DSTU2 Ballot Source
This page is part of the FHIR Specification (v0.5.0: DSTU 2 Ballot 2). The current version which supercedes this version is 5.0.0. For a full list of available versions, see the Directory of published versions  . Page versions: R5 R4B R4 R3 R2
. Page versions: R5 R4B R4 R3 R2

The base FHIR specification (this specification) describes a set of base resources, frameworks and APIs that are used in many different contexts in healthcare. However there is wide variability between jurisdictions and across the healthcare eco-system around practices, requirements, regulations, education and what actions are feasible and/or beneficial.
For this reason, the FHIR specification is a "platform specification" - it creates a common platform or foundation on which a variety of different solutions are implemented. As a consequence, this specification usually requires further adaptation to particular contexts of use. Typically, these adaptations specify:
Note that because of the nature of the healthcare eco-system, there may be multiple overlapping sets of adaptations - by healthcare domain, by country, by institution, and/or by vendor/implementation.
Typically, adaptations (either actual implementations or specifications - often called "Implementation Guides") both restrict and extend APIs, resources and terminologies. FHIR provides a set of resources that can be used to represent and share the decisions that have been made, and allows implementers to build useful services from them. These resources are known as the conformance resources. These conformance resources allow implementers to:
These resources need to be used as discussed below, and also following the basic concepts for extension that are described in "Extensibility". For implementer convenience, the specification itself publishes its base definitions using these same resources.
The Conformance resource describes two different uses for profiles on resources: Resource Profiles and System Profiles. Resource Profiles are specified using Conformance.rest.resource.profile element and System Profiles are specified using Conformance.profile element.
These profiles describe the general features that are supported by the system for each kind of resource. Typically, this is the superset of all the different use-cases implemented by the system. This is a resource-level perspective of the system functionality.
These profiles describe the information handled/produced by the system on a per use case basis. Some examples of the uses for system profiles:
Typically, these profiles are a series of variations on the same set of resources - different use cases leading to handling the resources that represent them differently. These use-cases described above all pertain to system that produce and publish data, but the same concept applies to systems that consume data. For instance:
For producer and a consumer systems to exchange data successfully based on one of these system supported profiles, it's not enough to know that the systems happen to have system profiles that overlap for the use case of interest; the consumer must be able to filter the total set of resources made available by the producer system and deal only with the ones relevant to the use case.
As an example consider a laboratory system generating 1000s of reports a day. 1% of those reports are a particular endocrine report that a decision support system knows how to process. Both systems declare that they support the particular endocrine profile, but how does the expert system actually find the endocrine reports that it knows how to process?
One possible option is for the expert system to receive every single report coming from the lab system, check whether it conforms to the profile or not, and then decide whether to process it. Checking whether a resource conforms to a particular profile or not is a straight forward operation (on option is to use the provided tools for this), but this is very inefficient way - the expert system has to receive and process 100 times many resources as it uses. To help a consumer find the correct set of reports for a use-case, the producer of the resources also SHALL:
Beyond these requirements, a producer of resources SHOULD ensure that any data that would reasonably be expected to conform to the declared profiles SHOULD be published in this form.
DSTU note: there are many uninvestigated issues associated with system profiles. HL7 is actively seeking feedback from users who experiment with system profiles, and users should be prepared for changes to features and obligations in this area in the future.
A conformance resource lists the REST interactions (read, update, search, etc) that a server provides or that a client uses, along with some supporting information for each. It can also be used to define a set of desired behavior (e.g. as part of a specification or a Request for Proposal). The only interaction that servers are required to support is the Conformance interaction itself - to retrieve the server's conformance statement. Beyond that, servers and clients support and use whichever API calls are relevant to their use case.
In addition to the operations that FHIR provides, servers may provide additional operations that are not part of the FHIR specification. Implementers can safely do this by appending a custom operation name prefixed with '$' to an existing FHIR URL, as the Operations framework does. The Conformance resource supports defining what OperationDefinitions make use of particular names on an end point. If services are defined that are not declared using OperationDefinition, it may be appropriate to use longer names, reducing the chance of collision (and confusion) with services declared by other interfaces. The base specification will never define operation names with a "." in them, so implementers are recommended to use some appropriate prefix for their names (such as "ihe.someService") to reduce the likelihood of name conflicts.
Implementations are encouraged, but not required, to define operations using the standard FHIR operations framework - that is, to declare the operations using the OperationDefinition resource, but some operations may involve formats that can't be described that way.
Implementations are also able to extend the FHIR API using additional content types. For instance, it might be useful to read or update the appointment resources using a vCard based format. vCard defines its own mime type, and these additional mime types can safely be used in addition to those defined in this specification.
Extending and restricting resources (collectively known as 'constraining a resource') is done with a "StructureDefinition" resource, which is a statement of rules about how the elements in a resource are used, and where extensions are used in a resource.
What Structure Definitions can do when they are constraining existing resources and datatypes is limited in some respects:
The consequence of this is that if a profile mandates extended behavior that cannot be ignored, it must also mandate the use of a modifier extension. Another way of saying this is that knowledge must be explicit in the instance, not implicit in the profile.
As an example, if a profile wished to describe that a Procedure resource was being negated (e.g. asserting that it never happened), it could not simply say in the profile itself that this is what the resource means; instead, the profile must say that the resource must have an extension that represents this knowledge.
There is the facility to mark resources that they can only be safely understood by a process that is aware of and understands a set of published rules. For more information, see Restricted Understanding of Resources.
A "constraint" Structure Definition specifies a set of restrictions on the content of a FHIR resource or data type. A given structure definition is identified by its canonical URL, which SHOULD be the URL at which it is published. The following kinds of statements can be made about how an element is used:
All of these changed definitions SHALL be restrictions that are consistent with the rules defined in the base resource in the FHIR Specification. Note that some of these restrictions can be enforced by tooling (and are by the FHIR tooling), but others (e.g. alignment of changes to descriptive text) cannot be automatically enforced.
A structure definition contains a linear list of element declarations. The inherent nested structure of the elements is derived from the path value of each element. For instance, a sequence of the element paths like this:
defines the following structure:
<Root>
<childA>
<grandChild/>
</childA>
<childB/>
</Root>
or its JSON equivalent. The structure is coherent - children are never implied, and the path statements are always in order. The element list is a linear list rather than being explicitly nested because element definitions are frequently re-used in multiple places within a single definition, and this re-use is easier with a flat structure.
Structure Definitions may contain either a differential statement, a snapshot statement or both.
Differential statements describe only the differences that they make relative to another structure definition (which is most often the base FHIR resource or data type). For example, a profile may make a single element mandatory (cardinality 1..1). In the case of a differential structure, it will contain a single element with the path of the element being made mandatory, and a cardinality statement. Nothing else is stated - all the rest of the structural information is implied (note: this implies that a differential profile can be sparse, and only mention the elements that are changed, without having to list the full structure).
In order to properly understand a differential structure, it must be applied to the structure definition on which it is based. In order to save tools from needing to support this operation (which is computationally intensive - and impossible if the base structure is not available), a StructureDefinition can also carry a "snapshot" - a fully calculated form of the structure that is not dependent on any other structure. The FHIR project provides tools for the common platforms that can populate a snapshot from a differential.
StructureDefinitions can contain both a differential and a snapshot view. In fact, this is the most useful form - the differential form serves the authoring process, while the snapshot serves the implementation tooling. StructureDefinition resources used in operational systems should always have the snapshot view populated.
One common feature of constraining Structure Definitions is to take an element that may occur more than once (e.g. in a list), and split the list into a series of sublists, each with different restrictions on the elements in the sublist with associated additional meaning. In FHIR, this operation is known as "Slicing" a list. It is common to “slice” a list into sub-lists containing just one element, effectively putting constraints on each element in the list.
Here is an example to illustrate the process:
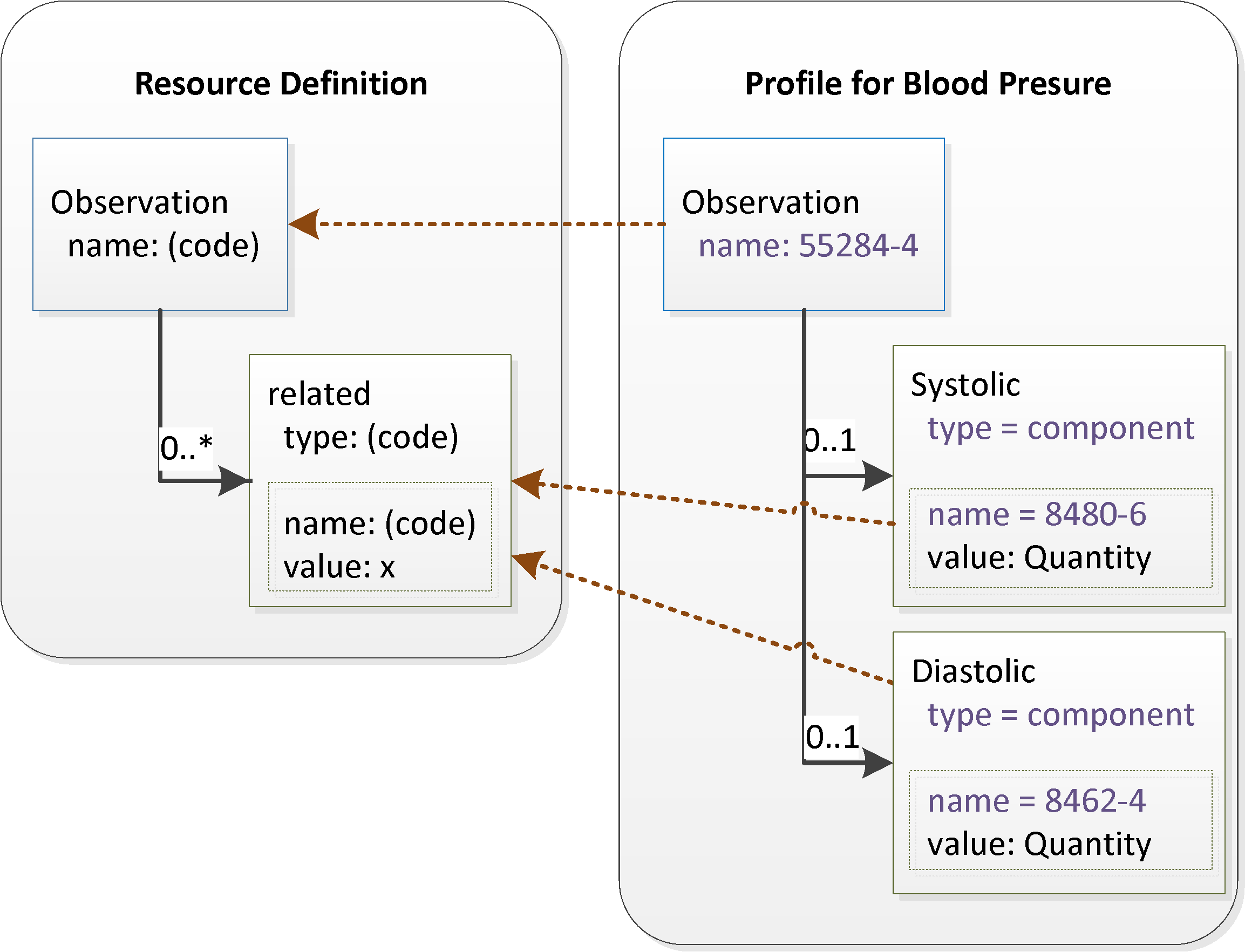
In this example, the base structure definition for the resource defines the "related" element which refers to another Observation which is related to the main Observation and which may occur multiple times. Each "related" element has a "type" element specifying the nature of the relationship (component, replacement, derivation etc.), and a "target" element which identifies the actual observation. In this diagram, for convenience, the contents of the target element are shown in the inner box instead of the showing the target reference explicitly. Also, to avoid adding clutter in this simplified example, the "name" attribute of Observation is shown as just a code not a full CodeableConcept.
The structure definition for Blood Pressure splits the related element list into 2 sublists of one element each: a systolic element, and a diastolic element. Each of these elements has a fixed value for the type element, and the structure definition also fixes the contents of the target observation as well, specifying a fixed LOINC code for the name and specifying that both have a value of type Quantity. This process is known as "slicing" and the Systolic and Diastolic elements are called "slices".
Note that when the resource is exchanged, the wire format that is exchanged is not altered by the constraining definition. This means that the item profile names defined in the structure definition ("systolic", etc. in this example) are never exchanged. A resource instance looks like this:
<Observation>
...
<related>
<type value="component"/>
<target ...> <!-- has the name "8480-6" -->
</related>
<related>
<type value="component"/>
<target ...> <!-- has the name "8462-4" -->
</related>
</Observation>
In order to determine that the first related item corresponds to "Systolic" in the structure definition, so that it can determine which additional constraints for a sub-list the item conforms, the system checks the values of the elements. In this case, the "name" element in the target resource can be used to determine which slice that target refers to. This element is called the “discriminator”.
In the general case, systems processing resources using a structure definition that slices a list can determine which slice an item in the list by checking whether its content meets the rules specified for the slice.
This requires for a processor to be able to check all the rules applied in the slice and to do so speculatively in a depth-first fashion. Neither of these is appropriate for an operational system, and particularly not for generated code. For this reason, a slice can nominate a set of fields that act as a "discriminator" - they are used to tell the slices apart.
When a discriminator is provided, the composite of the values of the elements nominated in the discriminator is unique and distinct for each possible slice and applications can easily determine which slice an item in a list corresponds to. The intention is that this can be done in generated code.
When a constraining structure nominates one or more discriminators, it SHALL fix the value of the element for each discriminator for each slice, or if the element has a terminology binding, it SHALL be associated with a complete binding with a closed Value Set reference that enumerates the possible codes in the value set. The structure definition SHALL ensure that there is no overlap between the set of values and/or codes in the value sets between slices.
It is the composite (combined) values of the discriminators that are unique, not each discriminator alone. For example, a slice on a list of items that are references to other resources could nominate fields from different resources, where each resource only has one of the nominated elements, as long as they are distinct across slices.
A structure definition is not required to nominate any discriminator at all for a slice, but those that don't identify discriminators are describing content that is very difficult to process, and so this is discouraged.
Within a structure definition, a slice is defined using multiple element entries that share a path but have distinct names. These entries together form a "slice group" that is:
The value of the discriminator element is a path name that identifies the descendant element using a dotted notation. For references, the path transitions smoothly across the reference and into the children of the root element/object of the resource. For extensions, an extension can be qualified with the URL of the extensions being referred to. There are two special names: @type, and @profile. Here are some example discriminators:
| Context | Discriminator | Interpretation |
| List.entry | item.reference.name | Entries are differentiated by the name element on the target resource - probably an observation, which could be determined by other information in the profile |
| List.entry | item.reference.@type | Entries are differentiated by the type of the target element that the reference points to |
| List.entry | item.reference.@profile | Entries are differentiated by a profile tag on the target of the reference, as specified by a structure definition (todo: how to do that?) |
| List.entry | item.extension["http://acme.org/extensions/test"].code | Entries are differentiated by the value of the code element in the extension with the nominated URL |
| List.entry.extension | url | Extensions are differentiated by the value of their url property (usually how extensions are sliced) |
| List.entry | item.reference.@type, item.reference.name | Extensions are differentiated by the combination of item.reference.name, and, if it has one, the name element. This would be appropriate for where a List might be composed of a Condition, and set of observations, each differentiated by its name - the condition has no name, so that is evaluated as a null in the discriminator set |
See also examples of slicing and discriminators.
An extension definition defines the url that identifies the extension and which is used to refers to the extension definition when it is used in a resource.
The extension definition also defines the context where the extension can be used (usually a particular path or a data type) and then defines the extension element using the same details used to profile the structural elements that are part of resources. This means that a single extension can be defined once and used on different Resource and/or datatypes, e.g. one would only have to define an extension for “hair color” once, and then specify it can be used on both Patient and Practitioner.
For further discussion of defining and using extensions, along with some examples, see Extensibility.
Once defined, an extension can be used in an instance of a resource without any Profile declaring that it can, should or must be, but Profiles can be used to describe how an extension is used.
To actually prescribe the use of an extension in an instance, the extension list on the resource needs to be sliced. This is shown in the extensibility examples
Note that the minimum cardinality of an extension SHALL be a valid restriction on the minimum cardinality in the definition of the extension. if the minimum cardinality of the extension is 1 when it is defined, it can only be mandatory when it is added to a profile. This is not recommended - the minimum cardinality of an extension should usually be 0.
Coded elements have bindings that link from the element to a definition of the set of possible codes the element may contain. The binding identifies the definition of the set of possible codes and controls how tightly the set of the possible codes is interpreted.
The set of possible codes is either a formal reference to a ValueSet resource, which may be version specific, or a general reference to some web content that defines a set of codes. The second is most appropriate where set of values is defined by some external standard (such as mime types). Alternatively, where the binding is incomplete (e.g. under development) just a text description of the possible codes can be provided.
Bindings have a property that define how the strongly implementations are required to use the set of codes. See Binding Strength.
Value Set resources can be used to define local codes (Example) and to mix a combination of local codes and standard codes (examples: LOINC, SNOMED), or just to choose a particular set of standard codes (examples: LOINC, SNOMED, RxNorm). Profiles can bind to these value sets instead of the ones defined in the base specification, following these rules:
| Binding Type in base specification | Matching Profile Properties | Customization Rules in Profiles |
| Complete | conformance = required, extensible = false | The value set can only contain codes contained in the value set specified by the FHIR specification |
| Incomplete | conformance = preferred and extensible = true | The value set can contain codes not found in the base value set. These additional codes SHOULD not have the same meaning as existing codes in the base value set |
| Example | conformance = example | The value set can contain whatever is appropriate for local use |
One property that can be declared on profiles that is not declared on the resource or data type definitions is "Must Support". This is a boolean property. If true, it means that systems claiming to conform to a given profile must "support" the element. This is distinct from cardinality. It is possible to have an element with a minimum cardinality of "0", but still expect systems to support the element.
The meaning of "support" is left deliberately ambiguous. Examples might include:
The specific meaning of "Must Support" for the purposes of a particular profile SHALL be described in the Profile.description or in other documentation for the implementation guide the profile is part of.
If creating a profile based on another profile, Must Support can be changed from false to true, but cannot be changed from true to false.
The final thing implementations can do is to define search criteria in addition to those defined in the specification itself. Search criteria fall into one of four categories:
Additional Search Parameters can be defined using the SearchParameter resource.
© HL7.org 2011+. FHIR DSTU (v0.5.0-5149) generated on Fri, Apr 3, 2015 14:36+1100.
Links: What's a DSTU? |
Version History |
Specification Map |
Compare to DSTU1 |
 |
Propose a change
|
Propose a change