STU 3 Ballot

 Foundation
FoundationThis page is part of the FHIR Specification (v1.6.0: STU 3 Ballot 4). The current version which supercedes this version is 5.0.0. For a full list of available versions, see the Directory of published versions  . Page versions: R5 R4B R4 R3
. Page versions: R5 R4B R4 R3

| FHIR Infrastructure Work Group | Maturity Level: N/A | Ballot Status: STU 3 |
At its core, FHIR contains two primary components:
In the healthcare domain, the set of “business objects” is not universally defined, but there is a notional and ongoing evolutionary, consensus-based process for standardizing on a core set of common business objects including things like “a patient”, “a procedure”, “an observation”, “on order”, etc. (see a list of defined resources). The FHIR specification provides a framework for defining these healthcare business objects (“resources”), for relating them together in a compositional manner, for implementing them in a computable form, and for sharing them across well-defined interfaces. The framework contains a verifiable and testable syntax, a set of rules and constraints, methods and interface signatures for “FHIR-aware” APIs, and specifications for the implementation of a server capable of requesting and delivering FHIR business objects.
From an operational perspective, HL7’s internal standards development and governance processes determine what constitutes a resource and which resources exist. However, the FHIR specification also provides a mechanism for contextualizing resources for specific needs within specific bounds (see Profiling Resources).
FHIR resources fits firmly within the information architecture domain and the FHIR APIs for data exchange address aspects of application architecture.
|
From a TOGAF perspective |
|
|
With regards to the Zachman Framework |
|
|
When considering the HL7 Services Aware Interoperability Framework (SAIF) |
|
FHIR’s primary purpose is to address interoperability with well-structured, expressive data models and simple, efficient data exchange mechanisms. In addition, FHIR aligns to the following architectural principles:
There are additional architecture principles related to consistency, granularity, referential integrity, and others that are not as well established or proven. See the section below on Outstanding Issues for details.
As discussed, FHIR’s principle components are resources and RESTful APIs. However, there is more to the FHIR specification including the components depicted below.
NOTE: The term “component” is used loosely to mean a part of something and does not intend to carry the specific meanings for this term provided by rigorous ontologies, modeling frameworks, or other architectural and organizational constructs. Diagrammatically, the components below are depicted below as UML classes. This is done purely to take advantage of the semantics afforded using this notation. FHIR is neither objected oriented in its modelling approach not are the component that make up the FHIR specification UML classes or objects in the formal sense. Likewise, the UML packages shown below are notional and used for organizational purposes only.
As shown in the diagram below, it is convenient to think of the FHIR specification as having components that address the following:

Component definitions:
It is impractical to model the entirety of health data in a single information model. Every modeling initiative in healthcare from HL7 version 2 message specifications, to the CIMI clinical models, to the domains within the FHIM, to FHIR resources decomposes the healthcare domain into smaller, more manageable sub-domains or information model snippets. With FHIR, each resource is essentially a snippet of the larger healthcare information domain. With this approach, it is important to have a framework or set of guidelines in place to assemble the snippets to reconstitute the business domain when needed and to ensure that the snippets are logically congruent with each other.
To this end, FHIR has an informative (non-normative) part of the specification that describes how to organize FHIR resources into logical packages or sub-domains in a manner that promotes the reuse and consistency of resources such that they can be assembled to reconstitute the health data domain in a logical, non-duplicative, unambiguous and non-conflicting manner. The fact that there is not a normative framework and set of constraints in place to guarantee this speaks to more to the variability that exists in healthcare practice today than it does to the ability of the FHIR specification to define such rules. See the section below on Outstanding Issues for more on this topic.
The non-normative information model organization framework currently in place for suggesting how resources should be organized relative to each other can be found on the FHIR Resource Considerations page .
Another useful tool for visualizing how FHIR resources are organized relative to each other can be found using the Resource Reference Visualization tool on clinFHIR .
A FHIR REST server is any software that implements the FHIR APIs and uses FHIR resources to exchange data. The diagram below describes the FHIR interface definitions. The methods are classified as:
Additional details on the FHIR APIs can be found at the FHIR RESTful Api and the Operations Framework.
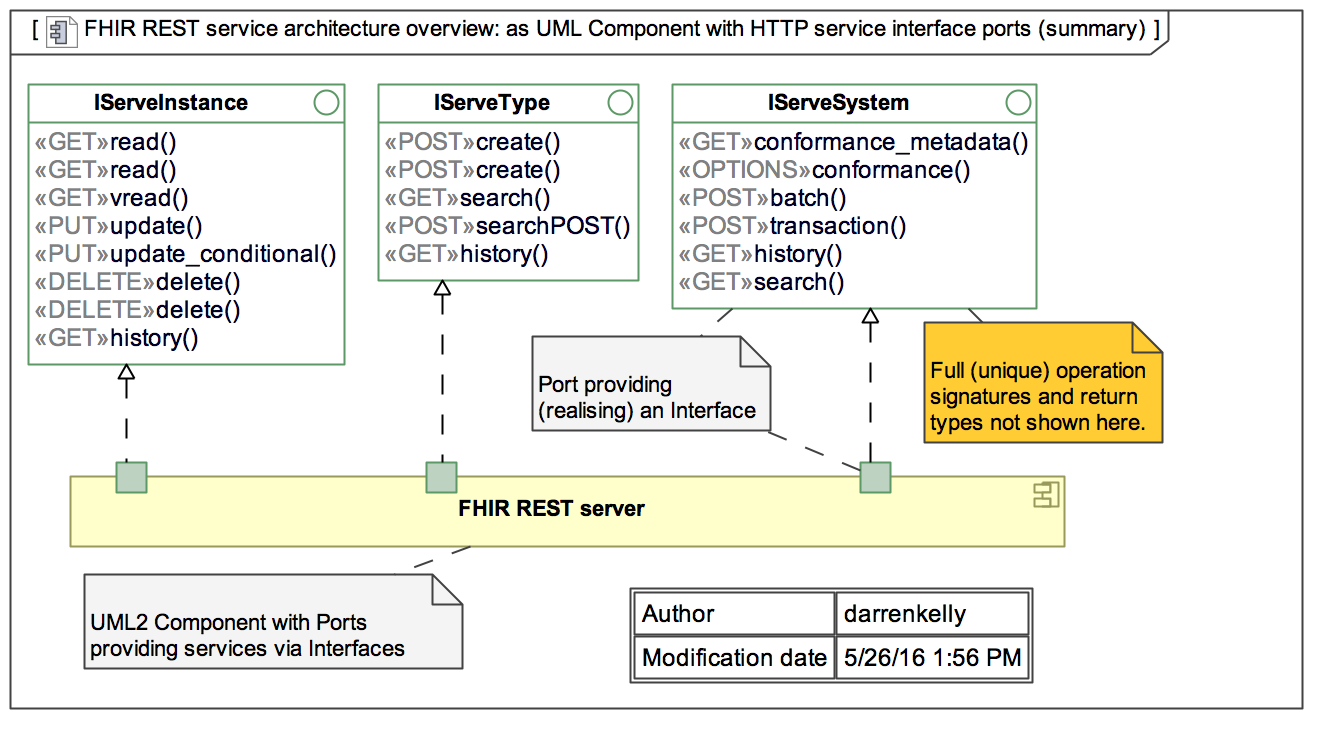
As mentioned, FHIR resources are optimized for stateless transactions with RESTful APIs. Although this is not the only way FHIR resources can be used, these types or transactions are the only ones with defined interfaces and behaviors in the FHIR specification.
FHIR transactions follow a simple request and response transaction pattern. The request and response can be for be for a single payload or can operate as batch. The payload or a request and response consists of a header and the content of interest. See diagram below for details.

(section to be filled out) (but see Security in the meantime).
Example Use Cases Using FHIR
For illustrative purposes, the following diagram depicts a simple use case of a patient accessing their personal health record (PHR) enabled by an underlying electronic medical record (EMR) system. The EMR plays the role of the FHIR server in this example.
The pre-conditions for this use case are:
The basic flow of the use case is that the patient registers (if required), logs in, enters search criteria to identify a patient or patients of interest (the patient is most like themselves in this use case), retrieves clinical documents for the patient and retrieves clinical resources for the patient. The use cases utilizes the GET methods on the iServeInstance interface and works with the following types of FHIR resources:

Although this example use case is very simple, more complex transactions using a combination of GETs, PUTs and DELETEs against resources and metadata can be envisioned. However, the exact details of these use cases including which methods are used, the orchestration of methods and the specific resources involved are outside the scope of the FHIR specification.
provide guidance and promote consistency,
rules for achieving complete consistency of both content and granularity amongst resources are neither completely defined nor completely enforced. Considering that FHIR is still a new and emerging standard, an over-abundance of constraint and rigor has been avoided to maximize
initial adoption. Further, there is a natural tension between consistency and an architectural virtue and the practicalities of supporting the real practice of health care. Considering that FHIR ultimately is a reflection of the health
business processes it supports, FHIR will always carry forward some of the data discrepancies, inconsistencies and gaps that are present in the practice of healthcare across different organizations and practitioners. Nonetheless, the
issues of resource consistency and granularity is a topic that gets considerable ongoing discussion, and may change as FHIR approaches a final normative standard and as FHIR adoption approaches a level
where more control is warranted, or a more information/process consistency emerges in the existing healthcare systems.
© HL7.org 2011+. FHIR STU3 Ballot (v1.6.0-9663) generated on Thu, Aug 11, 2016 17:07+1000. QA Page
Links: Search |
Version History |
Table of Contents |
Compare to DSTU2 |
 |
Propose a change
|
Propose a change


