
PACIO Advance Directive Interoperability Implementation Guide
1.0.0 - STU 1
![]()
PACIO Advance Directive Interoperability Implementation Guide
1.0.0 - STU 1
![]()
This page is part of the PACIO Advance Directive Information Implementation Guide (v1.0.0: STU 1) based on FHIR (HL7® FHIR® Standard) R4. This is the current published version. For a full list of available versions, see the Directory of published versions
In ADI use cases, advance directive content created and updated will be represented using FHIR resources. The advance directives content is created and may be updated periodically by human actors.
For Content Type I, Person-authored advance directive information, there may be multiple human actors involved; however, there will only be one author which is the patient. Other human actors may include the healthcare agent, alternate healthcare agents, witness, notary, provider, and data enterer.
STU1 supports only Person-authored Advance Directives (ADI Content Type 1) documents. Future versions of this FHIR IG will address encounter-centric patient instructions, Content Type 2, and portable medical orders (such as DNRs or POLST/MOLST orders) for Content Type 3.
System actors are responsible for ensuring the advance directive information is correctly represented using FHIR resources. The technical actor is responsible for carrying out activities to conduct transition exchanges and make the information available.
Use cases in this IG will provide requirements for systems to use FHIR RESTful operations to both share (PUSH) and query & access (PULL) an individual’s advance directive content. In addition, it will cover technical requirements to update advance directive content. Finally, the use cases will provide guidance on information or document verification that what is available is current. In this use case, verification addresses situations when you have advance directive information available for access, and the system uses FHIR RESTful operations to determine if what is available is the most current version of that information or document. The details for these use cases are provided below.
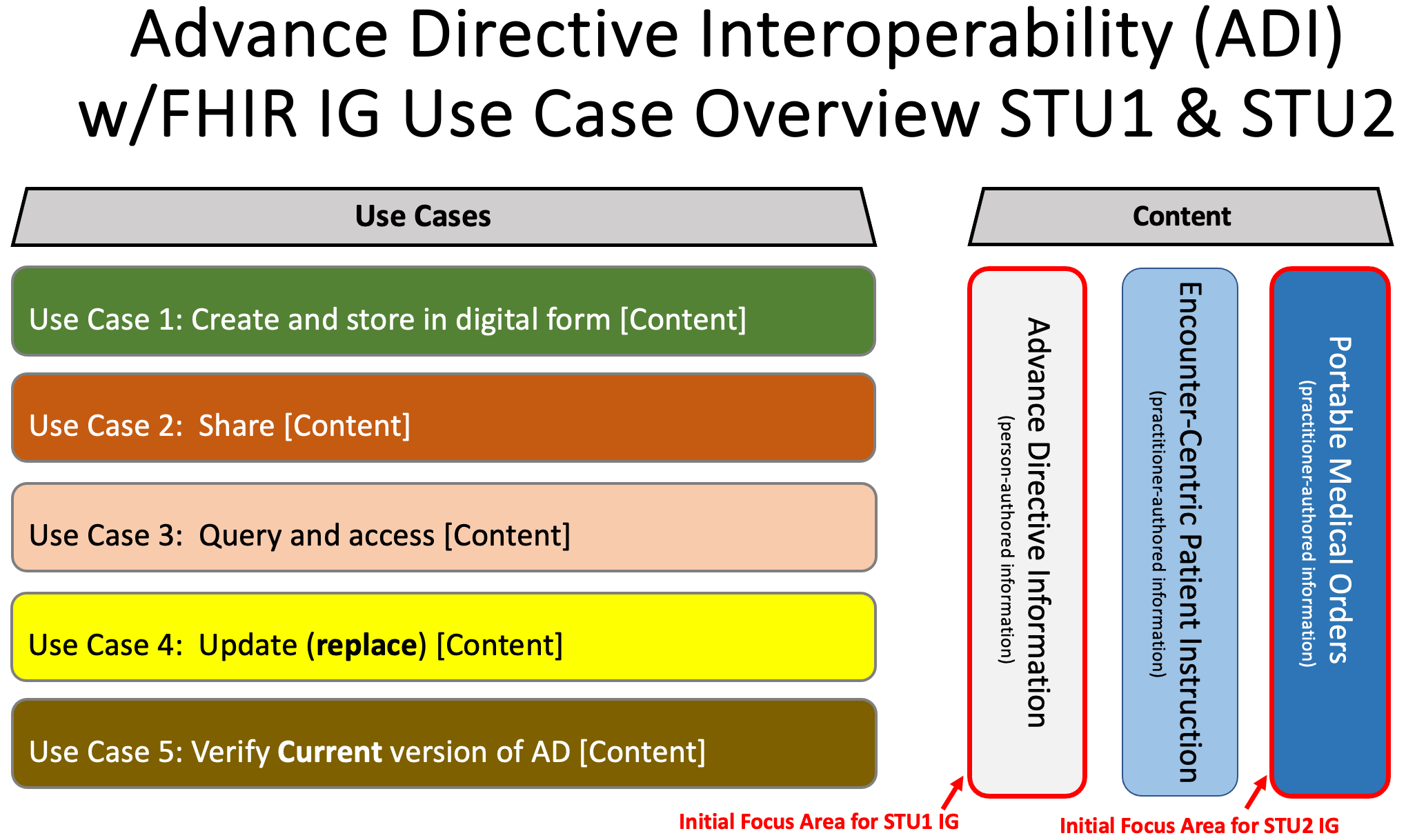
In Use Case 1, the person that wants to create their advance directive information in a digital form enters information in a content creator system. The content creator system ensures the information is stored and is available for the steps in the process that are described in the following use cases.

In Use Case 1, the process is started by a person seeking to create advance directive information in a digital form. The precondition for the process includes the system is able to capture and make the advance directive information available in standard-based digital format. The person creates advance directive information in the creator system, or optionally in a different system. Advance directive information is then stored and indexed by a custodian system responsible for information exchange. Finally, the advance directive information is made available in digital form within a Custodian System that can share the documents or information as a FHIR Client and/or support query as a FHIR Server.
In Use Case 2, the Content Creator system makes the person-authored advance directive information available via a Content Receiver system using a FHIR API. The Content Receiver system may be an end system or may be another Content Custodian system.
In Use Case 2, the process is started when a person wants to share their advance directive information with a human or system Content Receiver system. The person directs the Content Creator system to send the advance directive information to the Content Receiver through a FHIR based POST transaction. The Content Receiver will receive, store and process the advance directive information in their system.
Use-case 3 aims to enable provider access to advance directive information. It includes 3 steps:
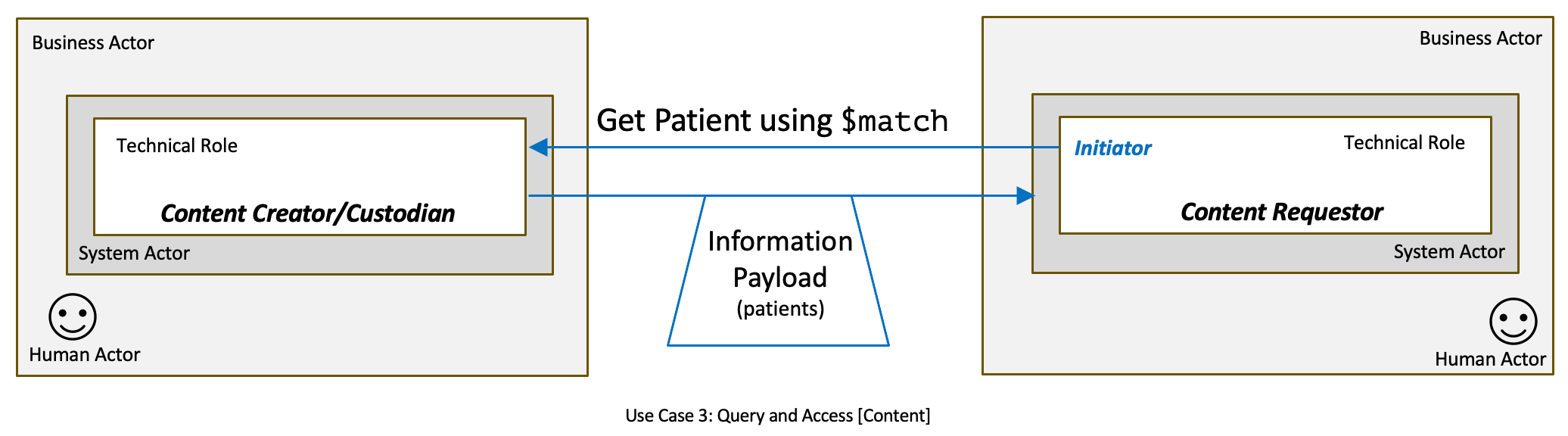
DocumentReference query, where the Content Requester system performs a GET DocumentReference request using the retrieved patient ID and additional search parameters like date, to the Content Custodian system. The Content Custodian system returns all matching DocumentReference information that has been authorized by the person to be eligible for access. This step returns a DocumentReference FHIR resource, which may or may not contain a binary-encoded document. Systems claiming conformance to this guide will not encode the document in the DocumentReference resource. Instead, the DocumentReference resource will reference a base64 binary attachment that contains the content.
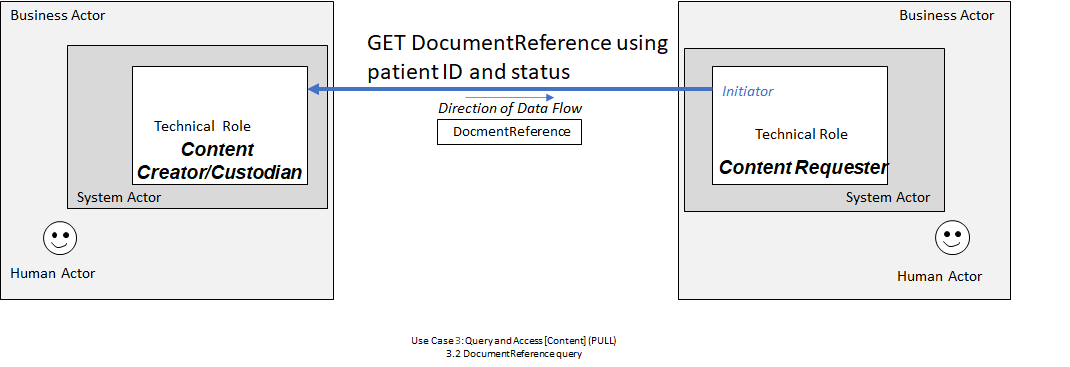
DocumentReference. This operation should be available using the same authentication and authorization that was used to retrieve the DocumentReference in a previous step of this process. Depending on the capabilities of the Content Custodian system or the format of the content, the retrieved Binary resource may need to be decoded. If the Content Custodian system supports it, and if the document content is in xml or json formatting, a request with an HTTP Accept Header of application/xml, text/xml, or application/json may retrieve the decoded document (which may be a FHIR Bundle with type = document).
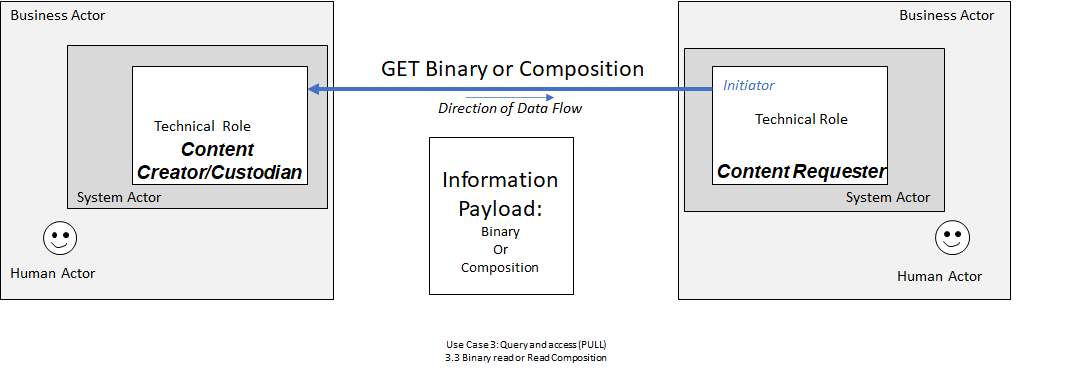
The Use Case 3 process describes message interactions between a Content Requester system, such as SMART on FHIR application, and a backend server. Note that while backend servers are supported by this IG, more specification requirement details related to backend server guidance will be coming in STU2.
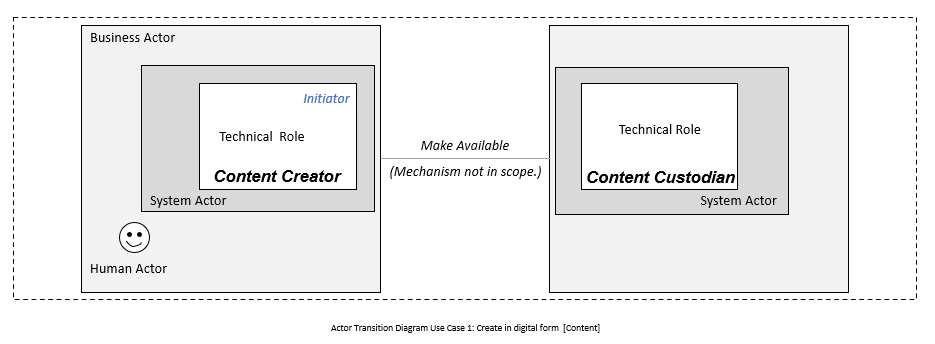
This process is started when a care team member of an organization wants a person’s advance directive information for treatment planning and decision-making. The Content Requester system must contact a Content Custodian system that offers a FHIR API for receiving requests for advance directive information. The care team member or human actor requesting the advance directive information must be authorized to access the person’s advance directive information on the Content Custodian system. The Content Custodian system may be accessed via a SMART Health Card or record endpoint in their digital insurance card.
The Content Requester system SHOULD use the FHIR operation $match for system-to-system patient querying, preferably with an enterprise master patient index (EMPI) to ensure a high threshold match and so that the right individual’s advance directive information is selected. An example of using the $match operation is shown here. The Content Custodian server returns all matched Patient resources to the Content Requester system. If more than one Patient resource is returned, the Content Requester will confirm which is the correct patient. The Content Requester system will then send a GET DocumentReference query using patient FHIR ID and any additional search parameters as supported and needed. The Content Custodian returns all matched DocumentReference resources to the Content Requester system. If more than one DocumentReference is returned, the Content Requester system will confirm which DocumentReference(s) are wanted. Finally, the Content Requester system will retrieve the wanted documents using a GET operation on the URL included in the DocumentReference resource and decode the document content if necessary.
Content custodian systems should be discoverable through the National Directory for Healthcare in the future. Implementers should be aware that a National Directory of Healthcare Providers and Services (NDH) FHIR Implementation guide is currently being developed by the FHIR at Scale Taskforce (FAST) and considered for adoption when the IG is formally published.
In Use Case 4, the process is started by a person wanting to update previously created advance directive information. The precondition for the process is that the Content Creator and Content Custodian systems are able to associate a new version of the ADI information and/or document(s) as active and possess the ability to mark prior ADI information and/or document(s) version as inactive.
In Use Case 4, the process is started by a person wanting to update previously created advance directive information. The precondition for the process is that the Content Creator and Content Custodian systems are able to associate a new version of the ADI information and/or document(s) as active and possess the ability to mark prior ADI information and/or document(s) version as inactive.
Note: FHIR Resource versioning is only used for error corrections.
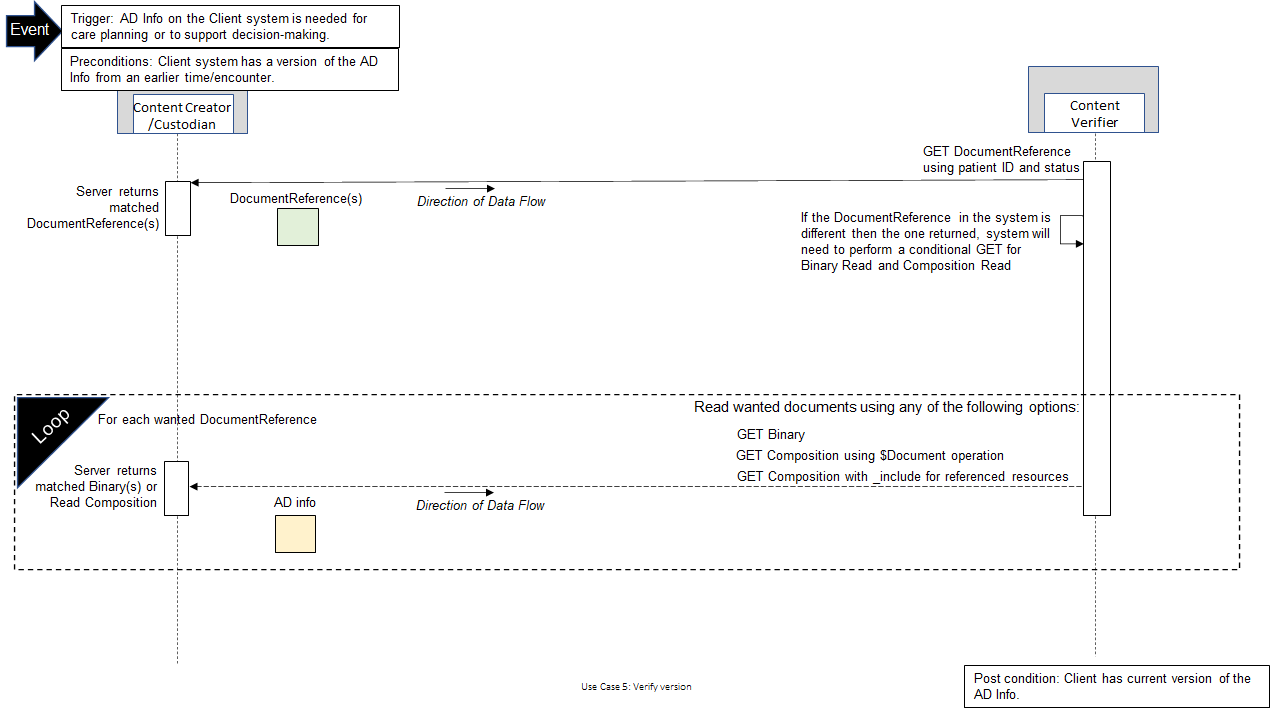
In Use Case 5, a Content Verifier has advance directive information which it previously received or retrieved.
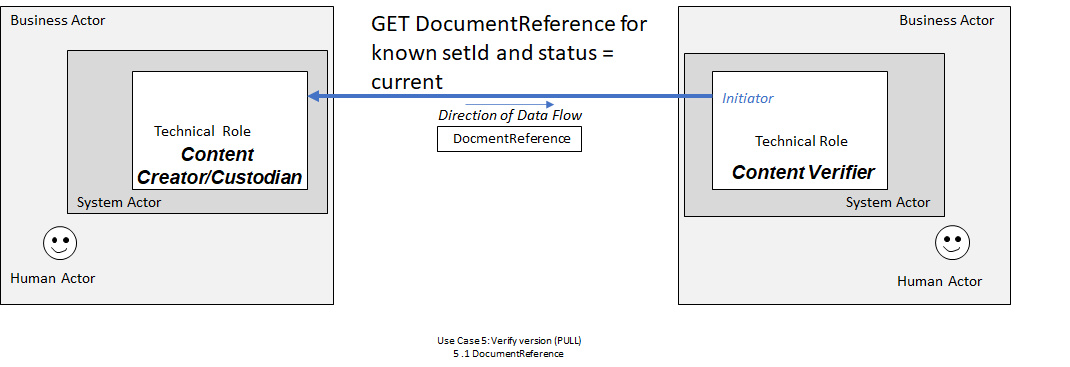
DocumentReference resource retrieved by the Content Retriever system in Step 1 has a status of superseded then the document that the Content Custodian system already knows of has been replaced, necessitating that the Content Verifier system perform a second query for a DocumentReference resource that has a relatesto.code of replaces and a reference to the superseded DocumentReference resource. The Content Verifier can then retrieve the document as described in step 3 of Use Case 3.
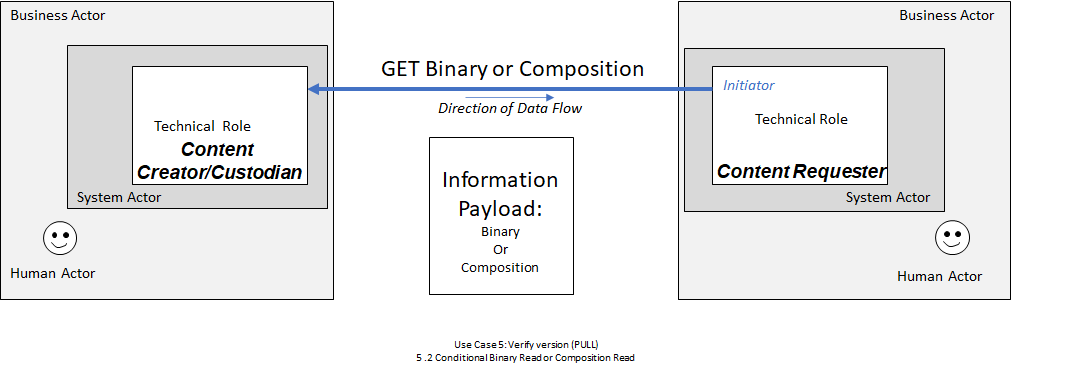
In Use Case 5, the process is started by a Content Verifier system that would like to confirm the current version of advance directive information is already stored, or not. The precondition for the process is the Content Verifier system has a version of advance directive information from an earlier time.
DocumentReference.DocumentReference returned contains a status of superseded then the document has been replaced and the Content Verifier system will perform a second query for a DocumentReference resource based on the relatesto.code referenced by the superseded DocumentReference resource.DocumentReference resource and decode the document content if necessary.
IG © 2021+ HL7 International / Patient Empowerment. Package hl7.fhir.us.pacio-adi#1.0.0 based on FHIR 4.0.1. Generated 2024-01-11
Links: Table of Contents |
QA Report
| Version History |
 |
Propose a change
|
Propose a change