further may be included. There are only two templates in this version of C-CDA that are closed templates. Estimated Date of Delivery and Medication Free Text Sig. Closed templates are indicated by a "sig-closed": constraint.
Conformance statements inherited from the pdf publications (C-CDA R2.1 and prior and the Companion Guides) may be identified with unique identifiers (e.g., CONF:86-7345) produced by the previous publication tooling. These historical identifiers are now present on the “Detailed Description pages” and on the “Description & Constraints” column on the “Formal Views of Profile” and are expected to be removed in a future version of C-CDA.
This StructureDefinition publication of C-CDA adheres to the FHIR Conformance Rules. C-CDA StructureDefinitions define the minimum elements, extensions, vocabularies, and ValueSets that SHALL or SHOULD be present and constrains the way the elements are used when using the template.
The Template elements consist of SHALL (Mandatory), SHOULD (Best Practice), and USCDI Requirements elements. SHALL elements have a minimum cardinality of 1 (min=1). SHOULD elements are identified with a minimum cardinality of 0 (min=0) and a “C” with a constraint (invariant), (e.g. should-NPI (the constraint identifier) with the description “SHOULD be NPI”). Additional SHALL and SHOULD requirements are represented as constraints (invariants) with a severity of error (Mandatory) or warning (Best Practice). USCDI classes or data elements are flagged with (USCDI) on the CDA element and/or on an entire template and identify data elements required for ONC Health IT Certification.
Terminology Conformance All terminology constraints are represented as value set or code system bindings in the template. All bound value sets are represented by the name of the value set and this name is a direct hyperlink to the appropriate value set found in National Library of Medicine’s Value Set Authortiy Center (VSAC) which can also be retrieved as a downloadable package: Value Set Authority Center(VSAC)C-CDA Value Sets, in HL7 Terminology Home (THO) or within the US Core Implementation Guide US Core Terminology. SHALL bindings are represented as Required bindings while SHOULD and MAY bindings are represented as Preferred bindings.
CDA establishes a "context" in its header, which generally applies to the entire document but can be overridden in specific sections or entries. This context encompasses various components such as Author, Confidentiality, and Human Language, ensuring that information (like the subject of observations or authorship) remains consistent throughout the document unless explicitly altered. Notably: The CDA Header sets initial context, with certain participants (e.g., Author, Confidentiality) having propagating values applicable across the document unless overridden. CDA participants that have propagating values:
Context components can be overridden at various levels:
Contextual information trickles down from broader ("outer") contexts to more specific ("nested") contexts and can be specifically overridden at each level. In instances of unknown or imprecise context, overriding with a null value is employed.
The objective of the CDA Context rule is to render practices explicit in relation to the RIM (Reference Information Model), ensuring computerized understanding of document context aligns with human interpretation. This approach maintains coherent information flow and facilitates logical data propagation and override when necessary within nested document components.
A CDA participant (e.g., Author, Informant), is an association between an Act and a Role with an Entity playing that Role. Each Entity (in a Role) involved in an Act in a certain way is linked to the Act by one Participation-instance. The kind of involvement in the Act is specified by the Participation.typeCode.
CDA principles when asserting participations include:
It's essential for a recipient to ascertain the status of the data in a clinical statement, which can encompass various items such as problems, medication administrations, and more. The precise determination hinges upon the combined factors from multiple components of the act, like the statusCode and effectiveTime. Key principles to understand when delineating or interpreting the status of a clinical statement are:
Role of Act.statusCode:
Interplay Between Act.statusCode and Act.moodCode:
Relationship Between Act.statusCode and Act.effectiveTime:
Metadata carried in the header may already be available for rendering from EHRs or other sources external to the document. An example of this would be a doctor using an EHR that already contains the patient’s name, date of birth, current address, and phone number. When a CDA document is rendered within that EHR, those pieces of information may not need to be displayed since they are already known and displayed within the EHR’s user interface.
Good practice recommends that the following be present whenever the document is viewed:
In Operative and Procedure Notes, the following information is typically displayed in the EHR and/or rendered directly in the document:
HL7 has created a style sheet available for the community to use, as is, or to customize for their vendor’s implementations. The HL7 CDA style sheet is housed in the CDA-core-xsl GitHub repository.
Section templates are open, allowing for the inclusion of subsections to enhance the organization of narrative content. This structured approach may facilitate a more efficient and less cumbersome interpretation of the information. Entries linked to the primary section can also be nested within its relevant subsections. When processing sections in a CDA document, machines should be prepared to handle potential subsection divisions.
To ensure clarity and minimize complexity, it's advisable to limit subsection depth to three levels: a main section followed by up to two subsection layers.
Subsections utilize codes from the LOINC Document Ontology to signify the information's context within them. When designating entries for a particular subsection, a translation of the entry's primary code element can correspond to the LOINC code associated with that subsection. While this method of applying translation to entry.code diverges from typical vocabulary translation practices, it may aid in the systematic categorization of entries, facilitating machine processing in alignment with the intended document structure.
C-CDA recommends that clinical statements include a link between the narrative (section.text) and coded clinical data (entry). Please see the Narrative Block section in the StructureDefinition publication of CDA for implementation details about referencing. Each template contains conformance statements recommending (SHOULD) textReferencing unless explicitly prohibited.
Information technology solutions store and manage data, but sometimes data are not available. An item may be unknown, not relevant, or not computable or measurable, such as where a patient arrives at an emergency department unconscious and with no identification.
Many C-CDA templates will stipulate that a piece of information is required (e.g., via a SHALL conformance verb). However, in most of these cases, the CDA standard provides an “out”, allowing the sender to indicate that the information isn’t known.
Here, we provide guidance on representing unknown information. Further details can be found in the HL7 V3 Data Types Release 1 specification that accompanies the CDA R2 normative standard. However, it should be noted that the focus of Consolidated CDA is on the unambiguous representation of known data, and that in general, the often subtle nuances of unknown information representation are less relevant to the recipient.
Many fields in C-CDA contain a “@nullFlavor” attribute, used to indicate an exceptional value. Some flavors of Null are used to indicate that the known information falls outside of value set binding constraints. Not all uses of the @nullFlavor attribute are associated with a case in which information is unknown. Allowable values for populating the attribute give details about the reason the information is unknown, as shown in the following example.
nullFlavor Example
<birthTime nullFlavor=”UNK”/> <!--Sender does not know the birthTime, but a proper value is applicable -->
Use null flavors for unknown, required, or optional attributes:
| NI | No information. This is the most general and default null flavor. |
| NA | Not applicable. Known to have no proper value (e.g., last menstrual period for a male). |
| UNK | Unknown. A proper value is applicable, but is not known. |
| ASKU | Asked, but not known. Information was sought, but not found (e.g., the patient was asked but did not know). |
| NAV | Temporarily unavailable. The information is not available, but is expected to be available later. |
| NASK | Not asked. The patient was not asked. |
| MSK | There is information on this item available but it has not been provided by the sender due to security, privacy, or other reasons. There may be an alternate mechanism for gaining access to this information. |
| OTH | The actual value is not an element in the value domain of a variable. (e.g., concept not provided by required code system). |
The list above contains those null flavors that are commonly used in clinical documents. For the full list and descriptions, see the nullFlavor vocabulary domain in the CDA R2 normative edition.10.
Any SHALL, SHOULD or MAY conformance statement may use nullFlavor, unless the nullFlavor is explicitly disallowed (e.g., through another conformance statement which includes a SHALL conformance for a vocabulary binding to the @code attribute, or through an explicit SHALL NOT allow use of nullFlavor conformance).
Attribute Required (nullFlavor not allowed)
Allowed nullFlavors When Element is Required (with xml examples)
<entry>
<observation classCode="OBS" moodCode="EVN">
<id nullFlavor="NI"/>
<code nullFlavor="OTH">
<originalText>New Grading system</originalText>
</code>
<statusCode code="completed"/>
<effectiveTime nullFlavor="UNK"/>
<value xsi:type="CD" nullFlavor="OTH">
<originalText>Spiculated mass grade 5</originalText>
</value>
</observation>
</entry>
If a sender wants to state that a piece of information is unknown, the following principles apply:
Unknown Medication Example
<entry>
<text>patient was given a medication but I do not know what it was</text>
<substanceAdministration moodCode="EVN" classCode="SBADM">
<consumable>
<manufacturedProduct>
<manufacturedLabeledDrug>
<code nullFlavor="NI"/>
</manufacturedLabeledDrug>
</manufacturedProduct>
</consumable>
</substanceAdministration>
</entry>
Unknown Medication Use of Anticoagulant Drug Example
<entry>
<substanceAdministration moodCode="EVN" classCode="SBADM" nullFlavor="NI">
<text>I do not know whether or not patient received an anticoagulant drug</text>
<consumable>
<manufacturedProduct>
<manufacturedLabeledDrug>
<code code="81839001" displayName="anticoagulant drug" codeSystem="2.16.840.1.113883.6.96" codeSystemName="SNOMED CT"/>
</manufacturedLabeledDrug>
</manufacturedProduct>
</consumable>
</substanceAdministration>
</entry>
No Known Medications Example
<entry>
<substanceAdministration moodCode="EVN" classCode="SBADM" negationInd=”true”>
<text>No known medications</text>
<consumable>
<manufacturedProduct>
<manufacturedLabeledDrug>
<code code="410942007" displayName="drug or medication" codeSystem="2.16.840.1.113883.6.96" codeSystemName="SNOMED CT"/>
</manufacturedLabeledDrug>
</manufacturedProduct>
</consumable>
</substanceAdministration>
</entry>
Value Known, Code for Value Not Known
<entry>
<observation classCode="OBS" moodCode="EVN">
…
<value xsi:type="CD" nullFlavor="OTH">
<originalText>Spiculated mass grade 5</originalText>
</value>
</observation>
</entry>
Value Completely Unknown
<entry>
<observation classCode="OBS" moodCode="EVN">
…
<value xsi:type="CD" nullFlavor="UNK"/>
</observation>
</entry>
Value Known, Code in Required Code System Not Known But Code from Another Code System is Known
<entry>
<observation classCode="OBS" moodCode="EVN">
…
<value xsi:type="CD" nullFlavor="OTH">
<originalText>Spiculated mass grade 5</originalText>
<translation code="129742005" displayName="spiculated lesion" codeSystem="2.16.840.1.113883.6.96" codeSystemName="SNOMED CT"/>
</value>
</observation>
</entry>
Some C-CDA templates are designed to be more specific and eliminate the “out” provided by the CDA standard. When these templates stipulate that a piece of information is required (e.g., via a SHALL conformance verb), the allowable null flavor or data absent reason concepts are constrained as part of the vocabulary binding on the code attribute of the data element.
When the information being modeled requires the set of allowable reasons that the data may be absent be constrained along with the allowable concepts for the data itself, this can be accomplished using the following method. The allowable concepts from the nullFlavor codeSystem as well as those needed from the Data Absent Reason codeSystem are incorporated into the value set bound directly to the code attribute of the element in the model that is being constrained. This allows the modeling for standardized answers to be more precise. It establishes the full range of allowable answers including the permitted concepts for “missing” information.
Binding the value set to the code attribute of the element prevents the use of the nullFlavor attribute in the model and thus avoids the possibility of contradictory information being added into the model.
This constraint pattern can be used to clarify when only certain NullFlavor concepts are permitted or when a mix of NullFlavor and DataAbsentReason concepts are allowed in addition to the range of expected data concepts.
CDA defines a standard schema, based on the HL7 RIM, for all CDA documents. The XML Schema is designed to achieve the intentions of the CDA architecture. Please see section The "A" in CDA for more information. When there is a need to represent information where there is no suitable representation in the schema, the CDA standard permits extensions to be developed. The HL7 Structured Documents Work Group (SDWG) maintains a complete list of CDA R2 extensions that are approved for use within the sdtc namespace. These extensions exist in the stdc schema. The most current CDA Schema is housed in the HL7 CDA GitHub repository.
For any Required binding, any valid expansion of a value set is conformant; any version of the value set used with any version of the needed code systems. If an implementation or dependent IG needs to be more restrictive, then additional constraints must be added, such as adding a specific value set version and or code system version in the binding.
In all C-CDA Document templates, at least one section SHALL contain clinically relevant information. A document that contains only empty sections (nullFlavor = NI) is unhelpful to providers and fails to meet the essential purpose of conveying meaningful clinical data. Such documents contribute to inefficiencies and frustration in the healthcare process, as they do not provide the necessary information for informed decision-making
Although this guide contains a lot of examples, the CDA Examples Task Force maintains even more examples. The CDA Example Search repository can be used to find examples for specific templates.
IG © 2019+ Health Level Seven. Package hl7.cda.us.ccda#5.0.0 based on FHIR 5.0.0. Generated 2026-06-13
Links: Table of Contents |
QA Report
| Version History  |
|
 |
Propose a change
|
Propose a change