FHIR for FAIR - FHIR Implementation Guide
1.0.0 - STU 1
![]()
FHIR for FAIR - FHIR Implementation Guide
1.0.0 - STU 1
![]()
This page is part of the FHIR for FAIR - FHIR Implementation Guide (v1.0.0: STU 1) based on FHIR v4.3.0. This is the current published version. For a full list of available versions, see the Directory of published versions 
| Official URL: http://hl7.org/fhir/uv/fhir-for-fair/ImplementationGuide/hl7.fhir.uv.fhir-for-fair | Version: 1.0.0 | |||
| Active as of 2022-09-28 | Computable Name: FhirForFairIG | |||
This guide aims to provide guidance on how HL7 FHIR can be used for supporting FAIR health data implementation and assessment to enable a cooperative usage of the HL7 FHIR and FAIR paradigms. Other kinds of health-related artefacts, such as clinical guidelines, algorithms, software, models are out of scope.
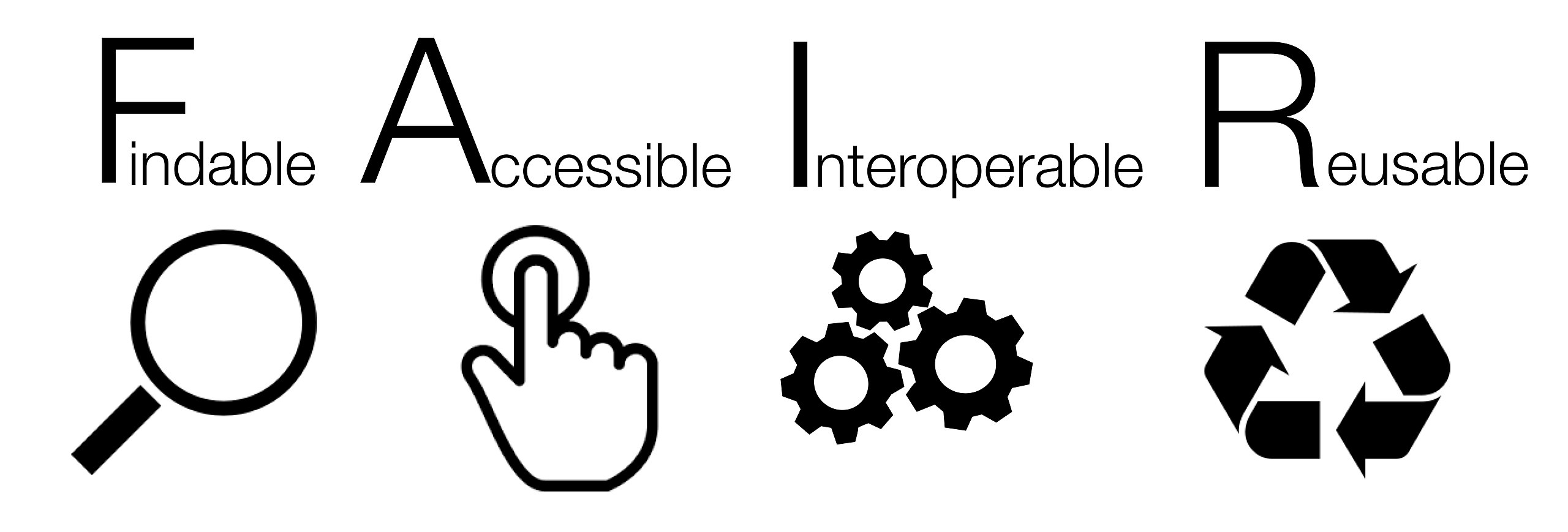
FAIR stands for Findable, Accessible, Interoperable and Reusable
Figure 1 – FAIR [SangyaPundir / CC BY-SA] |
The FAIR principles - a minimal set of community-agreed guiding principles and practices - were first introduced by Wilkinson et al (2016) in their seminal paper (doi.org/10.1038/sdata.2016.18).
The authors intent was to provide guidelines to improve the Findability, Accessibility, Interoperability, and Reuse (FAIR) of scientific data. Since their first introduction in 2016, FAIR principles were well received in international community and rapidly adopted by researchers.
The FAIR principles put specific emphasis on improving the ability of machines to automatically find and make use of the research (and other) data, as well as to support its reuse by the human researches. Therefore, acting as a guideline for those wishing to gain much greater value from the future reuse of their scientific data and relevant metadata.
We provide more detailed introduction to the FAIR data principles as well as the relationship to the HL7 FHIR standard in later sections of this IG.
There are existing concepts for operationalization and indicator for assessment of FAIRness , for example Research Data Alliance or EOSC recommendations. We discuss their implications in a special section HL7 FHIR and RDA Indicators.
The FAIRness for FHIR project, this Implementation Guide is part of, is intended to be the result of an active collaboration between the RDA and HL7 communities.
This project has as main goals to:
Facilitate the collaboration between the FAIR and the FHIR communities
Enable a cooperative usage of the FHIR standard and FAIR principles.
Support the assessment and implementation of FAIR health data by using HL7 FHIR

The audience for this Implementation Guide includes:
This guide has been structured in the following parts:
This Implementation Guide will be balloted as STU with the intention to go normative in subsequent ballot cycles.
| Role | Name | Organization |
|---|---|---|
| Author | Giorgio Cangioli | HL7 Europe |
| Author | Alicia Martinez-Garcia | Andalusian Health Service |
| Author | Ian Harrow | Pistoia Alliance |
| Author | Kees van Bochove | The Hyve |
| Author | Matthias Löbe | IMISE University of Leipzig |
| Author | Philip van Damme | Amsterdam UMC |
| Contributor | Anupama Gururaj | NIH/NIAID |
| Contributor | Belinda Seto | NIH |
| Contributor | Brian Alper | Computable Publishing LLC |
| Contributor | Catherine Chronaki | HL7 Europe |
| Contributor | Edward Eikman | |
| Contributor | Olga Vovk | Samvit Solutions |
| Contributor | Oya Beyan | Koeln University |
| Contributor | Steve Tsang | NIH/NIAID |
IG © 2020+ Health Level Seven International - SOA Work Group. Package hl7.fhir.uv.fhir-for-fair#1.0.0 based on FHIR 4.3.0. Generated 2022-09-28
Links: Table of Contents |
QA Report
| Version History |
 |
Propose a change
|
Propose a change