

National Directory of Healthcare Providers & Services (NDH) Implementation Guide
1.0.0-ballot - ballot
![]()
National Directory of Healthcare Providers & Services (NDH) Implementation Guide
1.0.0-ballot - ballot
![]()
This page is part of the National Directory of Healthcare Providers and Services (NDH) Implementation Guide (v1.0.0-ballot: STU1 Ballot 1) based on FHIR (HL7® FHIR® Standard) R4. The current version which supersedes this version is 1.0.0. For a full list of available versions, see the Directory of published versions
The primary focus of the exchange actor implementation guide is a RESTful API for providing data from the National Directory of Healthcare Providers & Services (NDH). The exchange API only supports a one-directional flow of information from NDH into Distributed Access/Workflow Directories (i.e., HTTP GETs).
NDH exchange actor IG conformant implementation:
In profiles, the “Must Support” flag indicates if data exists for the specific property, then it must be represented as defined in the NDH exchange actor IG. If the element is not available from a system, this is not required, and may be omitted.
Conceptually, this guide was written to describe the flow of information from a central source of verified healthcare directory data to local workflow environments. We envisioned NDH which functioned as a “source of truth” for a broad set of provider data available to support local business needs and use cases. A local environment could readily obtain all or a subset of the data it needed from NDH and have confidence that the information was accurate. If necessary, a local environment could supplement NDH data with additional data sourced and/or maintained locally. For example, a local environment doing provider credentialing might rely on NDH for demographic information about a provider (e.g., name, address, educational history, license information, etc.), but also ask the provider for supplementary information such as their work history, liability insurance coverage, or military experience. Likewise, we envisioned that NDH would primarily share information with other systems, rather than individual end users or the public.
The content of this guide, however, does not preclude it from being implemented for smaller “local” directories, or accessed by the public. Generally, conformance requirements throughout the guide are less tightly constrained to support a wider variety of possible implementations. We did not want to set strict requirements about the overall design, technical architecture, capabilities, etc. of a verified national directory that might prevent adoption of this standard. For example, although we would expect a verified national directory to gather and share information about healthcare provider insurance networks and health plans, implementations are not required to do so to be considered conformant.
The NDH may contain a large amount of data that will not be relevant to all use cases or local needs. Therefore, the exchange API defines a number of search parameters to enable users to express the scope of a subset of data they care to access. For example, implementations are required to support searches for Organizations based on address, endpoint, identifier, name/alias, and relationship to a parent organization. In general, parameters for selecting resources based on a business identifier, status, type, or relationship (i.e., reference) are required for all implementations. Most parameters may be used in combination with other parameters and support more “advanced” capabilities like modifiers and chains.
The NDH exchange API currently supports more than one method for accessing directory data. First, a real-time GET of a set of information. However, stakeholders may need other capabilities to support different business needs. For instance, stakeholders may need access to large amounts of data in a single session to either initially seed or refresh their local data repositories. Depending on the scope of data a stakeholder is trying to access, a real-time pull may not be the most effective method for acquiring large data sets. The FHIR specification provides support for asynchronous interactions, using the Bulk Data standard, which may be necessary for implementers to facilitate processing of large amounts of data.
NDH implementation should also consider providing capabilities for users to subscribe to receive updates about the data they care about. A subscribe/publish model can help alleviate the need for stakeholders to periodically query for new data and/or changes to data they have already obtained.Restricted Content
We envision NDH as a public or semi-public utility and make a significant portion of the information openly available. However, NDH may include sensitive data that is not publicly accessible or accessible to every verified healthcare directory stakeholder. For example, an implementer might not want to make data about military personnel, emergency responders/volunteers, or domestic violence shelters available to everyone with access to the verified national directory, or to users in a local environment who have access to data obtained from NDH.
We expect that NDH operational policies and legal agreements will clearly delineate which data stakeholders can access, and if necessary, require stakeholders to protect the privacy/confidentiality of sensitive information in downstream local environments. As such, we have included a Restriction profile based on the Consent resource to convey any restrictions associated with a data element, collection of elements, or resource obtained from a verified national directory.
Figure 1: NDH Exchange API Diagram
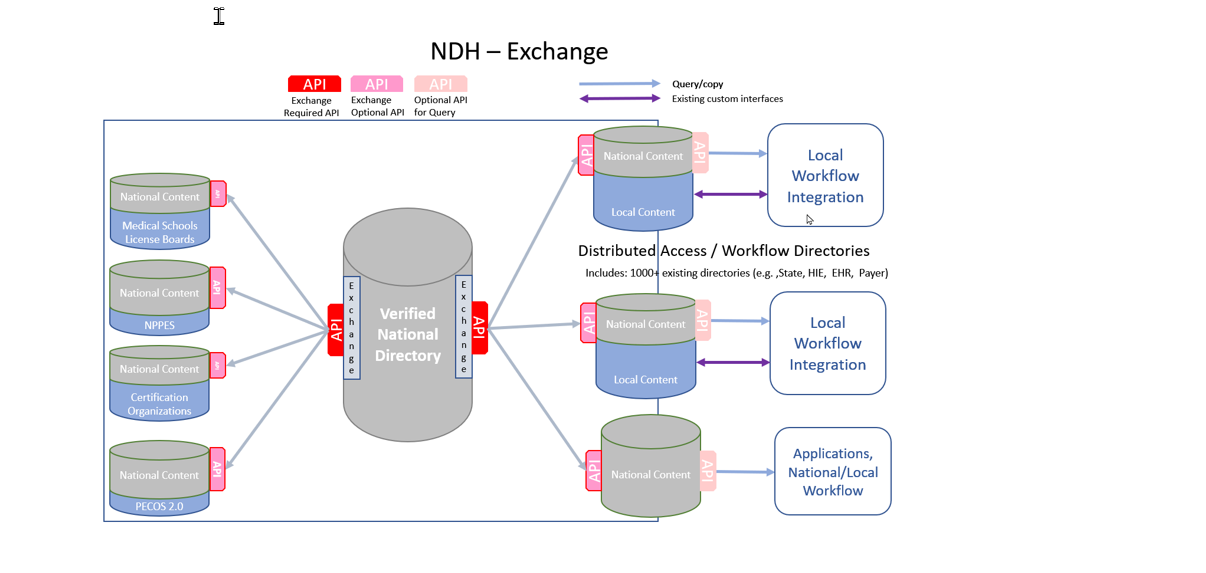
The NDH supports the FHIR Search mechanism for Distributed Workflow Directory to query data from the NDH. The supported search paramters are defined in the NDH exchange capability statement. ndh-exchange-CapabilityStatement
FHIR subscription is a powerful feature that allows a system to receive real-time notifications when data is created, updated, or deleted on a FHIR server. Therefore, distributed Access/Workflow Directories can receive notifications when data changes on the NDH Exchange server through a subscription. This is an active notification system, where the NDH Exchange server proactively sends notifications to the directories as data changes occur.
In the FHIR (DSTU2 - R4) system, subscriptions are query-based. Clients can dynamically define subscriptions by posting a Subscription resource with a criteria string. The FHIR server then executes a query against those criteria and tracks the query result-set for each subscription request. Whenever a change is made to the server’s data, the server must re-run the query and send notifications to clients if their result-set changes, such as when a new entry is added or removed.
Query-based subscriptions may encounter challenges in handling the following scenarios:
To address these challenges, Subscription Topics were introduced in FHIR R5 and later backported to FHIR R4.
Subscription Topics provide documentation for the concepts they represent and are based on resource interactions. This includes the resource type (e.g., Practitioner, Organization) and the specific interaction of interest (e.g., create, update, delete).
To use topic-based subscription support in FHIR R4, NDH will use FHIR artifacts (e.g., Operations, Extensions, Profiles, etc.) defined in the Subscriptions R5 Backport IG.
Soliciting feedback for additional Subscription Topics during the September Ballot
| Subscription Topic | CapabilityStatement SubscriptionTopic Canonical value | Related Resource will be included in the Notification |
| Endpoint created or deleted | http://ndh.org/topic/endpoint-create-or-delete | Endpoint, CareTeam, HealthcareService, InsurancePlan, Location, Network, Organization, OrganizationAffiliation, Practitioner, PracticionerRole |
| HealthcareService created or deleted | http://ndh.org/topic/healthcareservice-create-or-delete | HealthcareService, CareTeam, Location, PractionerRole, Organization, OrganizationAffiliation |
| InsurancePlan created or deleted | http://ndh.org/topic/insuranceplan-create-or-delete | InsurancePlan, Network, Organization, Location |
| Location created or deleted | http://ndh.org/topic/location-create-or-delete | Location, CareTeam, HealthcareService, InsurancePlan, Organization, OrganizationAffiliation |
| Network created or deleted | http://ndh.org/topic/network-create-or-delete | Network, InsurancePlan, Organization, OrganizationAffiliation, PractitionerRole |
| Practitioner created or deleted | http://ndh.org/topic/practitioner-create-or-delete | Practitioner, PractitionerRole, |
| Organization created or deleted | http://ndh.org/topic/organization-create-or-delete | Organization, CareTeam, Endpoint HealthcareService, InsurancePlan Location, Network OrganizationAffiliation, PractitionerRole |
| Practitioner’s qualification created, modified, or deleted | http://ndh.org/topic/practitioner-qualification-create-modified-or-delete | Practitioner, PractitionerRole, |
| Organization’s qualification created, modified, or deleted | http://ndh.org/topic/organization-qualification-create-modified-or-delete | Organization, CareTeam, Endpoint HealthcareService, InsurancePlan Location, Network, PractitionerRole |
Distributed workflow directories could set its own criteria when using the subscription, such as PractitionerRole?practitioner=Practitioner/123
NDH SHALL support
All notifications are enclosed in a Bundle with the type of history. The first entry of the bundle SHALL be the SubscriptionStatus information, encoded as a Parameter resource using the Backport SubscriptionStatus Profile in FHIR R4.
NDH SHALL support
| Parameter | Conformance | Description | Example |
| _outputFormat | SHALL | Specifies the output encoding style that should be used | application/fhir+ndjson |
| _type | SHALL | Specifies a comma-separated list of resource types to include | Practitioner, Organization |
| _typeFilter | SHALL | Specifies a search URL that can be used to narrow the scope of the export. To support multiple typeFilters, separate them by a comma | Practitioner?address-state=CA, Practitioner?address-state=CA |
| _since | SHOULD | Only resources that were last updated on or after the given time will be included | 2023-04-01T01:00:00:00Z |
When retrieving National directory data through bulk $export operation for distributed workflow directories, the data is stored in ndjson files containing FHIR resources. Each line in the ndjson file represents a single FHIR resource, whose unique identifier (resource.id) is controlled by the server. To identify a specific resource across different servers, resource.identifier is used instead. In the case of the National Directory, each resource stored in it has a unique resource.id, which is also used to populate the resource.identifier as identifier.system = national directory system and identifier.value = resource.id.
After performing bulk $export, it’s important not to directly enter the retrieved data into the local directory, as the local server may have a different set of resource.ids for the same resources. To avoid duplication, a mapping should be performed based on the resource.identifier. This involves modifying the resource.id in the ndjson file with the local resource.id, and then importing the modified file using $import operation. If $import operation is not supported by your server, you can convert the modified ndjson file, with the resources having your local resource.id, to a FHIR transition Bundle and load it into your local server using a PUT request.
If the distributed workflow directory already has the National Directory content and wishes to update it with the latest changes from the National Directory, the bulk $export operation can be used. However, there are a few things to consider:
By following these steps, the distributed workflow directory can efficiently update its content with the latest changes from the National Directory while maintaining data integrity and avoiding duplication.
For the directory bulk data extraction, to request an entire copy of all content in the directory, the scope selection can be defined at the top level specifying that it would like to retrieve all content for the specified resource types from the base of the FHIR server.
GET [base]/$export?_type=Organization,Location,Practitioner,PractitionerRole,HealthcareService,VerificationResult, ...
A healthcare directory may curate such an extract on a nightly process, and simply return results without needing to scan the live system. In the result, the value returned in the transactionTime in the result should contain the timestamp at which the extract was generated (including timezone information) and should be used in a subsequent call to retrieve changes since this point in time.
Once a system has a complete set of data, it is usually more efficient to ask for changes from a specific point in time. In which case the request should use the value above (transactionTime) to update the local directory.
GET [base]/$export?_type=Organization,Location,Practitioner, ... &_since=[transactionTime]&_outputFormat=application/fhir+ndjson
This behaves the same as the initial request, with the exception of the content.
It is expected that this request is more likely to return current information, rather than a pre-generated snapshot, as the transactionTime could be anything.
Note: The current bulk data handling specification does not handle deleted items. The recommendation is that periodically a complete download should be performed to check for “gaps” to reconcile the deletions (which could be due to security changes). However, content should not usually be “deleted”; it should be marked as inactive, or end dated.
Proposal: Include a deletions bundle(s) for each resource type to report the deletions (when using the _since parameter). As demonstrated in the status tracking output section below, these bundles would be included in the process output as a new property “deletions”. This bundle would have a type of “collection”, and each entry would be indicated as a deleted item in the history.
<entry>
<!-- no resource included for a delete -->
<request>
<method value="DELETE"/>
<url value="PractitionerRole/[id]"/>
</request>
<!-- response carries the instant the server processed the delete -->
<response>
<lastModified value="2014-08-20T11:05:34.174Z"/>
</response>
</entry>
The total in the bundle will be the count of deletions in the file, the total in the operation result will indicate the number of deletion bundles in the ndjson (same as the other types).
If the caller doesn’t want to use the deletions, they can ignore the files in the output, and not download those specific files.
GET [base]/$export?_type=Organization
&_since=[transactionTime]
&_typeFilter=Organization?identifier=https://vs.directtrust.org/identifier/organization&_outputFormat=application/fhir+ndjson
To export specific resources, you can utilize the _typeFilter option. In this instance, you can limit the exported data to organizations with the identifier system set as https://vs.directtrust.org/identifier/organization.
GET [base]/$export?_type=Organization,Practitioner
&_since=[transactionTime]
&_typeFilter=Organization?address-state=CA, Practitioner?address-state=CA
&_outputFormat=application/fhir+ndjson
To export Practitioners and Organizations for only a given state.
The previous sections are all defined by the FHIR Bulk Data extract specification, however one may choose to implement an additional parameter to permit the selection to also filter resources that are included in a specified list resource. The approach is similar to the same capability defined by FHIR http://hl7.org/fhir/search.html#list
This operation could be used by client applications such as a Primary Care System that want to update only periodically using this technique, solely using resources they currently have loaded in their “local directory” - an internal black book, which caches resources from previous searches to the system.
GET [base]/$export?_type=Organization,Location,Practitioner,PractitionerRole,HealthcareService&_list=List/45
In this example the Primary Care System would be responsible for keeping List/45 up to date with what it is tracking. A national service may decide that permitting this List resource management is too much overhead, however local enterprise directories may support this type of functionality.
The current bulk data export operations use the Group resource to define the set of data related to a Patient. At present there is no definition for this to be done in the directory space, unless it is at the resource level. This is possible with search and subscriptions (which leverage search) by using search parameters on the resource types and setting the parameters of interest.
When defining a subset of data, consideration should be given to what happens when data is changed to the extent that it is no longer within the context of the conditions.
One possible method would be to use a bundle of searches where each type has its own search parameters. Another way is to use a GraphDefinition resource.
This functionality should be the subject of a connectathon to determine practical solutions.
One possibility could be to leverage the List functionality described above to maintain a state of what was included in previous content. However, this incurs additional overhead on the part of the server and for many systems, especially those at scale like a national system, this is likely not practical.
The bulk extract format is always an nd-json file (new-line delimited json). Each file can only contain 1 resource type in it, but can be spread across multiple files, with either a size limit or count limit imposed by the extracting system, not the requestor.
The list of these files will be returned in the Complete status output, as described in the standard Bulk Data documentation.
There are 2 options for starting the extract. The first option is a single operation specifying all the content, and the other option is for a specific type only. These were both covered above in the “selecting the scope” section.
Here one will only document the use of global export, as an initial request.
The initial request:
GET [base]/$export?_type=Organization,Location,Practitioner,PractitionerRole,HealthcareService
With headers:
Accept: application/fhir+json</code>
Authentication: Bearer [bearer token]</code>
Prefer: respond-async</code>
This will return either:
4XX or 5XX with an OperationOutcome resource body if the request fails, or a202 Accepted when successful. Which will include a Content-Location header with an absolute URI for subsequent status requests and optionally, an OperationOutcome in the resource bodyExample Content-Location: http://example.org/status-tracking/request-123 (note that this is not necessarily a FHIR endpoint, and is not a true FHIR resource)
After a bulk data request has been started, the client MAY poll the URI provided in the Content-Location header.
GET http://example.org/status-tracking/request-123
This will return one of the following codes:
HTTP status code of 202 Accepted when still in progress (and no body has been returned)
5XX when a fatal error occurs, with an OperationOutcome in json format for the body detailing of the error
(Note this is a fatal error in processing, not some error encountered while processing files - a complete extract can contain errors)200 OK when the processing is complete, and the result is a json object as noted in the specification (an example included below)Refer to the build data specification for details of the completion event:
https://github.com/smart-on-fhir/fhir-bulk-data-docs/blob/master/export.md#response—complete-status
{
"transactionTime": "[instant]",
"request": "[base]/$export?_type=Organization,Location,Practitioner,PractitionerRole,HealthcareService",
"requiresAccessToken": true,
"output": [
{
"type": "Practitioner",
"url": "http://serverpath2/practitioner_file_1.ndjson",
"count": 10000
},
{
"type": "Practitioner",
"url": "http://serverpath2/practitioner_file_2.ndjson",
"count": 3017
},
{
"type": "Location",
"url": "http://serverpath2/location_file_1.ndjson",
"count": 4182
}
],
// Note that this deletions property is a proposal, not part of the bulk data spec.
"deletions": [
{
"type": "PractitionerRole",
"url": "http://serverpath2/practitionerrole_deletions_1.ndjson", // the bundle will include the total number of deletions in the file
"count": 23 // this is the number of bundles in the file, not the number of resources deleted
}
],
"error": [
{
"type": "OperationOutcome",
"url": "http://serverpath2/err_file_1.ndjson",
"count": 439
}
]
}
Once the tracking of the extract returns a 200 OK completed status, the body of the result will include the list of prepared files that can be downloaded.
Then each of these URLs can be downloaded by a simple get, ensuring to pass the Bearer token if the result indicates requiresAccessToken = true
While downloading, it is also recommended to include the header Accept-Encoding: gzip to compress the content as it comes down.
GET http://serverpath2/location_file_1.ndjson
(Note: our implementation will probably always gzip encode the content - as we are likely to store the processing files gzip encoded to save space in the storage system)
Once all the needed files are downloaded, one should tell the server to clean_up, as detailed in the next section.
This is the simplest step in the process. To finish the extract, one will call DELETE on the status tracking URL.
DELETE http://example.org/status-tracking/request-123
Calling DELETE tells the server that we are all finished with the data, and it can be deleted/cleaned up. The server may also include some time based limits where it may only keep the data for a set period of time before it automatically cleans it up.
If a distributed workflow directory needs to retrieve information from the NDH on a scheduled basis, there are two approaches available.
Ndhexport-operation-flow-diagram
Our vision for NDH is that it will function as a public or semi-public utility, with a substantial amount of its information being made openly available. However, certain data included in NDH may be sensitive, and not accessible to all NDH stakeholders or the public. For instance, an implementer may choose to restrict data related to military personnel, emergency responders/volunteers, or domestic violence shelters from being accessible to anyone who has access to NDH, or to users in a local environment who have obtained data from NDH.
It is our expectation that NDH operational policies and legal agreements will provide a clear understanding of which data stakeholders can access. If necessary, these policies will require stakeholders to maintain the privacy and confidentiality of any sensitive information within downstream local environments. To facilitate this, we have incorporated a Restriction profile based on the Consent resource. This profile is designed to convey any restrictions associated with a data element, collection of elements, or resource that has been obtained from a verified healthcare directory.
IG © 2023+ HL7 International - Patient Administration Work Group. Package hl7.fhir.us.ndh#1.0.0-ballot based on FHIR 4.0.1. Generated 2023-07-30
Links: Table of Contents |
QA Report
| Version History |
 |
Propose a change
|
Propose a change