
This page is part of the FHIR Specification (v0.01: Historical Archive Draft). The current version which supercedes this version is 5.0.0. For a full list of available versions, see the Directory of published versions

Fast Healthcare Interoperability Resources (FHIR) defines a set of "resources" for health which represent granular clinical concepts that can be exchanged in order to quickly and effectively solve problems in healthcare and related process. This document is the full FHIR specification (version 0.01).
The exact license applicable to FHIR is still under deliberation. The FHIR content will remain © HL7.org, and will be free for use by any implementers, irrespective of whether they are HL7 members or not. There will be no IP encumbrance from HL7.
The FHIR home page is http://www.hl7.org/fhir, and has links to other representations and versions of FHIR, along with references to various implementation resources.
1: Infrastructure
1.1: Introduction
1.2: Resource Format
1.3: Data Types
1.4: Mixins
1.5: Terminologies
1.6: Extensibility
1.7: Constraint
2: Exchange
2.1: Implementation
2.2: Aggregations
2.3: REST (HTTP)
2.4: RESTful Conformance Statement
2.5: Messaging
2.6: Message Resource
2.7: Messaging Conformance Statement
2.8: Documents
2.9: Document Conformance Statement
2.10: hData Integration
2.11: Resource Profile
3: Administrative Resources
3.1: Person
3.2: Animal
3.3: Organization
3.4: Agent
3.5: Patient
3.6: Document
4: Clinical Components
4.1: Lab Report
5: Medications
5.1: Prescription
6: Care management
7: Documents
|
Fast Healthcare Interoperability Resources (FHIR) defines a set of "resources" for health. These resources represent granular clinical concepts that can be exchanged in order to quickly and effectively solve problems in healthcare and related process. The resources cover the basic elements of healthcare - patients, admissions, diagnostic reports, medications, and problem lists, with their typical participants, and also support a range of richer and more complex clinical models. The simple direct definitions of the resources are based on thorough requirements gathering, formal analysis and extensive cross-mapping to other relevant standards. |
Technically, FHIR is designed for the web; where possible or appropriate, open internet standards are used for data representation. The resources are based on simple XML, with an http-based RESTful (§2.3) protocol where each resource has predictable URL. Note that while the resources are defined to support an HTTP based RESTful infrastructure, it is not necessary to use such an infrastructure when using the resources. This specification also defines a class messaging based framework (§2.5) and way to use the resources to build clinical documents (§2.8). In addition, the resources can be used in a SOA-based solution (§2.1.1). This flexibility offers coherent solutions for a range of interoperability problems.
This specification has the following parts:
The contents of this specification are navigated using the right-hand side bar.
All resources have the following parts:
Because the master resource id is never changed or reused, resources may refer to other resources by the master id knowing that this is stable reference. While each resource can be read and/or changed without explicit reference to these other resources, the presence of these references influences the behaviour of the system: implementations are required to maintain system and data integrity at all times.
The exchange specifications are simple and straight forward and based around a direct description of the XML representation of the resource. Each resource is described separately, though there are some common data patterns used across all the resources (called "data types (§1.3)").
For each resource, this specification defines
In addition to the simple XML definitions, a W3C XML schema and UML class diagram are available for each resource. The UML class diagram represents the same logical model as the XML format (though because of UML issues, implementors should not expect software built from the UML models to be automatically interoperable or conformant with the XML defined in this specification).
Each xml element (or matching UML class, attribute and composition association) has a formal definition that includes a definition, statement of requirements, additional comments, a mapping to the v3 RIM, and an indicative v2 mapping.
In addition, for each resource, some RESTful specific features are described:
Each resource supports the same list of transactions - read, update, delete, etc. One particularly important transaction supported by every resource type is the provision of a conformance statement which specifies what parts of the defined content model are supported by the system, and what other transactions or interactions are supported. If any of the other interactions are supported, the conformance interaction must be supported. (i.e. if the conformance interaction returns an error, no operations are supported).
In this specification, resources are described in a simple XML format. This page documents how the XML content for resources is described and controlled. The XML may be validated by schema, and schemas are provided, but validation is not required in operational systems (though the XML must always be valid against this specification). In addition, W3C Schema and UML models are provided that may be a useful aid for system implementation.
All the content model definitions provided in this specification follow the same general pattern:
<name xmlns="...">
<nameA> opt type description of content <nameA>
<nameB> mand type Zero+ description </nameB>
<nameC> <!-- One+ -->
<nameD mand type="?">Relevant records </nameD>
</nameC>
<name>
Notes:
Every resource contains the following common elements:
<[Name] xmlns="http://www.hl7.org/fhir"> <id> mand id Master Resource Id, always first. Never changes after creation</id> <extensions> opt See Extensions </extensions> <text> mand Narrative Text summary of resource, for human interpretation</text> </[Name]>
The id element is always mandatory except in the case that a resource is posted to a server to create it, and the id of the resource is not yet known. In this case, the id element is absent. The use of the id element is discussed further below (§1.2.4). The use of the extensions element is discussed under "Extensibility" (§1.6). The text ("Narrative") is discussed below (§1.2.3). In addition to these data elements, there are several pieces of metadata about a resource that are not part of the resource content, but are delegated to the infrastructure:
| Metadata Item | Type | Usage |
|---|---|---|
| Version Id | id | Changed each time the content of the resource changes. Can be referenced in a resource reference (see below). Can be used to ensure that updates are based on the latest version of the resource |
| Last Modified Date | dateTime | Change each time the content of the resource changes. Can be used by a system or a human to judge the currency of the resource content |
| Master Location | uri | Reports the location of the master for the resource. Useful when a resource is re-used by another system - it can report the location of the master should any system need to know this. |
In any environment where the resources are used, the technical details of the delegation will have to be resolved. For further details, see Implementation Details (§2.1).
Data Quality - or the lack thereof- is a ubiquitious issue in healthcare. In order to handle this, every element defined as part of a resource data structure may have a dataAbsentReason attribute, which is used to specify why the normally expected content of the data element is missing.
<x dataAbsentReason=""/>
The dataAbsentReason attribute can have one of the following values:
| unknown | The value is not known |
| asked | The source human does not know the value |
| temp | There is reason to expect (from the workflow) that the value may become known |
| notasked | The workflow didn't lead to this value being known |
| masked | The information is not available due to security, privacy or related reasons |
| unsupported | The source system wasn't capable of supporting this element |
| astext | The content of the data is represented as text (see below) |
| error | Some system or workflow process error means that the information is not available |
Notes:
Every element has a control flags which is used to control the degree to which missing or poor quality data is tolerated on a per element basis. The control flag must have one of the following values:
| mand | The element must be present, and must be populated with correct data. i.e. Resource.id. No dataAbsentReason is allowed. |
| req | The element must be present, but may have a dataAbsentReason (todo: when would this be used?) |
| cond | The element may not be present, but if it is, may not have a dataAbsentReason. The condition must be explained in the notes that follow the definition |
| opt | The element doesn't have to be present. If it is present, it might have a dataAbsentReason. If the normal structure can be replaced with text, it might be. |
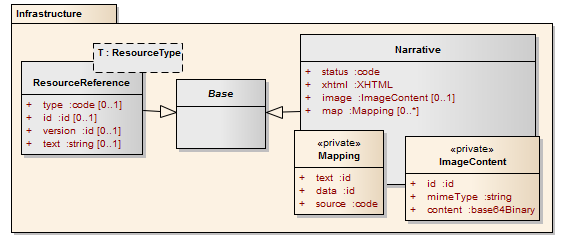
Every resource includes a human readable narrative that contains a summary of the resource, and may be used to represent the content of the resource to a human. The narrative need not encode all the structured data, but is required to contain sufficient detail to make it "clinically safe" for a human to just read the narrative. Each resource will define what content must be represented in the narrative to ensure clinical safety
The narrative for a resource is allowed to contain additional information that is not in the structured data, including human edited content. Such additional information must be in the scope of the definition of the resource.
Each narrative has a flag that specifies the relationship of the narrative from the structured data, which may have one of the following codes:
| generated | The contents of the narrative are entirely generated from the structured data in the resource. |
| extensions | The contents of the narrative are entirely generated from the structured data in the resource, and some of the structured data is contained in extensions |
| additional | The contents of the narrative contain additional information not found in the structured data |
In addition to this general flag that specifies the status of the narrative, there is an optional mapping between the narrative and the structured data. Each mapping has narrative id, and structured data id which map to xml:id attributes found in the narrative and the structured data respectively, and a flag for whether the text was generated from the data, or the data was generated from the text (by some form of retrospective processing, whether human or computer), or whether both come from an external source. The structured data target may be an empty element with a dataAbsentReason of "astext"; this means that the value of the text could not be properly represented in the data type. Any element defined as part of the resource content, or any repeating element inside a data type, may carry an id attribute to serve as the target of a narrative mapping. When using xml:id attributes, the comments in the aggregation section (§2.2) about the value of the xml:id attribute should be kept in mind.
The narrative is an xhtml fragment that also includes images if appropriate:
<x xmlns="http://www.hl7.org/fhir"> <status> cond code generated | extensions | additional</status> <div xmlns="http://www.w3.org/1999/xhtml"mand limited xhtml content</div> <image> opt <!-- Zero+ --> <mimeType> mand code mime type of image</mimeType> <content> mand base64Binary base64 image data</content> </image> <map> opt <!-- Zero+ --> <text> mand xml:ID Narrative source (xml:id)</text> <data> mand xml:ID Data source (xml:id)</data> <source> mand code text | data</source> </map> </x>
Terminology Bindings
| generated | The contents of the narrative are entirely generated from the structured data in the resource. | |
| extensions | The contents of the narrative are entirely generated from the structured data in the resource, and some of the structured data is contained in extensions | |
| additional | The contents of the narrative contain additional information not found in the structured data | |
| text | The text is the original data | |
| data | The data is the original data | |
The status is required when the narrative is the full resource narrative, but not required in resource references (see below).
The contents of the xhtml element are an XHTML fragment containing only the basic html formatting elements described in chapters 7-11 (except section 4 of chapter 9) and 15 of the HTML 4.0 standard, <a> elements (either name or href), images, and internally contained stylesheets. The XHTML content may not contain a head, a body element, external stylesheet references, scripts, forms, base/link/xlink, frames, iframes, and objects. Technically, the content of the text element is a union of the XHTML Schema types "block", and "inline", with the additional rules above applied.
<narrative>
<div xmlns="http://www.w3.org/1999/xhtml">This is a simple
example with only plain text</div>
</narrative>
<narrative>
<div xmlns="http://www.w3.org/1999/xhtml">
<p>
This is an <i>example</i> with some <b>xhtml</b> formatting.
</p>
</div>
<narrative>
An additional address scheme is defined for use within the xhtml for image location:
<img src="fhir:#45"/>
This is a reference to an id attribute on an element in the same resource, either in the image attachments on the text element directly, or an element of type "Attachment (§1.3.4)".
<narrative>
<html xmlns="http://www.w3.org/1999/xhtml">
<p>
<img src="fhir:#a1/>.
</p>
</html>
<image id="a1">
<mimeType>image/png</mimeType>
<data>MEKH....SD/Z</data>
</image>
<narrative>
Applications processing the html should always be able to strip external images (images not using the alternative "fhir" scheme above), and still be able to present the information correctly to a human reader (since these images are not part of the resource, their presence cannot be assured). Additionally, applications processing the html should always be able to strip the HTML tags completely (correcting for implicit paragraph elements such as headers) and still be clinically safe (so where internal images are used, they must include an appropriate caption).
The dataAbsentReason is not used on the narrative element, or any elements contained in it. The xhtml element must have some non-whitespace content.
The "Resource" type indicates a reference from one resource to another. Since each resource is identified by a master id that never changes (a different id implies a different resource), references are done by id.
<x>
<type> cond ResourceType Resource Type</type>
<id> cond id Id of the reference</id>
<version> opt id Specific version Id of resource referenced</version>
<text> opt string Text alternative for the resource</text>
</x>
The resourceType type is the name of one of the resources defined in this specification, such as "Patient". Whether or not the type of the resource is fixed for a particular element, the reference includes the resource type (this is to assist with future prooting the specification).
A specific version of the resource may be referenced by specifying a version Id in addition to the resource identifier. The version identifier is only known to be unique in the context of a given resource, so the resource Id is always required. Note that locating and retrieving a particular version of a resource is implementation specific, like accessing the latest version of the resource.
<id>
<type>Patient</type>
<id>034AB16</id>
<id>
The id type can take one of the following forms:
| A whole number in the range 0 to 2^64-1. May be represented in hex | |
| A uuid (guid) (in lowercase, without wrapping with the characters "{}[]" which sometimes occur) | |
| An ISO OID (reference) | |
| Any other combination of letters, numerals, "-" and "." | |
Resource ids must be represented in lowercase. Ids are always opaque, and systems should not and need not attempt to determine their internal structure. However the id is represented, it must always be represented in the same way in resource references and URLs.
Some narrative may be provided that describes the resource in addition to the resource reference (or in place of, unless the resource reference is mandatory).
<id>
<type>Organisation</type>
<id>1234</id>
<text>HL7, Inc</text>
<id>
Use
Unless the resource reference element has a dataAbsentReason flag, it must contain a valid type and id, or, if it is not mandatory, a text alternative.
There is no explicit version marker in the XML. Subsequent versions of this specification may introduce new elements at any point in the content models, but the path or meaning of existing data elements will not be changed.
Given that in a typical scenario, mixed versions may need to exist, applications would best ignore elements that they do not recognize. However in a healthcare context, many application vendors are unwilling to consider this approach because of concerns about clinical risk. Applications are not required to ignore unknown elements, but must declare whether they will do so in their conformance statements.
This specification provides schema definitions for all the content models described here. The base schema is called "fhir-base.xsd" and defines all the datatypes and also the base infrastructure types described on this page. In addition, there is a schema for each resource, and a common schema fhir-all.xsd that includes all the resource schemas.
XML that is exchanged must be valid against the schema, though there is no requirement to validate instances against the schema, nor is being valid against the schema sufficient to be a conformant instance (this specification makes many rules that cannot be checked by schema). Exchanged content must not specify the schema or even the schema instance namespace in the resource XML.
Should schema based validation or code generation be of interest, applications can define their own schemas that more closely match the working content mode given their conformance statement. These schemas can eliminate elements not used by the application, and explicitly define extensions that are used. However the xml format they describe must be consistent with the XML and rules defined in this specification.
Though the formal representation of the resources is in XML, many systems wish to use JSON to exchange the resources, and it is useful to standardise a single JSON format for this use. The JSON format for the resources follows the standard XML format closely:
<name xmlns="...">
<nameA> opt type description of content <nameA>
<nameB> mand type Zero+ description </nameB>
<nameC> <!-- One+ -->
<nameD mand type="?">Relevant records </nameD>
</nameC>
<name>
is represented in JSON as
{"name":
"nameA" : {...},
"nameB" :
[
{...},
{...}
],
"nameC" :
[
{ "nameD" : {...} }
}
}
Notes:
In addition to the schema, this specification also provides object models defined in UML that may be of assistance in defining systems that work with the resources defined here.
Although the UML models provided express the same contents as the xml formats, because of the wide variation in how different architectures and tools map from UML to XML, there should be no expectation that any particular tool will produce compatible XML from these UML diagrams. Systems are welcome to use these object models as a basis for serialization internally, or even between trading partner systems, with any form of exchange technology (including JSON). Systems that use this form of exchange cannot claim to be conformant with this specification, but can describe themselves as using "FHIR consistent object models".
The data types include primitive types imported from XML schema, and also additional data types that capture patterns that are ubiquitious throughout the scope of the healthcare data that will be exchanged.
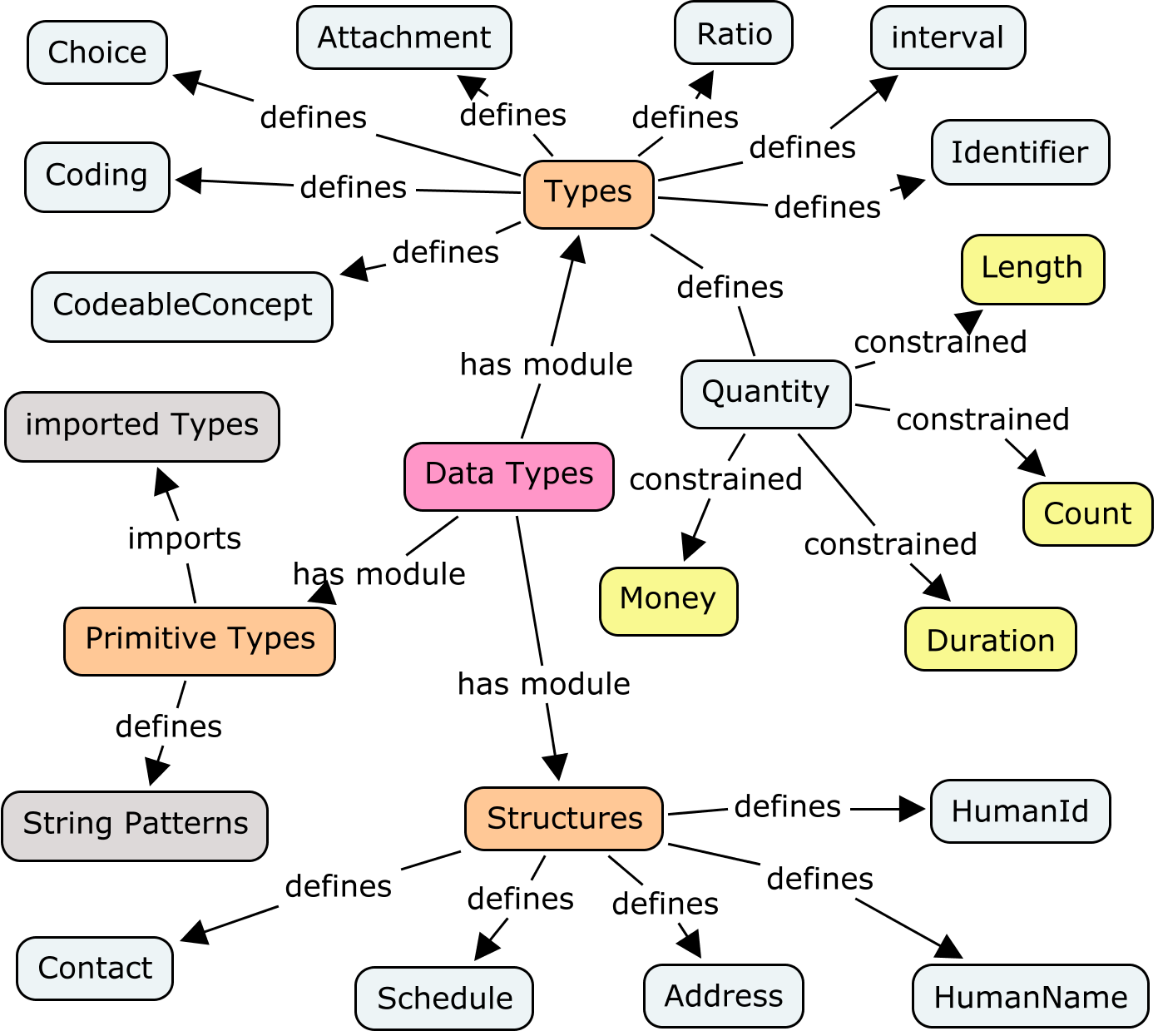
The data types defined on this page on this page are categorised as either "Core Types" or "Structures". "Structures" are higher level concepts that some systems internally treat differently from the "Core Types". There is no functional difference betweent the two categories, and systems are not required to treat them any differently. This table summarises the types:
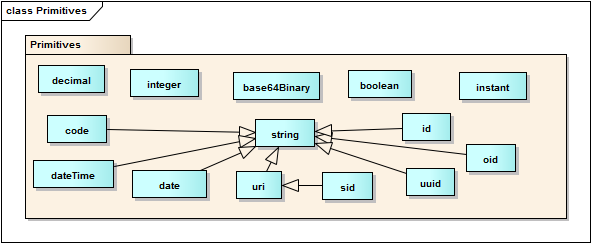
The following table summarises the primitive types that are used in the exchange specifications. The posssible values for these types are those specified in the W3C Schema specification part 2.
Implementations that convert the xml described in this specification to other formats such as JSON or some object based notation will have to find equivalent types.
In addition to these assumed primitive types, this specification define a few simple string patterns that are commonly used:
| code | a string which has at least one character and no whitespace |
| oid | An ISO oid [ref ISO std] |
| uuid | A UUID [ref DEC std]. Sometimes called a GUID. Always represented in lowercase |
| sid | A system id, which is a uri taken from the list of known definition systems (§1.5.1). sid values never contain a '#' |
| id | A whole number in the range 0 to 2^64-1, optionally represented in hex, a uuid, an oid, or any other combination of letters, numerals, "-" and ".", with a length limit of 36 characters |
| date | A date, or partial date (e.g. just year or year + month). There is no timezone. The format is a union of the schema types gYear, gYearMonth, and date. |
| dateTime | A date, date-time or partial date (e.g. just year or year + month). Generally, there is no timezone, though one may be populated if hours and minutes are specified. The format is a union of the schema types gYear, gYearMonth, date, and dateTime. Seconds may be provided but may also be ignored. |
Examples
date (e.g. Date of birth):
<x>1951-06-04</x>
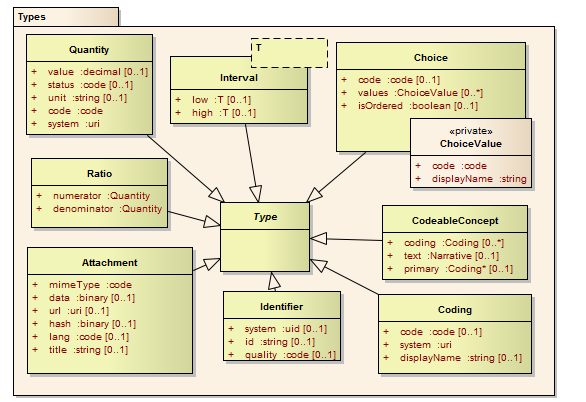
This type is for referring to data content defined in other formats. The most common use of this to include images or reports in some report format such as PDF, but it can be used for any data that has a mime type.
<x xmlns="http://www.hl7.org/fhir"> <mimeType> mand code the mime type of the content</mimeType> <data> opt base64Binary data inline, base64ed</data> <url> opt uri uri where the data can be found</url> <hash> opt base64Binary sha-256 hash of the data (base64 )</hash> <lang> opt code ISO 639-3 language code</lang> <title> opt string A name to display in place of the data</title> </x>
Terminology Bindings
The mimeType element must always be populated. The actual content of the Attachment can be conveyed directly using the data element, or a url reference can be provided. If both are provided, they must point to the same content. The reference can never be reused to point to different data (which means that the reference is version specific). The url reference must point to a location that resolves to actual data; some uri's such as cid: meet this requirement.
The hash is included so that applications can verify that the contents of a location have not changd, and also so that a signature of the xml content can implicitly sign the content of an image without having to include the data or reference the url in the signature. The lang element can help a consumer choose between multiple different Data elements.
In many cases where Attachment is used, the cardinality is >1; repeats are used to convey the same content in different mime types and languages, or to provide a thumbnail of a large image.
Use
Unless the Attachment element has a dataAbsentReason flag, it must contain a data or a url. If neither data nor a url is provided, the value should be understood as an assertion that no content for the specified mimeType and/or lang is available for the reason stated.
The context of use may frequently make rules about the kind of attachment (and therefore, the kind of mime types) that can be used.
Examples
A PDF document:
<x> <mimeType>application/pdf</mimeType> <data>/9j/4...KAP//Z</data> <!-- covers many lines --> <lang type="code">en-us</lang> <title type="string">Definition of Procedure</title> </x>
A reference to a DICOM image:
<x> <mimeType>application/dicom</mimeType> <url>http://10.1.2.3:1000/wado?requestType=WADO&wado details...</url> <hash>>EQH/..AgME</hash> </x>
An identifier defined by some external system.
<x xmlns="http://www.hl7.org/fhir"> <system> cond uri The system that defines the id</system> <id> cond string the actual identifier</id> </x>
The system may be either a specific application, or a recognised concept for which the specific application may be implicit. The system is a URI that may be an OID (oid:) or a UUID (uuid:), a sid (a specially defined URI from the named systems list (§1.5.1)), or a URL that references a definition of the identifier. OIDs and UUIDs may be registered in the HL7 OID registry, and should be if the content is shared or exchanged across institutional boundaries.
In some cases, the system may not be known - only the id is known (i.e. a simple device that scans a barcode). In this case, no useful matching may be perfomed using the id unless the system can be safely inferred by the context.
Note that the system defines the scheme that controls uniqueness of the id. The id must be unique for within the defined system. If the id itself is actually an OID, a UUID, or a URI, then the system will be either "urn:hl7-org:sid/oid", "urn:hl7-org:sid/uuid" or "urn:hl7-org:sid/uri" respectively, and the OID, UUID would be in the id element. Ids are always case sensitive. UUIDs must be represented in lower case.
Use
Unless the Identifier element has a dataAbsentReason flag, it must contain a an id. If the Identifier element is marked as mandatory, it must contain a system.
Examples
A primary key from an application table (an OID in the space allowcated by HL7 to some organisation to further sub-allocate):
<x> <system>oid:2.16.840.1.113883.16.4.3.2.5</system> <id>123</id> </x>
An identifier of a resource defined by this specification, on a particular system:
<x> <system>http://pas-server/xxx/patients</system> <id>443556</id> </x>
A guid:
<x> <system>urn:hl7-org:sid/uuid</system> <id>a76d9bbf-f293-4fb7-ad4c-2851cac77162</id> </x>
A CodeableConcept represents a represents a field that is usually defined by formal reference to one or more terminologies or ontologies, but may also be defined by the provision of text.
<x xmlns="http://www.hl7.org/fhir"> <coding> Zero+ Coding <!-- A reference to a code defined by a terminology system --> <code> cond code Symbol in syntax defined by the system</code> <system> mand uri Identity of the terminology system </system> <display> opt string Representation defined by the system</display> </coding> <text> cond string A plain text representation of the concept</text> <primary> opt xml:ID Which code was chosen directly by the user</primary> </x>
This data type has text and/or one more "codings" that all represent a single notional concept, though the multiple codings will often have slightly different granularity due to the differences in the definitions of the underlying codes. Each "coding" is a representation of the concept using a symbol from a defined "code system", which may be an enumeration, a list of codes, a full terminology such as SNOMED-CT or LOINC, or a formal ontology. The concept may be coded multiple times in different code systems (or even multiple times in the same code systems, where multiple forms are possible, such as with SNOMED-CT). Whether or not coding elements are present, the text is a human language representation of the concept as seen/selected/uttered by the user who entered the data, and/or which represents the intended meaning of the user or concept. Very often the text is the same as a display of one of the codings.
For each coding, there must be a system the identifies the terminology or ontology the code is defined by. The system is a URI that may be an OID (oid:) or a UUID (uuid:), a specially defined URI from the named systems list (§1.5.1), or a url that references a definition of the system, or any other URI. OIDs and UUIDs may be registered in the HL7 OID registry, and should be if the content is shared or exchanged across institutional boundaries. The system reference is version independent; applications are never required to process the content of the system URI in order to determine whether two codes are the same. Note though, that merely because a code/system pair is different does not mean that concept is different - applications have to consult the ontologies or terminologies to make those kind of comparisons.
If present, the code must be a syntactically correct symbol as defined by the system. Note that codes are case sensitive unless specified otherwise by the code system. If no code is present, the coding means that the concept cannot be encoded in the identified system. The display is a text representation of the code that is defined by the system, which can be used to display the code by an application that is not aware of the system. One of the codings may be flagged as the primary - the code that the user actually chose directly. If present, the value of the primary element is an ID that must match an xml:id on one of the codings.
Use
Unless the CodeableConcept element has a dataAbsentReason flag, it must contain at least one coding with a code, or a text. Each coding must contain a system element, and should contain a display if it contains a code.
The context of use may frequently make rules about what codings are allowed or required.
The CodeableConcept data type represents a commonly encountered pattern around the use of coding, with multiple codings and a text. In some circumstances, the resources and/or models that use these data types may be more prescriptive about the use of multiple codings, the way that the text element interacts with the codings, and/or the way that codings are derived from each other. In these circumstances, the "Coding" Data Type is used. The Coding type has the contents of the coding element as defined in the CodeableConcept data type.
Examples
A simple code for headache, in ICD-10, with the text on which the coding is based:
<x>
<coding>
<code>G44.1</code>
<system>urn:hl7-org:sid/icd-10</system>
</coding>
<text>general headache</text>
</x>
A concept represented in an institutions local coding systems for which no snomed equivalent exists:
<x>
<coding>
<code>burn</code>
<system>oid:2.16.840.1.113883.19.5.2</system>
</coding>
<coding>
<system>http://snomed.info</system>
</coding>
<text>Burnt ear with iron. Burnt other ear calling for ambulance</text>
</x>
A Snomed-CT expression:
<x>
<coding>
<code>128045006:{363698007=56459004}</code>
<system>http://snomed.info</system>
</coding>
<text>Cellulitis of the foot</text>
</x>
A code taken from a short list of codes that are not defined in a formal code system. Choice is generally used for things like pain scales, questionnaires or formally defined assessment indexes. The possible codes may be ordered with some arbitrarily defined scale. Note: Choice is not an appropriate data type to use when the possible codes are defined in a formal code system, such as a value set, or otherwise stord on a terminology server.
<x xmlns="http://www.hl7.org/fhir"> <code> cond code Selected code</code> <value> mand <!-- One+ A list of possible values for the code --> <code> mand code Possible code</code> <display> opt string Display for the code</display> </value> <isOrdered> opt boolean If the order of the values has meaning</isOrdered> </x>
The code is the selected value. A list of possible values must be provided; at least a code must be provided for each value. The selected code must be found in the list of possible codes.
If isOrdered is true, then the values have an inherent meaningful order, and the list of values must be provided in the correct order.
Use
Unless the Choice element has a dataAbsentReason flag, it must contain a code. The Choice element must always contain at least one possible value.
Example
The results on a urinalysis strip:
<x>
<code>+</code>
<value>
<code>neg</code>
</value>
<value>
<code>trace</code>
</value>
<value>
<code>+</code>
</value>
<value>
<code>++</code>
</value>
<value>
<code>+++</code>
</value>
<isOrdered>true</isOrdered>
</x>
A measured amount (or an amount that can potentially be measured).
<x xmlns="http://www.hl7.org/fhir"> <value> cond decimal Numerical value (with implicit precision)</value> <status> opt code how the value should be understood and represented</status> <units> cond string unit representation</units> <code> cond code A coded form of the unit</code> <system> cond uri The system that defines the coded form</system> </x>
Terminology Bindings
| < | The actual value is less than the given value | |
| <= | The actual value is less than or equal to the given value | |
| >= | The actual value is greater than or equal to the given value | |
| > | The actual value is greater than the given value | |
The value contains the numerical value of the quantity, including an implicit precision. The status indicates how the value should be understood and represented. If no status is specified, the value is a point value. The status element can never be ignored.
The units element must contain a displayable unit that defines what is measured. The units may additionally be coded in the code and the system, which is a URI, OID, or a SID that defines the code (see CodeableConcept (§1.3.6) for further information about system).
If the units are able to be coded in UCUM, and a code is provided, it SHOULD be a UCUM code. If a UCUM unit is provided in the code then a canonical value can be generated for purposes of comparison between quantities. Note that the units element will often contain text that is actually a valid UCUM unit, but it cannot be assumed that it does.
Use
Unless the Quantity element has a dataAbsentReason flag, it must contain at a value and a unit. If a code is present, a system is also required.
The context of use may frequently define what kind of quantity this is, and therefore what kind of units can be used. The context of use may additionally require a code from a particular system. The context of use may also restrict the values for status.
These are used as types in resource content models, but they are really just Quantity with some rules:
| Duration | The unit must be an amount of time, and a UCUM unit must be provided. |
| Distance | The unit must be an amount of length, and a UCUM unit must be provided. |
| Count | The value must a whole number, and the UCUM unit must be "1" |
| Money | The unit must be a currency, and the code must from ISO 4217 (system = "urn:hl7-org:sid/iso-4217") |
Examples
A duration:
<x>
<value>25</value>
<unit>sec</unit>
<code>s</code>
<system>urn:hl7-org:sid/ucum</system>
</x>
A concentration where the value was out of range:
<x>
<value>40000</value>
<status>></status>
<unit>mcg/L</unit>
<code>ug</code>
<system>urn:hl7-org:sid/ucum</system>
</x>
An amount of prescribed medication:
<x>
<value>3</value>
<unit>capsules</unit>
<code>385049006</code>
<system>http://snomed.info</system>
</x>
A price:
<x>
<value>25.45</value>
<unit>US$</unit>
<code>USD</code>
<system>urn:hl7-org:sid/iso-4217</system>
</x>
A set of ordered values defined by a low and high limit.
An interval may be applied to Quantity (§1.3.8), dateTime, and date. The context where the type is used must specify which of these types is used. An interval specifies a range of values; the context of use will specify whether the entire range applies (e.g. "the patient was an inpatient of the hospital for this time range") or one value from the range applies (e.g. "give the patient between 2 and 4 tablets").
<Interval xmlns="http://www.hl7.org/fhir"> <low> cond [param] Low value (Text or elements from specified type)</low> <high> cond [param] High value (Text or elements from specified type)</high> </Interval>
If the low or high elements are missing, the meaning is that the low or high boundaries are not known. A dataAbsentReason flag may be used on the low or high elements in this case. On intervals over a time period, if the high is missing, it means that the interval is current and ongoing.
If the interval applies to the Quantity (§1.3.8) type, the status flag on the quantity cannot have the values <, <=, =>, or >. Note that the Interval type should not be used to represent measurements where the status flag might be used instead.
When the interval applies to a date or dateTime, the high value includes any matching date/time. When the interval applies to the other types, the high value is assumed to have arbitrarily high precision. For example:
| 1.5 to 2.5 | includes 1.50, and 2.50 but not 1.49 or 2.51 |
| 2011-05-23 to 2011-05-27 | includes all the times of 23rd May through to the end of the 27th May |
Use
Unless the Interval element has a dataAbsentReason flag, it must contain a low and, if it does not apply to a date or dateTime, a high.
Examples
Interval of Quantity (distance):
<x>
<low>
<value>2.8</value>
<unit>m</unit>
</low>
<high>
<value>4.6</value>
<unit>m</unit>
</high>
</x>
23rd May 2011 to 27th May, including 27th May:
<x>
<low>
<date>2011-05-23</date>
</low>
<high>
<date>2011-05-27</date>
</high>
</x>
A ratio of two Quantity values - a numerator and a denominator.
<x xmlns="http://www.hl7.org/fhir"> <numerator> cond Quantity The numerator</numerator> <denominator> cond Quantity The denominator</denominator> </x>
Common factors in the numerator and denominator are not automatically cancelled out. The Ratio data type is used for titers (e.g., "1:128") and other quantities produced by laboratories that truly represent ratios. Ratios are not simply "structured numerics" and blood pressure measurements (e.g. "120/60") are not ratios. In addition, ratios are used where common factors in the numerator and denominator do not cancel out. The most common example of this is where the ratio represents a unit cost, and the numerator is a currency.
Use
Unless the Ratio element has a dataAbsentReason flag, it must contain a numerator and a denominator. The context of use may require particular types of Quantity for the numerator or denominator.
Examples
Titer (Ratio of integer:integer)
<x>
<numerator>
<value>1</value>
</numerator>
<denominator>
<value>128</value>
</denominator>
</x>
Unit cost (Ratio of Money:Quantity):
<x>
<numerator>
<value>103.50</value>
<unit>US$</unit>
<code>USD</code>
<system>urn:hl7-org:sid/iso-4217</system>
</numerator>
<denominator>
<value>128</value>
<unit>day</unit>
<code>day</code>
<system>urn:hl7-org:sid/ucum</system>
</denominator>
</x>
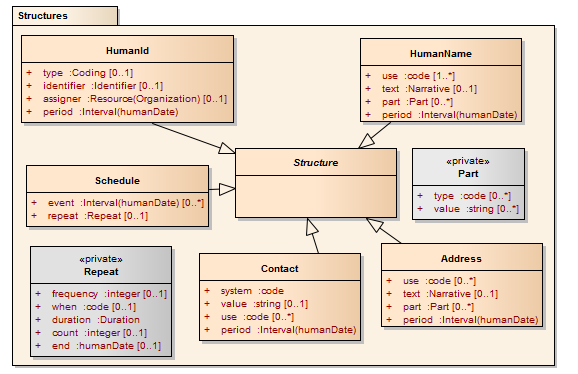
An identifier that humans use. This is different to a system identifier because identifiers that humans use are regularly changed or retired due to human intervention and error. Note that an human identifier may be a system identifier on some master system, but becomes a human identifier elsewhere due to how it is exchanged between humans. Driver's license nunmbers are a good example of this. Also, because human mediated identifiers are often invoked as implicit links to external business processes, such identifiers are often associated with multiple different resources. Human identifiers often have some type associated with them that is important to allow the identifier to be picked as a basis for exchange elsewhere, either in other electronic interchanges, or paper forms.
<x xmlns="http://www.hl7.org/fhir"> <type> opt Coding Code for identifier type</type> <identifier> cond Identifier Actual identifier</identifier> <period> opt Interval(dateTime) Time period when id was valid for use</period> <assigner> opt (Organization) Organisation that issued id</assigner> </x>
Terminology Bindings
| account | Account number | An identifier that is unique to an account. |
| credit | Credit Card Number | A credit card number (or debit card). |
| microchip | Microchip Number | implanted, for animals, or a worn RFID for humans |
| registry | A Registry Number | |
| insurance | Insurance Scheme Member Number | Identifies the person as a member of an insurance scheme. |
| national | National Healthcare Identifier | May not only be used for healthcare. |
| ssn | National Social Security Number | |
| state | State Healthcare Identifier | May not only be used for healthcare. |
| patient | Patient identifier | Frequently called MRN (medical record number) or UR (unit record number). |
| facility | Facility ID | |
| provider | Provider number | a number allocated to a person as a provider of healthcare resources. |
Note that in many cases, the assigner is used to indicate what registry/state/facility etc assigned the identifier. Another possible source for the type of an identifier is HL7 v2 table 0203.
The resource elements often use HumanId for an identifier that may be an external human mediated reference, or that may also come from a direct unambiguous reference to a resource, or may be from a seperate workflow, possibly human mediated. When the identifier is actually a direct resource reference, the type should be a resource type, the identifier.system should be the URL of the source system or, if a particular end point is not known, then "urn:hl7-org:sid/fhir/[X]" where "[X]" is the resource name , and the identifier.id should be the resource id.
Use
An identifier with an id element is required unless a dataAbsentReason flag is provided on the identifier element. If the HumanId is mandatory, then either an identifier.system or an type must be provided (In some cases, the type of the identifier will be known, but not the identifier.system. For instance, a driver's license number, where the state, province or country that issues the license identifier is unknown).
The assigner.id may be replaced with assigner.text when used with the dataAbsentReason "astext".
Examples
A US SSN:
<x>
<type>
<code>ssn</code>
<system>urn:hl7-org:sid/fhir/identifier-type</system>
</type>
<identifier>
<system>urn:hl7-org:sid/us-ssn</system>
<id>000111111</id>
</identifier>
</x>
Notes:
A medical record number assigned on 5-July 2009:
<x>
<type>
<code>patient</code>
<system>urn:hl7-org:sid/fhir/identifier-type</system>
</type>
<identifier>
<system>oid:0.1.2.3.4.5.6.7</system>
<id>2356</id>
</identifier>
<period>
<low>2009-06-05</low>
</period>
</x>
A name of a human, or a name given to an animal by a human.
Names may be changed, or repudiated, or people may have different names in different contexts. Names may be divided into parts of different type that have variable significance depending on context, though the division into parts does not always matter. With personal names, the different parts may or may not be imbued with some implicit meaning; various cultures associate different importance with the name parts, and the degree to which systems must care about name parts around the world varies widely.
<x xmlns="http://www.hl7.org/fhir"> <use> opt code The use of this name</use> <text> cond string Text representation of the full name</text> <part> cond <!-- Zero+ A part of a name --> <type> opt code Type of name part (see below)</type> <value> mand string The content of the name part</value> </part> <period> opt Interval(dateTime) Time period when name was/is in use</period> </x>
Terminology Bindings
| usual | Known as/conventional/the one you normally use | |
| official | The formal name as registered in an official (government) registry, but which name might not be commonly used. May be called legal name. | |
| temp | A temporary name. A name valid time can provide more detailed information. This may also be used for temporary names assigned at birth or in emergency situations. | |
| anonymous | Anonymous assigned name, alias, or pseudonym (used to protect a person's identity for privacy reasons) | |
| old | This name is no longer in use (or was never correct, but retained for records) | |
| maiden | A name used prior to marriage. Marriage naming customs vary greatly around the world. This name use is for use by applications that collect and store maiden names. Though the concept of maiden name is often gender specific, the use of this term is not gender specific. The use of this term does not imply any particular history for a person‘s name, nor should the maiden name be determined algorithmically | |
| family | Family name, this is the name that links to the genealogy. In some cultures (e.g. Eritrea) the family name of a son is the first name of his father. | |
| given | Given name. NOTE Not to be called first name since given names do not always come first. . | |
| title | Part of the name that is acquired as a title due to academic, legal, employment or nobility status etc. NOTE Title name parts include name parts that come after the name, such as qualifications. | |
The text element specifies the entire name as it should be represented. This may be provided instead of or as well as specific part elements. Every part must have a value.
Use
Either text or at least one part is required unless a dataAbsentReason flag is provided on the name element.
Example
Full name of Peter James Chalmers, with a preferred name of James.
<x>
<use>usual official</use>
<part>
<type>given</type>
<value>Peter</value>
</part>
<part>
<type>given</type>
<value>James</value>
</part>
<part>
<type>family</type>
<value>Chalmers</value>
</part>
</x>
See further examples
A postal address. There is a variety of postal address formats defined around the world. This format defines a superset that is the basis for addresses all around the world Note: address is for postal addresses, not physical locations.
<x xmlns="http://www.hl7.org/fhir"> <use> opt code The use of this address</use> <text> cond string Text representation of the address</text> <part> cond <!-- Zero+ --> <type> opt code Type of address part (see below)</type> <value> mand string The content of the address part</value> </part> <period> opt Interval(dateTime) Time period when address was/is in use</period> </x>
Terminology Bindings
| home | A communication address at a home. | |
| work | An office address. First choice for business related contacts during business hours. | |
| temp | A temporary address. The period can provide more detailed information. | |
| old | This address is no longer in use (or was never correct, but retained for records) | |
| part | Part of an address line (typically used with an extension that further defines the meaning of the part). | |
| line | A line of an address (typically used for street names & numbers, unit details, delivery hints etc) . | |
| city | The name of the city, town, village, or other community or delivery centre. | |
| state | sub-unit of a country with limited sovereignty in a federally organized country. A code may be used if codes are in common use (i.e. US 2 letter state codes). | |
| country | Country. ISO 3166 3 letter codes can be used in place of a full country name. | |
| zip | A postal code designating a region defined by the postal service. | |
| dpid | A value that uniquely identifies the postal address. (often used in barcodes). | |
The text element specifies the entire address as it should be represented. This may be provided instead of or as well as specific part elements. Every part must have a value.
Use
Either text or at least one part is required unless a dataAbsentReason flag is provided on the address element.
Example
HL7 office's address.
<x>
<use>work primary</use>
<text>
1050 W Wishard Blvd
RG 5th floor
Indianapolis, IN 46240
</html>
</text>
<part>
<type>city</type>
<value>Indianapolis</value>
</part>
<part>
<type>state</type>
<value>IN</value>
</part>
<part>
<type>zip</type>
<value>46240</value>
</part>
</x>
See further examples
All kinds of technology mediated contact details for a person or organisation, including telephone, email, etc.
<x xmlns="http://www.hl7.org/fhir"> <system> cond code What kind of contact this is</system> <value> cond string The actual contact details</value> <use> opt code How to use this address</use> <period> opt Interval(dateTime) Time period when the contact was/is in use</period> </x>
Terminology Bindings
| phone | the value is a telephone number used for voice calls. Use of full international numbers starting with + is recommended to enable automatic dialing support but not required. | |
| fax | the value is a fax machine. Use of full international numbers starting with + is recommended to enable automatic dialing support but not required. | |
| the value is an email address | ||
| url | The value is a url. This is intended for various personal contacts including blogs, twitter, facebook etc. Do not use for email addresses | |
| home | A communication contact at a home; attempted contacts for business purposes might intrude privacy and chances are one will contact family or other household members instead of the person one wishes to call. Typically used with urgent cases, or if no other contacts are available. | |
| work | An office contact. First choice for business related contacts during business hours. | |
| temp | A temporary contact. The period can provide more detailed information. | |
| old | This contact is no longer in use (or was never correct, but retained for records) | |
| mobile | A telecommunication device that moves and stays with its owner. May have characteristics of all other use codes, suitable for urgent matters, not the first choice for routine business | |
The value should be a properly formatted telephone number according to ITU-T E.123, but this is frequently not possible due to legacy data and/or recording methods.
Use
A value is required unless a dataAbsentReason flag is provided on the contact element. A system is required if a value is provided.
Example
Phone number for some one who works at home:
<x> <system>phone</system> <value>+15556755745</value> <use>home</use> </x>
See further examples
A schedule that specifies an event that may occur multiple times. Schedules are not used for recording when things did happen, but when they are expected or requested to occur. A schedule can be either a list of events - intervals on which the event occurs, or a single event with repeating criteria, or just repeating criteria with no actual event.
Note: a possible enhancement to this is to have the repeat content repeat with each event. This is richer and more complex - is the added functionality useful?
<x xmlns="http://www.hl7.org/fhir"> <event> mand Zero+ Interval(dateTime) When the event occurs</event> <repeat> opt <!-- Only if there is none or one event --> <frequency> cond integer Event occurs frequency times per duration</frequency> <when> cond code Event occurs duration from common life event</when> <duration> mand Duration repeating or event-related duration</duration> <count> cond integer number of times to repeat</count> <end> cond dateTime when to stop repeats</end> </repeat> </x>
Terminology Bindings
| HS | event occurs duration before the hour of sleep (or trying to) | |
| WAKE | event occurs duration after waking | |
| AC | event occurs duration before a meal (from the latin ante cibus) | |
| ACM | event occurs duration before breakfast (from the latin ante cibus matutinus) | |
| ACD | event occurs duration before lunch (from the latin ante cibus diurnus) | |
| ACV | event occurs duration before dinner (from the latin ante cibus vespertinus) | |
| PC | event occurs duration after a meal (from the latin post cibus) | |
| PCM | event occurs duration after breakfast (from the latin post cibus matutinus) | |
| PCD | event occurs duration after lunch (from the latin post cibus diurnus) | |
| PCV | event occurs duration after dinner (from the latin post cibus vespertinus) | |
If events are specified, at least a low must be specified for each event. If no high is specified, the event is assumed to last a limited but unknown time as clinically relevant.
If the schedule has repeating criteria, the repeat can occur a given number of times per the specified duration, or in relation to some real world event. Also, if the event repeats, a time to end the schedule can be specified, either by specifying a count number of times it can occur, or a date at which to end the schedule. If no end condition is specified, the Schedule will terminate on some criteria which is expressed elsewhere.
There are 3 rules concerning the contents of a Schedule:
Use
At least one event or a repeat is required unless a dataAbsentReason flag is provided on the Schedule element. If a repeat is present, either frequency or when is required.
Example
A series of appointments for radiotherapy:
<x>
<event>
<low>2012-01-07T09:00</low>
<high>2012-01-07T13:00</high>
</event>
<event>
<low>2012-01-14T09:00</low>
<high>2012-01-14T13:00</high>
</event>
<event>
<low>2012-01-22T11:00</low>
<high>2012-01-22T15:00</high>
</event>
</x>
BID (twice a day) (no start or end specified):
<x>
<repeat>
<frequency>2</frequency>
<duration>
<value>1</value>
<units>day</units>
<code>d</code>
<system>urn:hl7-org:sid/ucum</system>
</duration>
</repeat>
</x>
1/2 an hour before breakfast for 10 days from 23-Dec 2011:
<x>
<event>
<low>2011-12-23</low>
</event>
<repeat>
<when>ACM</when>
<duration>
<value>30</value>
<units>min</units>
<code>min</code>
<system>urn:hl7-org:sid/ucum</system>
</duration>
<end>2012-01-02</end>
</repeat>
</x>
Note that the end date is inclusive like the high date of an Interval.
With regard to the UML models, see notes about the UML Object models (§1.2.8), and particularly the note regarding the UML representation of dataAbsentReason (§1.4)
This specification describes the use of the dataAbsentReason attribute, which is used throughout the content models on elements of any type to indicate missing data. The dataAbsentReason attribute "may appear on any element in a resource other than those marked mandatory".
In Object-Orientated paradigms, the dataAbsentReason is a mixin. The definition of a mix-in is that it is an abstract class that provides functionality that is not inherited by specialization but rather by collecting functionality. A mixin can be thought of as a generic class that specializes it's parameter class:
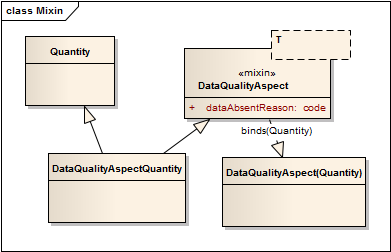
This shows a mixin called "DataQualityAspect" which expresses the attribute "dataAbsentReason". The two derived classes, DataQualityAspectQuantity which inherits both Quantity and DataQualityAspect and DataQualityAspect(Quantity), which binds Quantity to the paramter T on the DataQualityAspect mixin both have the same semantics (are identical other than their type derivation).
The problem with this approach is that not only is the <<mixin>> stereotype not a recognised standard UML sytnax, but most mainstream programming languages cannot implement multiple inheritence in this form. There is two alternative approaches for implementing this in these platforms. The first is using a wrapper class:
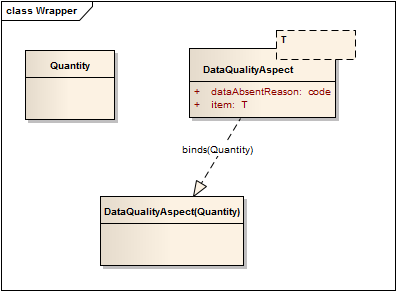
The problem with this variation is that Quantity and DataQualityAspect(Quantity) are no longer both types of Quantity, as with a pure mixin, and this will have a series of knock on effects in implementations. The other alternative is simply to make DataQualityAspect a base class:
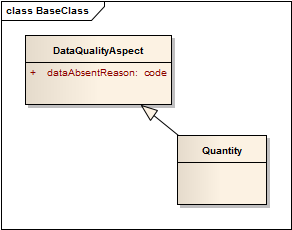
This is the simplest approach, but has the disadvantage that all instances of the Quantity data type carry the dataAbsentReason attribute, whether it is appropriate or not.
Implementors that use these objects in an environment where mixins are not supported must choose either of these two approaches. For simplicity, the object models defined in this specification simply bind the target type directly to the specified data type, and ignore the issue of the dataAbsentReason mixin.
Note that the dataAbsentReason may also be associated with primitive types as well.
Throughout the FHIR specification, many elements are assigned a type of either code, Coding (§1.3.6.1), or CodeableConcept (§1.3.6). These elements are bound to a "Concept Domain", which defines the set of concepts that may be associated with the element. Each Concept Domain has a formal definition, and a binding type that may define a particular set of acceptable concepts:
| Code List | The concept is directly bound to a code list defined in this specification (mostly used with elements of type "code"). In some circumstances, other additional codes may be used (not for elements with type "code") |
| External | The possible list of codes (concepts) is defined by an external specification, usually ISO or W3C. A reference is provided |
| Preferred | The concept domain is bound directly to an external coding system, and values from this coding system must be use if appropriate values exist |
| Unbound |
The FHIR specification does not bind the concept domain to any particular set of concepts (a value set).
Instead, jurisdictions, Institions, projects or applications bind the concept domain. Within the unbound concept domains, FHIR may recommend a particular value set (or coding system), or suggest values as illustrative |
Note that this approach is based on the framework defined in the HL7 V3 core principles in section 5.1. Also note that when a CodeableConcept has a concept domain, this means that one of the codes in the coding list meet the binding of the concept domain, and all the codes must conform to the definition of the concept domain.
This specification defines the following names (URIs) as fiexed names that may be used in the system element of the Identifier (§1.3.5), Coding (§1.3.6.1) or (§1.3.6) data types.
| URI | Source | Comment | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Code Systems | ||||||||||||||
| http://snomed.info | SNOMED-CT: (IHTSDO) | The version, module etc may be appended to this uri following the IHTSDO specifications OID=2.16.840.1.113883.6.96 |
||||||||||||
| urn:hl7-org:sid/loinc | LOINC (LOINC.org) | The LOINC sid can also be used to indicate a LOINC property value by append one of the following values to the URL:
The acceptable values for these URLs are the literal values found in the definition of LOINC for the given column name. |
||||||||||||
| urn:hl7-org:sid/ucum | UCUM: (UnitsOfMeasure.org) | Generally used in the Quantity Data Type OID=2.16.840.1.113883.6.8 |
||||||||||||
| urn:hl7-org:sid/icd-10 | ICD-10 International (WHO) | OID=2.16.840.1.113883.6.3 |
||||||||||||
| urn:hl7-org:sid/icd-9 | ICD-9 USA (CDC) | OID=2.16.840.1.113883.6.42 |
||||||||||||
| urn:hl7-org:sid/v2-[X] | Version 2 table code | [X] is the 4 digit identifier for a table. i.e. urn:hl7-org:sid/v2-0203 OID=2.16.840.1.113883.12.[X] |
||||||||||||
| urn:hl7-org:sid/iso-639 | Language Codes as defined in (ISO 639) | 3 letter codes known as 639-3 OID=1.0.639.3 |
||||||||||||
| urn:hl7-org:sid/iso-4217 | Currency Codes as defined in (ISO 4217) | 3 digit currency designators OID=1.0.4217 |
||||||||||||
| urn:hl7-org:sid/atc | Anatomical Therapeutic Chemical Classification System (WHO) | OID=2.16.840.1.113883.6.73 |
||||||||||||
| Identifier Systems | ||||||||||||||
| urn:hl7-org:sid/uri | URIs (W3C) | As defined by various applicable RFCs including X No OID |
||||||||||||
| urn:hl7-org:sid/oid | OIDs | The identifier is an OID itself | ||||||||||||
| urn:hl7-org:sid/uuid | UUIDs | Also called GUIDs No OID |
||||||||||||
| urn:hl7-org:sid/us-ssn | SSN (W3C) | SSN for USA. Represented with dashes removed OID=2.16.840.1.113883.4.1 |
||||||||||||
In addition to this, a number of code sytems are defined informally through the specification. This table enumerates them, and assigns sid and OID values for them, though these are not generally used directly in this specification:
| Special Values (§1.5.3) | urn:hl7-org:sid/fhir/special-values | 2.16.840.1.113883.6.305 |
| Resource Types | urn:hl7-org:sid/fhir/resources | 2.16.840.1.113883.6.306 |
| Logical Interactions (RESTful framework) | urn:hl7-org:sid/fhir/interactions | 2.16.840.1.113883.6.308 |
| Message Events (§2.5.3) (Messaging framework) | urn:hl7-org:sid/fhir/message-events | 2.16.840.1.113883.6.307 |
| Data Absent Reason (§1.2.2) | urn:hl7-org:sid/fhir/data-absent-reason | 2.16.840.1.113883.6.309 |
Note that all the codes in these code systems are case sensitive, and must be used in lowercase.
Internally defined codes useful throughout the specification where Coding (§1.3.6.1) or CodeableConcept (§1.3.6) is used. These are defined by the code system "urn:hl7-org:sid/fhir/special-values" which has OID 2.16.840.1.113883.6.305.
| true | Boolean true |
| false | Boolean false |
| trace | The content is greater than zero, but too small to be quantified (used in formulations) |
| sufficient | The specific quantity is not known, but is known to be non-zero and is not specified because it makes up the bulk of the material. (e.g. 'Add 10mg of ingredient X, 50mg of ingredient Y, and sufficient quantity of water to 100mL.' The null flavor would be used to express the quantity of water. ) |
| withdrawn | The correct value is no longer available |
In several places, the resource types themselves are used as codes, with the sid, where required, of "urn:hl7-org:sid/fhir/resource-types". This is a formal list of such codes:
| Conformance (§2.4) | A conformance statement returned by request in an RESTful framework |
| Document (§3.6) | A documentation of clinical observations and services that are aggregated together into a single statement of clinical meaning that establishes it's own context. A clinical document is composed of a set of resources that include both human and computer readable portions. A human must attest to the accuracy of the human readable portion, and may authenticate and/or sign the entire whole |
| Message (§2.6) | A message that contains FHIR resources |
| Animal (§3.2) | An animal that has relevance to the care process -usually this is for animals that are patients. |
| Agent (§3.4) | A person who represents an organisation, and is authorised to perform actions on it's behalf |
| MessageConformance (§2.7) | A conformance statement about how an application uses FHIR messaging |
| Organization (§3.3) | For any organization/institution/government department that has relevance to the care process |
| Prescription (§5.1) | Directions provided by a prescribing practitioner for a specific medication to be administered to an individual |
| Profile (§2.11) | A Resource Profile - a statement of constraint on one or more Resources and/or Concept Domains |
| InterestOfCare | Yet to be defined |
| Admission | Yet to be defined |
| Specimen | Yet to be defined |
| Device | Yet to be defined |
| Patient (§3.5) | A patient is a person or animal that is receiving care |
| Group | Yet to be defined |
| Person (§3.1) | A person who is involved in the healthcare process |
| LabReport (§4.1) | The findings and interpretation of pathology tests performed on tissues and body fluids. This is typically done in a laboratory but may be done in other environments such as at the point of care |
| DocumentConformance (§2.9) | A conformance statement about how one or more FHIR documents |
This exchange specification is based on generally agreed common requirements across healthcare - many jurisdications, domains, and different functional approaches. As such, it is common for specific implementations to have valid requirements that will not be adopted by this specification. Adopting all of these requirements would make this specification very cumbersome and difficult to implement. Instead, this specification expects that these additional common requirements will be implemented as extensions.
As such, extensibility is a fundamental part of the design of this specifications. Every resource includes an extensions section that may be used to represent additional information that is not part of the basic definition of the resource. Conformant applications are not allowed to reject resources because they contain extensions, though they may need to reject resources because of the specific contents of the extensions.
Note that unlike in many other specifications, there can be no stigma associated with the use of extensions by any application, project, or standard, whatever institution or jurisdiction uses or defines them; their use of such extensions is what allows the specification to retain a core simplicity for everyone.
In order to make the use of extensions safe, and manageable, there is a strict governance applied to the definition and use of extensions. Though any implementer is allowed to define an extension, there is a set of reqiurements that must be met as part of the definition of the extension.
Each resource includes the optional extensions element before the narrative element at the end of the resource.
<x xmlns="http://www.hl7.org/fhir"> <code> mand id Code that identifies the meaning of the extension</code> <definition> mand uri Source of the definition for the code</definition> <ref> opt id Internal reference to context of the extension (xml:id)</ref> <state> opt code must-understand | superceded</state> <value[x]> cond Value of extension</value[x]> <extension> cond <!-- Zero+ Nested Extensions --> <!-- Content as for Extension --> </extension> </x>
Terminology Bindings
| must-understand | The extension contains information that qualifies or negates another element, and must be understood by an application processing the resource | |
| superceded | The extension has been promoted into the main content of the resource, and the content is found at the reference. The extension continues to be defined for backward compatibility | |
Notes:
As well as providing additional undescribed information, extensions may be used to qualify the meaning of other elements in a way that makes them unsafe to ignore, or even to negate the meanings of other elements. Such extensions must have a state of "must-understand". Over time, an extension may be promoted to become part of the resource itself. In order to properly send the data, the extension should still be present, but should have no value element. Instead, the state of the extension is "superceded", and the ref points to the correct location for the data.
Any application processing the data of a resource must check for extensions with state="must-understand". If the application does not recognise the code on an extension that is labeled "must-understand", and where the extension either has no internal reference, or the reference is data processed by the application, it SHALL either refuse to process the data, or carry a warning concerning the data along with any action or output that results from processing the data. Note that it must always be safe to show the narrative to humans; any extension that is labelled as must-understand must be represented in the narrative. Applications are encouraged to ignore un-required extensions that they do not recognise. Applications that do not accept unknown extensions should declare this in their conformance statement.
The value[x] element has the [x] replaced with the name of one of the defined types, and the contents as defined for that type, or another extension. The value type may be one of the following:
Nested extensions cannot have a ref element. The [type] element is optional unless the definitions of the extension codes make rules about it. Extensions can never have a default value.
Extensions may be defined by any project or jurisdication, up to and including international standards organisations such as HL7 itself.
Extensions are always defined against some particular context. The following are possible contexts for an extension:
In addition, an element definition might apply additional constraints with regards to particular element values of the target that make it's use appropriate. Extensions SHALL only be used in the contect against which they are defined.
Each extension is defined using the following fields:
todo: metadata, context
| Code | Required | The code that is used in a resource to identify this extension |
| Context | Required | The context of this extension. See below |
| TargetType | Optional | The type of the path to which this applies, if it matters. This must be a valid FHIR data type as described above |
| Cardinality | Required | The cardinality of this extension. Specifying a minimum cardinality of 1 means that if the source system declares that it conform to the set of extensions containing this extension, it must be included in the resource |
| Conformance | Required | Whether the use of the extension is mandatory, conditional, optional, or prohibited. If the extension is conditional, the conditions must be described in the comments field. This field overlaps with the cardinality, and must be consistent with it. |
| Type | Required | The type(s) of the extension. This must be a valid FHIR data type as described above, or "Extension: x,y,z" which indicates that the extension codes x,y, and z will be contained in the extension |
| Concept Domain | Conditional | For the types CodeableConcept and Coding. see Terminologies (§1.5) |
| Must Understand | Required | Whether the extension must be understood by any system reading the resource. There is 3 possible values: "true" - the extension must be understood, "false" - the extension does not need to be understood, and "sender" - the sender can decide whether the extension needs to be understood |
| Definition | Required | A formal statement of the meaning of the content of the field |
| Requirements | Required | Discussion of the reason for the extension / what use cases it was defined to handle |
| Comments | Optional | Additional other information about the extension, including information concerning it's conditionality if indicated in the conformance field |
| RIM Mapping | Conditional | The formal mapping from this extension to the RIM. Required for HL7 defined extensions, but may be optional in other contexts |
| v2 Mapping | Optional | Mapping to a v2 segment/field/etc, if desired and appropriate. |
Notes:
Whenever resources containing extensions are exchanged, the definitions of the extensions must be available to all the parties that share the resources. Each extension contains a URI that references the source of the definitions. The source can be a literal reference, such as an http: url that refers to an end-point that responds with the contents of the definitions, or a logical reference (e.g. using a urn:) - for instance, to a national published standard. Literal references are preferred.
Whether the reference is a literal or logical reference, the extension definitions must be published using the fields defined as above. They may be published in narrative form, possibly as part of a larger specification. This narrative form is for human consumption. In addition, they may be published in a structured form, as either a csv file, or an XML file. The CSV file should have the fields described above as columns in the order described above, with a title row containing the case sensitive field names as above. XML files should use the format described in the XML Definitions schema (note that element and extension definitions from FHIR itself also use the same format).
Todo: extension packs & metadata Control * resources are balloted * implementations (jurisdictions, institutions, projects) must publish their extensions through HL7 extension registry/repository (will be distributed?) * extensions may be submitted to HL7 for endorsement. Committees approve them by in-committee vote, and then HL7 publishes them with endorsement * extensions should never be redefined once in used. (endorsed extensions can't have their RIM mappings changed)
As well as defining the base element structure for resources, HL7 also publishes extensions. When HL7 itself publishes extensions as part of the FHIR specification, these extensions must be used for this data whenever the data is represented in instances. HL7 publishes data definitions as extensions rather than as part of the base resource structure in order to keep the base resource structure simple and concise, and to allow implementors not to engage with an entire world's worth of functionality up front. Note that HL7 extensions are never flagged as must-understand - if HL7 publishes resource content that must be understood, it will be part of the resource content itself, since everyone has to understand it anyway.
Implementations are encouraged to share their extensions with HL7; the domain committees will work to elevate the extensions into HL7 published extensions or the into the base resource structure itself.
This specification describes a set of base resources that are used in many different contexts in healthcare. In order to make this manageable, applications need to be able to provide a structured statement of which elements of a resource are used, and how. In addition the existing elements, the use of extensions also needs to be described. These structured statements are actually constraint statements that describe a particular pattern of usage. As a general tool, they find use in several different contexts:
The final form of these conformance descriptions is a constraint statement, which may be used at run time to assist with application to application negotiation, or it may be used at design time or even purchase time to assist implementers to understand the capabilities of the system. This specification uses the general constraint statement defined here in 4 contexts:
The constraint statement is a fixed XML format that is used to represent the core part of these various descriptions of use, which is the actual contents of a resource.
One common operation in a constraint statement is to take an element that may occur more than once, and describe a series of different constraints on the elements in the list. In this way, the list is split into a series of individual elements or sub-lists. In FHIR, this operation is known as "unpicking" a list. Here is an example to illustrate the process:
| Resource Definition | Profile for Acme, Inc | ||
|---|---|---|---|
| relationship [0..*] type : Coding name : string |
parent [1..2] type = PAR name... guardian [0..1] type = GUARD name... child [0..6] type = CHILD name... |
In this example, the resource definition defines the relationship element which may occur multiple times. The profile for Acme, Inc constrains the relationships into 3 different kinds: 1 or 2 parents, up to 6 children, and maybe a guardian. No other relationships are supported by the Acme system.
Note that in FHIR, only the resource is ever actually exchanged. The profile describes a way of using the resource, but the item profile names ("parent", etc in this list) are never exchanged. In order the unpicking to be useful, systems must be able to determine which relationships in the relationship list that is actually exchanged are parent, child, or guardian; in this particular case, the determination is achieved by fixing the value of the relationship type element. Fixing a code value is the most common way to unpick a list.
Note that the context of appearing will make it clear whether this resource constraint specification is written from the context of the resource instance, a writing or a reading application
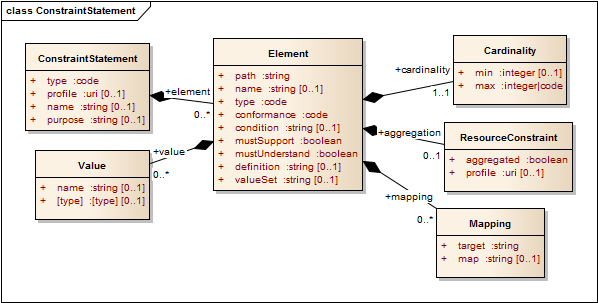
<x xmlns="http://www.hl7.org/fhir"> <type> mand code The Type of the resource being described</type> <profile> cond uri Resource Profile that supplies the constraints</profile> <name> opt string Name for this Constraint Statement</name> <purpose> opt string Human summary: why describe this resource?</purpose> <element> cond <!-- Zero+ --> <path> mand string The path of the element (see the formal definitions)</path> <name> opt string Name this constraint for re-use & unrolling</name> <purpose> opt string Human summary: why describe this element?</purpose> <min> mand integer Minimum Cardinality</min> <max> mand code Maximum Cardinality (a number or *)</max> <type> opt code Type of the element</type> <conformance> mand code Mandatory|Conditional|Optional|Prohibited</conformance> <condition> cond string Condition if conformance=Conditional</condition> <mustSupport> opt boolean If the element must be usable</mustSupport> <mustUnderstand> opt boolean If the element must be understood</mustUnderstand> <definition> opt string More specific definition</definition> <mapping> opt <!-- Zero+ --> <target> mand string Which mapping this is (v2, CDA, openEHR, etc)</target> <map> opt string Details of the mapping</map> </mapping> <resource> cond <!-- If context includes aggregation and type=Resource() --> <aggregated> mand boolean Whether this resource is aggregated</aggregated> <profile> opt uri Reference to a Resource Profile</profile> </resource> <valueSet> opt string Value set id (only if coded)</valueSet> <value> opt <!-- Zero+ --> <name> cond string Reference to another element by element.name</name> <[type]> cond Fixed value: [as defined for type]</[type]> </value> </element> </x>
Terminology Bindings
| Mandatory | The element is or must always be present without a dataAbsentReason | |
| Conditional | The element may need to be present (with no dataAbsentReasons) depending on the condition | |
| Optional | The element may or may not be present | |
| Prohibited | The element can not present or will be rejected if received | |
Notes:
TODO: Is any control over narrative required?
The formal definitions for the elements above. Also available as an XML file.
While the FHIR Resources are designed with a simple RESTful HTTP-based implementation (§2.3) in mind, it is not necessary to use this implementation framework. This specification also defines a straight messaging based implementation framework (§2.5) for FHIR resources, and a document-based framework (§2.8), as well as documenting how FHIR resources are used with hData (§2.10).
Alternatively, it is not necessary to use any of these approaches; resources can be exchanged or persisted using any technical means that is appropriate to the context at hand. A common use of FHIR resources or aggregations is as parameters of service interfaces. FHIR itself does not define any particular service interface; instead, other standards and implementations define their own service interfaces and architecture that use FHIR resources. As long as the resources that are used are conformant with regard to this specification, and the rules for authoring and reading applications are followed, then the implementation can claim conformance to "FHIR Resources". Such implementations will need to resolve several issues:
The resolution to these issues should be documented and published somewhere.
Given these options, there are many ways to implement any particular workflow. There are many ways to use resources to build working systems:
General Resources:
Resource specific resources:
Note: the JSON examples are simply the XML examples auto-converted to JSON by the json.org code. TODO: Add note about why JSON is included.
All of these resources except the JSON format are normative (i.e. Ballot comments may be made against these resources with regard to their correctness, other comments may be ruled out of scope). The reference implementations below are informative, and not subject to ballot.
Reference implementations are provided for implementer interest and assistance. Other implementations can be used, including code generated from the schemas.
This is a list of the all the default values defined in the FHIR specification:
One basic operation performed with resources is to aggregate a group of resources into a single XML document. This is performed in many of the implementation frameworks. Aggregated resources are useful for grouping resources together for a variety of different reasons, including:
Resources are aggregated using the Atom format (http://tools.ietf.org/html/rfc4287), following this template:
<feed xmlns="http://www.w3.org/2005/Atom" xmlns:gd="http://schemas.google.com/g/2005"> <title mand type="string">text statement of purpose</title> <updated mand type="dateTime">when aggregation happened</updated> <id mand type="id">unique id for this aggregation</id> <link mand rel="via" href="aggregating application url"/> <entry gd:etag="version id"> <!-- Zero+ --> <title mand type="string">text summary of resource</title> <link mand rel="self" href="Master Location for Resource"/> <id mand type="id">Master Id for this resource</id> <updated mand type="dateTime">Last Updated for resource</updated> <published opt type="dateTime">Time resource sourced for aggregation</updated> <author> <name mand type="string">Name of Human or Device that authored the resource</name> <uri opt type="uri">Link to the resource for the author</uri> </author> <category term="[Resource Type]" scheme="urn:hl7-org:sid/fhir/resource-types"/> <content mand type="text/xml"> <[ResourceName] xmlns="http://www.hl7.org/fhir"> <id mand type="id">Resource Id (i.e. normal resource content)</id> <!-- Content for the resource --> </[ResourceName]> </content> <summary opt type="xhtml"> <!-- Narrative from resource for a browser. Must be wrapped in a <div> --> </summary> <Signature xmlns="http://www.w3.org/2000/09/xmldsig#" opt> <!-- Enveloped Digital Signature (see Atom section 5.1) --> </Signature> </entry> </feed>
Notes:
Readers of the aggregated resources should always look through the resources in the atom feed when a resource reference (§1.2.4) is encountered. The resource reference will have the resource type and the id of the target, like this:
<institution>
<type>Organization</type>
<id>1145c09c-73d0-4297-9835-620e4afa9deb</id>
</institution>
A reader trying to find this institution should always look through the entries in the atom feed prior to looking anywhere else for the institution. If that organization is in the feed, it would look like this:
.. feed ..
<entry>
..
<id>1145c09c-73d0-4297-9835-620e4afa9deb<id>
..
<category term="Organization" scheme="urn:hl7-org:sid/fhir/resource-types"/>
<content type="text/xml">
<Organization xmlns="http://www.hl7.org/fhir">
<id>1145c09c-73d0-4297-9835-620e4afa9deb</id>
<!-- other Content for the resource -->
</Organization>
</content>
... feed ...
It would also be possible to locate the resouce by the url (todo: explanation of this method).
FHIR resources make use of XML id attributes as targets for pointers elsewhere in the document. XML id attributes must be unique in the context of a single XML document, and the atom feed is a single XML document. it can be difficult and time consuming - or impossible in the presence of a digital signature - to fix the id attributes so they are unique when aggregating resources. For this reason, it is highly recommended that all XML id attributes are prefixed with the type and master id of the resource, like this: [Type]_[master id]_id (e.g. Person_23442_1).
For the same reasons as resources (§1.2.7), it is useful to define a standard JSON representation of the atom format. Several existing JSON representations of the atom feed are in general use; this specification adopts the Google GData representation.
Note: All of the existing JSON representations of Atom are lacking in simplicity. The Google conversion is at least algorithmic.
The standard RESTful endpoints (such as [baseurl]/people/#{id}.xml for a Person resource, or [baseurl]/documents/#{id}.xml) handle the individual resources, and not aggregations (though, per the restful spec, they may serve up aggregations for the history (§2.3.11) and update (§2.3.8) operations). There is a special end-point for aggregations at the relative url "/assemblies", which supports the following operations:
| Instance | |
| read | Retrieve an aggregation |
| vread | Not supported - aggregations have no version history |
| update | Not supported - aggregations never change |
| delete | Delete an aggregation |
| validate | Check that the content would be acceptable as an update |
| history | Not supported - aggregations never change |
| transaction | Not supported |
| Manager | |
| search | Search the aggregations based on some filter criteria. Supported search parameters
|
| create | Create an aggregation (i.e. post to the server. The ID is assigned by the client) |
| updates | Get a list of updates to resources of this type, optionally with some filter criteria |
| transaction | Not supported |
| conformance | Not supported (no conformance statement for aggregations directly) |
| schema | Not supported (no schema for FHIR atom directly) |
For all these resources, the id (as used in the RESTful transactions (§2.3)) is the unique id of the aggregation. Note that creating an aggregation does not mean that any apparent implied transactions in the resources found in the aggregation should be applied to the server resources and/or executed by any system - specific transaction are required, either using the RESTful or messaging frameworks, or a SOA implementation.
In addition to defining a set of base resources, FHIR also provides a RESTful implementation using HTTP. Each resource type has the same set of interactions defined that can be used to manage the resources in a highly granular fashion. Applications claiming conformance to this framework claim to be conformant to "RESTful FHIR".
Note that this RESTful framework adheres as closely as possible to the REST principles. Transactions are performed directly on the server resource using an HTTP request/response. The HTTP calls may be authenticated against a single user account (including using OAuth), but this doesn't cater for common transaction metadata such as multiple users, responsible party, reasons, consents etc that is commonly encountered in healthcare. Instead, it is assumed that appropriate security and logs are managed by the client (perhaps through using ATNA), and the server trusts the client to maintain these. One implication of this is that this RESTful framework is only suitable for use where such trust relationships exist (e.g. in a single institution), and not suitable where such trust does not exist (e.g. state & national EHR systems, and general internet-based ecosystems). Similarly, this simple RESTful interface has no support for explicit archiving, for instance. These type of more sophisticated usages should consider a messaging (§2.5) or SOA-based approach (§2.1.1), or some kind of profiled REST interface, such as hData (§2.10).
The following logical interactions are supported:
| Instance | |
| read (§2.3.6) | Read the current state of the resource |
| vread (§2.3.7) | A version specific read of the resource |
| update (§2.3.8) | Update an existing resource by it's id (or create it if it is new) |
| delete (§2.3.9) | Delete a resource |
| validate (§2.3.10) | Check that the content would be acceptable as an update |
| history (§2.3.11) | Retrieve the update history for the resource |
| transaction (§2.3.15) | Support for specific transactions defined on the resource |
| Manager | |
| search (§2.3.12) | Search the resource type based on some filter criteria |
| create (§2.3.13) | Create a new resource with a server assigned id |
| updates (§2.3.14) | Get a list of updates to resources of this type, optionally with some filter criteria |
| transaction (§2.3.15) | Support for specific transactions defined on the resource type |
| conformance (§2.3.16) | Get a conformance statement for support of this resource type |
| schema (§2.3.17) | Get the XML schema for this resource |
Note that while these same logical interactions are defined on all resources, applications are not required to implement all of them. An application's conformance statement (§2.4) must say what logical interactions are supported.
Each resource lives at a specific location with a known URL which is automatically determined from the id, the resource type, and the base url of the system.
The concept of the base URL is defined because because this specification defines an interface rather than any particular system. The base URL is the address at which all the resources defined by this interface are found. The base URL takes the form of
http(s)://server/path
The path may end with a trailing slash or not. Each resource defined in this specification has a manager that lives at the address "/[type name]" where type name is the name of the type in lower case and plural. So, for instance, the resource manager for the type "Patient" will live at:
http://server/path/patients
Note that applications may need to remove the trailing slash from the base URL when appending the resource address. All the logical operations are provided relative to the address of the resource and defined in these terms below. Note that this means that given the address of any one resource on a system, the correct address for all the other resources may be determined. However since application URLs may change, and because local configuration may dictate that the provider of a resource is different to that claimed by any particular provider or consumer, applications should be adroit at replacing base URLs.
For all interactions, if the requested resource is returned as requested, the HTTP status 200 OK should be used (except for "create" where the status code should be 201). If the resource is not known, the server should return an HTTP status code 404 Not Found. Other HTTP errors may be returned as appropriate.
An HTTP redirect should not be used to indicate that the master id has changed. This is because the ids are treated as stable references elsewhere and used for matching. Changing an id will cause problems with this matching. Redirects may be issued to redirect to a new base URL, or to a master system for a given resource.
Each resource has an associated set of resource metadata. These map to the http request and response using the following fields:
| Metadata Item | HTTP Response Header |
|---|---|
| Version Id | ETag |
| Last Modified Date | Last-Modified |
| Master Location | Content-Location |
For this specification, normal HTTP security and authentication rules apply. The base URL will specify whether SSL is required. HTTP authentication, including possibly the requirement for client certificates, may be required by the provider. It is a matter of application requirements and local configuration whether all interactions run under the account of a trusted system user, or whether each interaction runs under the account of the individual user.
All the URLs defined below may be extended to support the OAuth protocol.
This same RESTful protocol may be used with either the XML or JSON representations defined for resources (§1.2). The mime types text/xml and application/json are to be used in the HTTP Content-Type or Accept header respectively to indicate which form is the requested or returned content takes . In addition, the URLs defined below may have the file extensions .xml or .json may be appended to the URL where appropriate, as indicated by (.ext) below. For reasons of general compatibility, servers and clients may accept application/xml, but must specify text/xml themselves.
Servers are required to support the XML form. Support for the JSON format is optional. Servers must support the Content-Type and Accept headers. Because of established browser behaviour, file extensions in the URL overrule the values specified in the headers.
The read interaction accesses the current contents of a resource. The interaction is performed by an HTTP GET operation as shown:
GET [baseurl]/[resourcetype]/{@id} (.ext)
This returns a single instance with the content that which is specified for the resource type. This url may be accessed by a browser. The id is preceded by a ":" to make parsing the url easier. The possible values for the id itself are described in the Resource Type (§1.2.4). The http headers ETag, and Last-Modified must be returned by the server, and the Content-Location should be returned.
The vread interaction preforms a version specific read of the resource. The interaction is performed by an HTTP GET operation as shown:
GET [baseurl]/[resourcetype]/{@id}/version-{:vid} (.ext)
This returns a single instance with the content that which is specified for the resource type. This url may be accessed by a browser. The http headers ETag, and Last-Modified, must be returned by the server, and are the values that apply for this version of the resource.
The version id is an opaque identifier that conforms to the same format requirements as a resource id. The id may be found by performing a history operation (see below), by recording the ETag return with a normal fetch operation, or from a version specific reference in a content model. The vread interaction should succeed even after a resource is deleted as long as a correct version identifier is provided.
The update interaction changes an existing resource, or creates a new resource of it doesn't already exist. The update interaction is performed by an HTTP PUT operation as shown:
PUT [baseurl]/[resourcetype]/{@id} (.ext)
The server returns a copy of the newly updated resource (which may not be the same as that submitted) with the response.
Servers may choose to require version checking, and only accept submitted updates that have an If-Match header that contains a matching version id for the current version of the resource. According to the http specification, it's up to the client to decide whether to provide an If-Match header, and if it does, the server must observe it. On normal update operations the client should not provide an If-Match header, and if the server wishes to receive it, it should return a 412 error with the words "If-Match" in the response text. Upon receiving this error, the client should resubmit with the If-Match header, if it is able. The Last-Modified dateTime may not suitable for concurrency checking as it only has a resolution limit of per-second, and there are other problems with dates as well.
The delete interaction removes an existing resource. The interaction is performed by an HTTP DELETE operation as shown:
DELETE [baseurl]/[resourcetype]/{@id} (.ext)
Servers may refuse to delete a resource depending on the resource type and/or contents, and on audit requirements. If a server refuses to delete resources of that type on principle, then it should return the status code 405 method not allowed. If the server refuses to delete a resource because of reasons specific to that resource, such as referential integrity, it should return the status code 412 Expectation Failed.
The validate interaction checks whether the attached content would be acceptable as an update to an existing resource. The interaction is performed by an HTTP POST operation as shown:
POST [baseurl]/[resourcetype]/validate
POST [baseurl]/[resourcetype]/validate/{@id}
In the first case, the content is checked against the general specification and against the conformance profile that applies to the application. In the second case, the validation occurs as if the resource were submitted as an update, and additional instance specific things such as referential integrity and update rules are applied as well. The return content has status 200 OK if the content validates ok, or 412 Precondition Failed, with the following content:
<validation xmlns="http://www.hl7.org/fhir"> <error mand type="string">General error message</errror> <messages type="list"> <!-- Zero+ --> <message> <path opt type="string"xpath to the issue</path> <error mand type="string">Description of the problem</error> </message> <messages> </validation>
The history interaction retrieves the history of the resource. The interaction is performed by an HTTP Get operation as shown:
GET [baseurl]/[resourcetype]/{@id} (.ext)?view=history
The return content is an Atom feed aggregration (§2.2) containing the version history for that resource, sorted with oldest versions first.
This interaction searches the resource type based on some filter criteria. The interaction is performed by an HTTP Get operation as shown:
GET [baseurl]/[resourcetype]/search (.ext)
Because of the way that some user agents treat POST requests, POST submissions are also allowed, though the semantics are exactly the same as a GET operation. Search operations take a series of parameters that are encoded in the URL or as an x-multi-part-form submission for a POST. Each resource type defines the applicable search parameters, and servers may declare additional parameters in their conformance statements. In addition, the following common search parameters apply to all resource types:
| n | Starting offset of the first record to return in the search set |
| count | Number of return records requested. The server is not bound to conform. |
The search results may be divided into a number of pages using offsets. It is at the discretion of the server how many results to return, though the client may request a particular number of a count parameter. If the client wishes for more results, it should use the n parameter. More generally, the client uses parameters to narrow the search and increase it's usefulness. Note that which parameters to support is at the discretion of the server.
The return content is an Atom feed aggregration (§2.2) containing the results of the search in a defined order. This specification does not assign any particular meaning to the order of the resources.
The create interaction creates a new resource. The interaction is performed by an HTTP POST operation as shown:
POST [baseurl]/[resourcetype] (.ext)
The server returns a a copy of the newly created resource (which may not be the same as that submitted) with the acknowledgement, along with a Location: header which also contains the id of the created resource:
Location: [baseurl]/[resourcetype]/{new-id} (.ext)
The client may submit the content with or without an id included. If the submitted resource contains an id, the server must either honor the requested id, or return a 409 Conflict if a resource already exists by that id, or a 403 Forbidden if it will not honor client defined ids at all
The updates interaction retrieves a list of changes to the resource type. The interaction is performed by an HTTP Get operation as shown:
GET [baseurl]/[resourcetype]/updates (.ext)
The return content is an Atom feed aggregration (§2.2) containing the update history for that resource type, sorted with oldest updates first.
The client can use parameters to filter the update list. The following table summarises ths search parameters:
| since | The time from which to return new updates |
| from | A version Id (e-tag value) from which to return updates |
The transaction interaction provides support for specific transactions defined against the resource by this specification. The transaction interaction is supported on both individual resources and the type:
POST [baseurl]/[resourcetype]/transaction/[name](.ext)
POST [baseurl]/[resourcetype]/transaction/{@id}/[name](.ext)
The name of the transaction, along with the content model of the request and response will be specified against each resource when the possible transactions are defined throughout this specification.
The conformance interaction retrieves the application's conformance statement for the resource. The interaction is performed by an HTTP Get operation as shown:
GET [baseurl]/[resourcetype]/conformance (.ext)
For the return content, see the Conformance Resource (§2.4). If a 404 Unknown is returned, the resource is not supported, and no other interactions are implemented.
The schema interaction retrieves a w3c schema for the resource. The interaction is performed by an HTTP Get operation as shown:
GET [baseurl]/[resourcetype]/schema.xsd
The return content is a W3C schema that describes the resource. The schema does not have to be the one defined with this specification; it can eliminate elements not supported by the server, and explicitly define extensions supported by the server. However the xml format it describes must be consistent with the rules defined in this specification.
The HTTP protocol may be routed through an HTTP proxy such as squid. Such proxies are transparent to the applications, though implementors should be alert to the effects of rogue caching.
Interface engines may also be placed between the consumer and the provider; these differ from proxies because they actively change the content and/or destination of the HTTP exchange. Such agents are allowed, but are bound to the conform to this specification. In order to assist with troubleshooting, any agent that modifies an HTTP request or Response content must add a stamp to the HTTP headers like this:
request-modified-[identity]: [purpose] response-modified-[identity]: [purpose]
The identity must a single token defined by the administrator of the agent that will sufficiently identify the agent in the context of use. The header must specify the agents purpose in modifying the content. End point systems must not use this header for any purpose; it's aim is to assist with system troubleshooting.
A conformance statement returned by request in an RESTful framework.
The relative url is /conformances
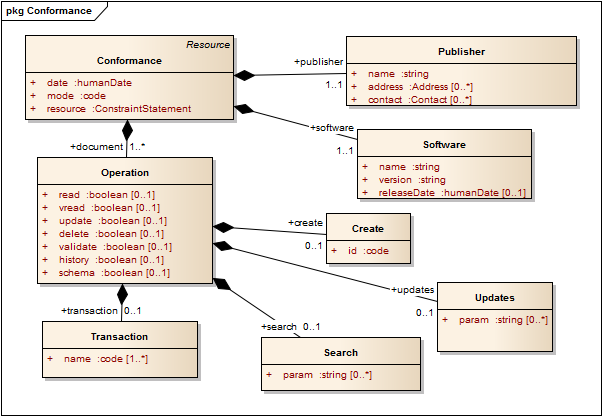
<Conformance xmlns="http://www.hl7.org/fhir"> <id> mand id ConformanceStatement Id (UUID)</id> <date> mand dateTime Publication Date</date> <publisher> mand <name> mand string Publishing Organization</name> <address> opt Zero+ Address Address of Organization</address> <contact> opt Zero+ Contact Contacts for Organization</contact> </publisher> <software> mand <name> mand string Name software is known by</name> <version> mand string Version covered by this statement</version> <releaseDate> opt dateTime Date this version released</releaseDate> </software> <mode> mand code client | server</mode> <profile> opt Zero+ uri other profiles that apply (i.e. code binding rules)</profile> <resource> mand Constraint Resource Type with constraints</resource> <operation> cond <read> opt boolean if supported</read> <vread> opt boolean if supported</vread> <update> opt boolean if supported</update> <delete> opt boolean if supported</delete> <validate> opt boolean if supported</validate> <history> opt boolean if supported</history> <transaction> opt <!-- only if supported --> <name> mand One+ code transaction names supported</name> </transaction> <search> opt <!-- only if supported --> <param> mand One+ string search params supported</param> </search> <create> opt <!-- if supported --> <id> mand code source of id: client | server | either</id> </create> <updates> opt boolean <!-- if supported --> <param> mand Zero+ string update filter params supported</param> </updates> <schema> opt boolean if supported</schema> </operation> <extensions> opt See Extensions See Extensions </extensions> <text> mand Narrative Text summary of conformance profile for human interpretation</text> </Conformance>
Schema for Conformance and an example (or formatted for browser (§2.4))
Terminology Bindings
| client | The application acts as a server for this resource | |
| server | The application acts as a client for this resource | |
| client | The client must provide a unique resource id | |
| server | The server defines the id and will reject any client attempt to define it | |
| either | The client can provide a unique resource id, or the server will define it instead | |
Notes:
The formal definitions for the elements above.
This page describes how FHIR Resources can be used in a traditional messaging context, much like HL7 v2. Applications claiming conformance to this framework claim to be conformant to "FHIR messaging".
In FHIR messaging, a "request message" is sent from a source application to a destination application when an event happens. Events mostly correspond to things that happen in the real world. The request application consists of an aggregation (§2.2) of resources, with the first resource in the aggregation being a Message (§2.6) resource that identifies the nature of the request message and carries additional request metadata. The other resources in the aggregation depend on the request. The events supported in FHIR, along with the resources included in them, are defined below. The destination application processes the request, and returns one or more response messages which are also an aggregation (§2.2) of resources, with the first resource in the aggregation being a Message (§2.6) resource with a response section that reports the outcome of the transaction and any additional response resources required.
This specification assumes that content will be delivered from one application to another by some delivery mechanism, and then a response will be returned to the source application. The exact mechanism of transfer is irrelevant to this specification, but may include file transfer, http based transfer, LLP (HL7 minimal lower layer protocol), MQ series messaging, or anything else. The only requirement for the transfer layer is that requests are sent to a known location, and responses are returned to the source of the request. This specification considers the source and destination applications as logical entites, and the mapping from logical source and destination to implementation specific addresses is outside the scope of this specification.
In principle, source applications are not required to wait for a response to a transaction before issuing a new transaction. However in some case, the transactions in a given stream are dependent on each other, and must be sent in order. In addition, some transfer options may require sequential delivery of messages.
This specification ignores the existence of interface engines and message transfer agents that lie between the source and destination. Either they are transparent to the message/transaction content, and irrelevant to this specification, or they are actively involved in manipulating the message content. If these middleware agents are modifying the message content, then they become responsible for honoring the contract described below in both directions.
Some of the message delivery mechanisms mentioned above are reliable delivery systems - the message is always delivered, or an appropriate error is returned to the source. However in most implementations, reliable messaging cannot be assumed, and either the request or the response can get lost in transit. FHIR messaging describes a simple approach to handle this that applications must conform to, whether messaging appears to be reliable or not.
A message receiver must always check the incoming aggregation package ids, and check them against a store of previously received messages (going back a reasonable period in time). If it receives a duplicate message id that it has already responded to, it should assume that it's original response was lost, and resend the original response in a new aggregation package with Message.response.duplicate set to true. If the source application gets no response to it's request from the destination application, the source application should resend the same aggregation with the same aggregation package id.
A message is just an aggregation (§2.2) built using the Atom feed format. The first resource of a message is a Message (§2.6) resource. This resource identifies the message event and links to the additional focal resource associated with the message, if any. The list of additional resources which must be included in a given message is provided below. Other resources that are identified in the message resource or included resources may either be left as references that are located/resolved outside the scope of the aggregation, or they may also be included in the aggregation.
| Code | Description | Request | Response | Notes |
|---|---|---|---|---|
| admin-notify | Notification of a change to an administrative resource (either create or update). Note that there is no delete, though some administrative resources have status or period elements for this use | Person | -- | |
| Animal | -- | |||
| Organization | -- | |||
| Patient | -- | Patient Links cannot be updated using admin-notify. The links element must be empty | ||
| labreport-provide | Provide a lab report, or update a previously provided lab report | LabReport LabReport.patient LabReport.patient.person LabReport.patient.animal LabReport.admission LabReport.requestDetail.clinicalInfo LabReport.specimen LabReport.resultGroup.specimen | -- | |
| patient-link | Notification that two patient records actually identify the same patient | Patient,Patient | -- | Follow ups: patient-unlink? |
| patient-unlink | Notification that previous advice that two patient records concern the same patient is now considered incorrect | Patient,Patient | -- |
Applications claiming to be conformant to "FHIR messaging" may choose to publish a conformance statement that lists all the message events they support, either as sender or listener, and for each event, which resources are aggregated (sender), or are required to be aggregated (listener), and the conformance statements for the information content of the individual resources. The conformance statement is a resource with the name "MessageConformance" (§2.7).
A message that contains FHIR resources.
The relative url is /messages

<Message xmlns="http://www.hl7.org/fhir"> <id> mand id Master Resource Id = Message Id</id> <threadId> opt id Id of thread of conversation</threadId> <instant> mand instant Instant the message was sent</instant> <event> mand code Code for the event his message represents</event> <response> opt <!-- If this is a response --> <id> mand id Id of original message</id> <code> mand code Type of response to the message</code> <duplicate> mand boolean if this is not the first response</duplicate> </response> <source> mand (Device) Message Source Application</source> <destination> mand (Device) Message Destination Application</destination> <enterer> opt (Person|Device) The source of the data entry</enterer> <author> opt (Person|Device) The source of the decision</author> <responsible> opt (Person|Organization) final responsibility for event</responsible> <effective> opt Interval(dateTime) time of effect</effective> <reason> opt CodeableConcept Cause of event</reason> <data> cond (Any) The actual content of the message</data> <extensions> opt See Extensions See Extensions </extensions> <text> mand Narrative Text summary of message, for human interpretation</text> </Message>
Schema for Message and an example (or formatted for browser (§2.6))
Terminology Bindings
| ok | The message was accepted and processed without error | |
| error | Some internal unexpected error occured - wait and try again. Note - this is usually used for things like database unavailable, which may be expected to resolve, though human intervention may be required | |
| rejection | The message was rejected because of some content in it. There is no point in re-sending without change. The response narrative must describe what the issue is | |
| rules | The message was rejected because of some event-specific business rules, and it may be possible to modify the request and re-submit (as a different request). The response data must clarify what the change would be, as described by the event definition | |
| undeliverable | A middleware agent was unable to deliver the message to it's supposed destination | |
Notes:
The formal definitions for the elements above.
A conformance statement about how an application uses FHIR messaging.
The relative url is /messageconformances
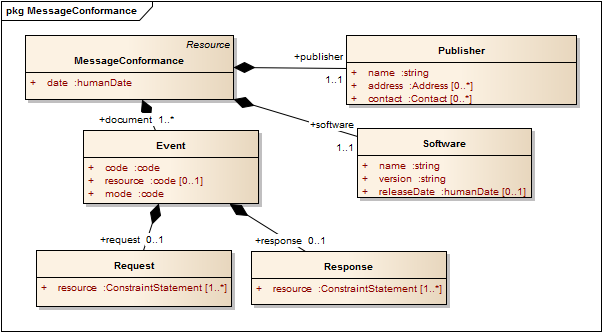
<MessageConformance xmlns="http://www.hl7.org/fhir"> <id> mand id ConformanceStatement Id (UUID)</id> <date> mand dateTime Publication Date</date> <publisher> mand <name> mand string Publishing Organization</name> <address> opt Zero+ Address Address of Organization</address> <contact> opt Zero+ Contact Contacts for Organization</contact> </publisher> <software> mand <name> mand string Name software is known by</name> <version> mand string Version covered by this statement</version> <releaseDate> opt dateTime Date this version released</releaseDate> </software> <profile> opt Zero+ uri other profiles that apply (i.e. code binding rules)</profile> <event> mand <!-- One+ --> <code> mand code Declare support for this event</code> <resource> cond code Which resource if event has multiple</resource> <mode> mand code Sender | Receiver</mode> <request> opt <resource> mand One+ Constraint Constraint on a resource used in request</resource> </request> <response> opt <resource> mand One+ Constraint Constraint on a resource used in response</resource> </response> </event> <extensions> opt See Extensions See Extensions </extensions> <text> mand Narrative Text summary of conformance statement for human interpretation</text> </MessageConformance>
Schema for MessageConformance and an example (or formatted for browser (§2.7))
Terminology Bindings
| sender | The application sends requests and receives responses | |
| receiver | The application receives requests and sends responses | |
Notes:
The formal definitions for the elements above.
This page describes how FHIR Resources can be used to build clinical documents, like CDA. Applications claiming conformance to this framework claim to be conformant to "FHIR documents".
Documents are a collections of resources that a fixed in scope and frozen in time, and authored and/or attested by a collection or humans, orgnisations and devices, and gathered together into a single aggregation using an atom feed (§2.2). Documents built in this fashion may be exchanged between systems, and also persisted in document storage and management systems, including systems such as IHE XDS.
All documents have the same structure: an aggregation that has Document Resource (§3.6) first, followed by a series of other resources referenced from the Document resource.
The document resource identifies the document and it's purpose, sets the context of the document, and carries key information such as the subject and author, and divides the document up into sections that each contain a content resource, which is some other resource identified in this specification. Any resource referenced directly in the Document resource must be included in the aggregation when the document is assembled; other resources that these documents refer to may also be aggregated if the document originator chooses to.
Document profiles and/or application conformance statements can make additional rules about which resources must be aggregated along with the resources that are directly referenced in the Document resource. In addition, Document Profiles and conformance statements can specify what sections a document contains, and what the constraints on their content resource are.
Since documents are attested at a fixed point in time with known contents, any handling of documents must ensure that the content has not changed at all. Applications are allowed to extract content from the document and use it in other contexts, but it is no longer part of the document. When storing documents, applications may store the entire document as a single byte stream, which would ensure that it can be reproduced exactly, or they can disassemble the document into component resources (or another disassembly strategy), as long as the original document can be assembled in it's original form if the original document is required. Applications are not mandated to store all documents, though most actual usages will require the document to persist.
The standard RESTful framework, there is an manager for the Document resource (§3.6) which uses the standard HTTP Transactions (§2.3) applied to Document resources. In this fashion, a RESTful framework can be used to build a logical description of a document by updating the appropriate resources. Note that although this can form a logically complete description of the document a full document only exists once the resources that are part of the document are built into a single aggregation.
Note that the standard /document end point defined with the Document resource handles individual Document resources, not full documents that are aggregations. Using this resource directly is mostly confined to the process of constructing a document using the RESTful framework. The RESTful end point for full aggregated documents is /aggregations (§2.2.3)
Applications that handle and process documents are not required to make the individual constituent resources that are part of a document available through the their resource specific URL, though they may choose to do so.
Issues: images & attachments
Applications claiming to be conformant to "FHIR documents" may choose to publish a conformance statement that lists all the document types they support, and for each type, what the document and section content is, and which resources are aggregated (originator), or are required to be aggregated (recipient), along with constraint statements for the information content of the individual resources. The conformance statement is a resource with the name "DocumentConformance" (§2.9).
The same structure can be used to declare a document profile. Such profiles may be defined and published by HL7, other standards organisations, institutions, and projects.
A conformance statement about how one or more FHIR documents.
The relative url is /documentconformances
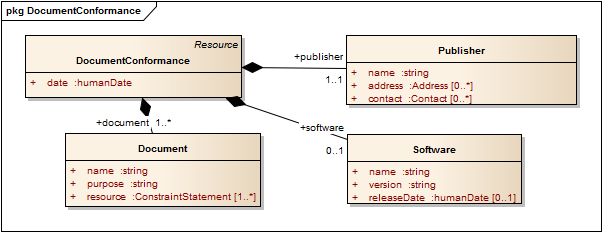
<DocumentConformance xmlns="http://www.hl7.org/fhir"> <id> mand id ConformanceStatement Id (UUID)</id> <date> mand dateTime Publication Date</date> <publisher> mand <name> mand string Publishing Organization</name> <address> opt Zero+ Address Address of Organization</address> <contact> opt Zero+ Contact Contacts for Organization</contact> </publisher> <software> opt <!-- If this is for an application --> <name> mand string Name software is known by</name> <version> mand string Version covered by this statement</version> <releaseDate> opt dateTime Date this version released</releaseDate> </software> <profile> opt Zero+ uri other profiles that apply (i.e. code binding rules)</profile> <document> mand <!-- One+ document definition --> <name> mand string Name for this particular document profile</name> <purpose> opt string Human description of this particular profile</purpose> <resource> mand One+ Constraint Constraint on a resource used in the document</resource> </document> <extensions> opt See Extensions See Extensions </extensions> <text> mand Narrative Text summary of conformance profile for human interpretation</text> </DocumentConformance>
Schema for DocumentConformance and an example (or formatted for browser (§2.9))
Notes:
The formal definitions for the elements above.
To do.
content profile for hData for each resource template for a content profile - available @ hdata wiki page on hl7 wiki (ArB is going to review that) schema + rddl (see rddl.org) set link rel in atom feed on per typeA Resource Profile - a statement of constraint on one or more Resources and/or Concept Domains.
The relative url is /profiles
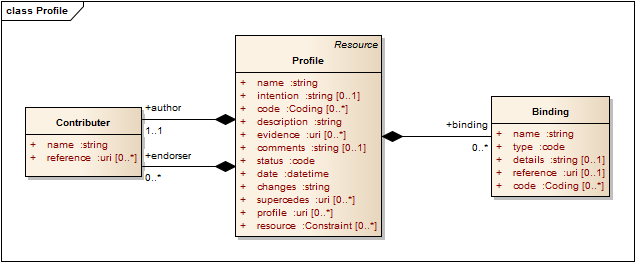
<Profile xmlns="http://www.hl7.org/fhir"> <id> mand id fixed identifier for this profile (UUID)</id> <name> mand string Informal name for this profile</name> <author> mand <!-- (Organisation or individual) --> <name> mand string Name of the recognised author</name> <reference> opt Zero+ uri Web reference to the author</reference> </author> <intention> opt string Why this profile was written</intention> <code> opt Zero+ Coding assist with indexing and finding</code> <description> mand string natural language description of the Template</description> <evidence> opt Zero+ uri Supporting evidence for the design</evidence> <comments> opt string Guidance for use, usage notes, etc</comments> <status> mand code draft | testing | production | withdrawn | superceded</status> <date> mand dateTime date for given status</date> <endorser> opt <!-- Zero+ (Organisation or individual) --> <name> mand string Name of the recognised endorser</name> <reference> opt uri Web reference to the endorser</reference> </endorser> <changes> cond string notes about changes since last version</changes> <supercedes> opt Zero+ uri references to previous versions</supercedes> <profile> opt Zero+ uri other profiles that apply (i.e. code binding rules)</profile> <resource> mand Zero+ Constraint Resource Type with constraints</resource> <binding> mand <!-- Zero+ --> <name> mand string concept domain name</name> <type> mand code binding type</type> <details> cond string extra details - see notes</details> <reference> cond uri source of binding content</reference> <code> cond Zero+ Coding enumerated codes that are the binding</code> </binding> <extensions> opt See Extensions See Extensions </extensions> <text> mand Narrative Text summary of resource profile for human interpretation</text> </Profile>
Schema for Profile and an example (or formatted for browser (§2.11))
Terminology Bindings
| draft | This profile is still under development | |
| testing | this profile was authored for testing purposes (or education/evaluation/evangelisation) | |
| production | This profile is ready for use in production systems | |
| withdrawn | This profile has been withdrawn | |
| superceded | This profile was superceded by a more recent version | |
| Unbound | The concept domain is not bound to anything | |
| CodeList | The concept domain is bound to a list of supplied codes - only those codes are allowed | |
| Reference | The concept domain references some external definition by a provided reference | |
| Preferred | The concept domain references a set of preferred terms | |
| Suggestion | This profile was superceded by a more recent version | |
| External | The concept domain is defined by an external authority identified in the reference | |
Notes:
The following simple search/filter parameters are defined for Resource Profiles:
| name | a portion of the name of the resource |
| author | name or id of the author |
| code | a code in the format uri::code |
| status | a status of the profile |
| type | type of resource that is constrained in the profile |
| domain | concept domain that is constrained in the resource |
The standard search parameters also apply (see Searching (§2.3.12)).
The formal definitions for the elements above.
A person who is involved in the healthcare process.
The relative url is /people
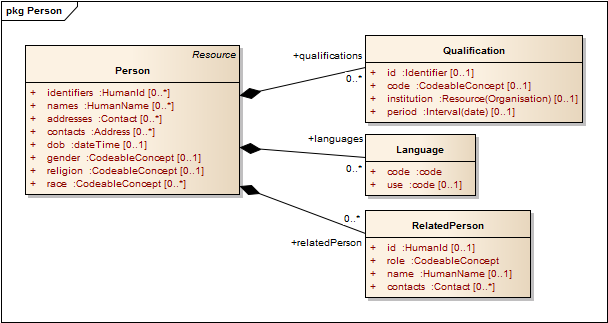
<Person xmlns="http://www.hl7.org/fhir"> <id> mand id Master Resource Id, always first in all resources</id> <identifier> Zero+ HumanId A Human identifier for this person</identifier> <name> Zero+ HumanName A name associated with the person</name> <address> Zero+ Address An address for the person</address> <contact> Zero+ Contact A contact detail for the person</contact> <dob> opt dateTime The birth date for the person</dob> <gender> opt CodeableConcept Administrative Gender</gender> <religion> opt CodeableConcept Religion of the person</religion> <race> opt Zero+ CodeableConcept The race of a person</race> <qualification> <!-- Zero+ Qualifications, Accreditations, Certifications --> <id> opt Identifier Identifier for the qualification</id> <code> opt CodeableConcept A code for the qualification</code> <institution> opt (Organization) Who conferred it</institution> <period> opt Interval(date) When the qualification is valid</period> </qualification> <language> <!-- Zero+ --> <code> mand code ISO 639-3 code for language</code> <use> opt code How well the language is used</use> </language> <relatedPerson> <!-- Zero+ Kin, Guardians, Agents, Caregivers --> <id> opt HumanId Identifier for the person</id> <role> mand CodeableConcept Type of relationship</role> <name> opt HumanName Name of the person</name> <contact> Zero+ Contact Contact details for the person</contact> </relatedPerson> <extensions> opt See Extensions See Extensions </extensions> <text> mand Narrative Text summary of person, for human interpretation</text> </Person>
Schema for Person and an example (or formatted for browser (§3.1))
Terminology Bindings
| none | The person does not speak the language at all | |
| poor | The person has minimal functional capability in the language | |
| useable | The person can use the language, but may not be full conversant, particularly with regards to health concepts | |
| fluent | The person is fully capable of using the language | |
Notes:
The following simple search/filter parameters are defined for person:
| name | a portion of name in any name part |
| phonetic | a portion of name using some kind of phonetic matching algorithm |
| id | search id in any identifiers |
| contact | the value in any kind of contact |
| address | an address in any kind of address/part |
| gender | gender of the person |
The standard search parameters also apply (see Searching (§2.3.12)).
The formal definitions for the elements above.
An animal that has relevance to the care process -usually this is for animals that are patients..
The relative url is /animals
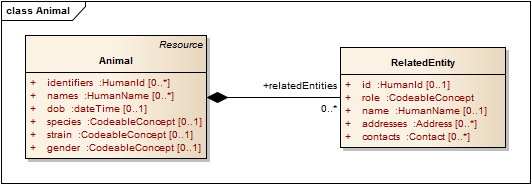
<Animal xmlns="http://www.hl7.org/fhir"> <id> mand id Master Resource Id, always first in all resources</id> <identifier> Zero+ HumanId Human identifiers for this animal</identifier> <name> Zero+ HumanName A name associated with the animal</name> <dob> opt dateTime The birth date for the animal</dob> <species> opt CodeableConcept Species for the Animal</species> <strain> opt CodeableConcept Strain for the Animal</strain> <gender> opt CodeableConcept Gender for the Animal</gender> <relatedEntity> <!-- Zero+ Kin, owner, care giver etc --> <id> opt HumanId Identifier for the entity</id> <role> mand CodeableConcept Type of relationship</role> <name> opt HumanName Name of the related entity</name> <address> Zero+ Address An address (usually human, but may be kin)</address> <contact> Zero+ Contact Contact details (usually for humans)</contact> </relatedEntity> <extensions> opt See Extensions See Extensions </extensions> <text> mand Narrative Text summary of animal, fall back for human interpretation</text> </Animal>
Schema for Animal and an example (or formatted for browser (§3.2))
Terminology Bindings
Notes:
The following simple search/filter parameters are defined for person:
| name | a portion of name in any name part |
| species | the species, including by subsumption if the coding supports this |
| phonetic | a portion of name using some kind of phonetic matching algorithm |
| id | search id in any identifiers |
The standard search parameters also apply (see Searching (§2.3.12)).
The formal definitions for the elements above.
For any organization/institution/government department that has relevance to the care process.
The relative url is /organizations
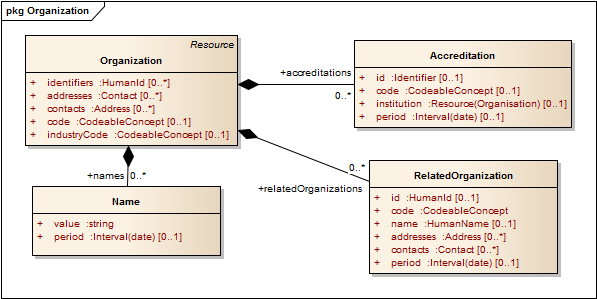
<Organization xmlns="http://www.hl7.org/fhir"> <id> mand id Master Resource Id, always first in all resources</id> <identifier> Zero+ HumanId Identifier for this organization</identifier> <name> <!-- Zero+ --> <value> mand string A name associated with the organization</value> <period> opt Interval(date) When this name is/was in use</period> </name> <address> Zero+ Address An address for the organization</address> <contact> Zero+ Contact A contact detail for the organization</contact> <code> opt CodeableConcept kind of organisation</code> <industryCode> opt CodeableConcept kind of industry</industryCode> <accreditation> <!-- Zero+ --> <id> opt Identifier Identifier for the accreditation</id> <code> opt CodeableConcept What kind of accreditation</code> <institution> opt (Organization) Who conferred it</institution> <period> opt Interval(date) When the accreditation is valid</period> </accreditation> <relatedOrganization> <!-- Zero+ sub-, super-, and partner organisations --> <id> opt HumanId Identifier for the organization</id> <code> mand CodeableConcept How the organizations are related</code> <name> opt string Name of the organization</name> <address> Zero+ Address An address for the organization</address> <contact> Zero+ Contact General contact details for the organization</contact> <period> opt Interval(date) When the organizations were related</period> </relatedOrganization> <extensions> opt See Extensions See Extensions </extensions> <text> Narrative Text summary of organization, fall back for human interpretation</text> </Organization>
Schema for Organization and an example (or formatted for browser (§3.3))
Terminology Bindings
Notes:
The following simple search/filter parameters are defined for organization:
| name | a portion of name in any name part |
| phonetic | a portion of name using some kind of phonetic matching algorithm |
| id | search id in any identifiers |
The standard search parameters also apply (see Searching (§2.3.12)).
The formal definitions for the elements above.
A person who represents an organisation, and is authorised to perform actions on it's behalf.
The relative url is /agents

<Agent xmlns="http://www.hl7.org/fhir"> <id> mand id Master Resource Id, always first in all resources</id> <person> mand (Person) The person who is the agent</person> <organization> mand (Organization) The represented organization</organization> <role> mand One+ CodeableConcept A role the agent has</role> <period> opt Interval(date) The period for which this agency applies</period> <identifier> Zero+ HumanId A Human identifier for the person as this agent</identifier> <address> Zero+ Address An address that applies for the person as this agent</address> <contact> Zero+ Contact A contact that applies for the person as this agent</contact> <extensions> opt See Extensions See Extensions </extensions> <text> mand Narrative Text summary of the agent, for human interpretation</text> </Agent>
Schema for Agent and an example (or formatted for browser (§3.4))
Terminology Bindings
Notes:
The following simple search/filter parameters are defined for person:
| person | The identity of a person |
| organization | The identity of an organization |
| id | search id in any agent identifiers |
The standard search parameters also apply (see Searching (§2.3.12)).
The formal definitions for the elements above.
A patient is a person or animal that is receiving care.
The relative url is /patients

<Patient xmlns="http://www.hl7.org/fhir"> <id> mand id Master Resource Id, always first in all resources</id> <link> mand Zero+ (Patient) Other patients linked to this resource</link> <active> mand boolean Whether this patient record is active (in use)</active> <person> cond (Person) The person who is the patient</person> <animal> cond (Animal) The animal which is the patient</animal> <provider> mand (Organization) Organization managing the patient</provider> <identifier> Zero+ HumanId An identifier for the person as this patient</identifier> <diet> opt CodeableConcept Dietary restrictions for the patient</diet> <confidentiality> opt CodeableConcept Confidentiality of the patient records</confidentiality> <recordLocation> opt CodeableConcept Where the paper record is</recordLocation> <extensions> opt See Extensions See Extensions </extensions> <text> mand Narrative Text summary of person, for human interpretation</text> </Patient>
Schema for Patient and an example (or formatted for browser (§3.5))
Terminology Bindings
Notes:
Managing Patient registration is a well known difficult problem. Around 2% of registrations are in error, mostly duplicate records. Sometimes the duplicate record is caught fairly quickly and retired before much data is accumulated. In other cases, substantial amounts of data may accumulate. For these and other reasons, the identifiers associated with a patient may change over time.
The master identifier for the Patient Resource can never change. For this reason the identifiers with which humans are concerned (often called MRN - Medical Record Number, or UR - Unit Record) should not be used as the master identifier. Instead they should be represented in the Patient.identifier list where they can be managed. This is also useful for the case of institutions that have acquired multiple numbers because of mergers of patient record systems over time.
In this specification, patient records are never merged. If multiple patient records are found to be duplicates, they are linked. In a RESTful context, this is done using the "link patients" transaction described below. In other contexts, equivalent functionality will be needed. When patient resources are linked, one may be chosen as the "master" - the correct record. In this case, the active status of all the other resources is set to false, and all the content is moved to the active record by updating it directly.
Patient records may only be in one of two statuses: active and retired. A normal record is active - it is in use. The status retired is used when a record is created in error. Once the error is discovered, it can either be retired or deleted. A record does not need to be linked to be retired.
The patient resource type defines one special transaction provided by the patient manager: "Link" for linking resources. The reason is that linking records is effectively a transaction that involves at least two resources, and all or none must change. Since the transaction involves multiple resources, it is implemented on the resource manager as a POST to [todo]
There is no content model for the response, except for an HTTP status code.
The following simple search/filter parameters are defined for person:
| person | The identity of a person |
| provider | The identity of an organization |
| id | search id in any patient identifiers |
The standard search parameters also apply (see Searching (§2.3.12)).
The formal definitions for the elements above.
A documentation of clinical observations and services that are aggregated together into a single statement of clinical meaning that establishes it's own context. A clinical document is composed of a set of resources that include both human and computer readable portions. A human must attest to the accuracy of the human readable portion, and may authenticate and/or sign the entire whole.
The relative url is /documents
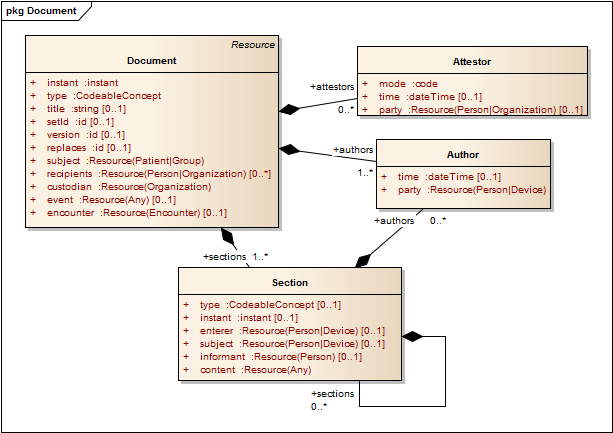
<Document xmlns="http://www.hl7.org/fhir"> <id> mand id Master Resource Id = document Id</id> <instant> mand instant Document Creation Time</instant> <type> mand CodeableConcept Document Type (LOINC if possible)</type> <title> opt string Document Title</title> <setId> cond id Id fixed across all document revisions</setId> <version> opt integer used to version successive replacement documents</version> <replaces> cond id If this document replaces another</replaces> <subject> mand (Patient|Group) who the document is about</subject> <author> mand <!-- One+ Author (contributed content to document) --> <time> opt dateTime When authoring happened</time> <party> mand (Person|Device) who/what authored the final document</party> </author> <attestor> opt <!-- Zero+ attests to accuracy of document --> <mode> mand code personal | professional | legal | official</mode> <time> opt dateTime When document attested</time> <party> opt (Person|Organisation) who attested the document</party> </attestor> <recipient> opt Zero+ (Person|Organization) expected to receive a copy </recipient> <custodian> mand (Organization) org which maintains the document.</custodian> <event> opt (Any) the clinical item being documented</event> <encounter> opt (Admission|InterestOfCare) context of the document</encounter> <section> mand <!-- One+ Document is broken into sections --> <type> opt CodeableConcept type of section (recommended)</type> <instant> opt instant Section Creation Time</instant> <author> opt <!-- if section author different to document --> <time> opt dateTime When authoring happened</time> <party> mand (Person|Device) who/what authored the section</party> </author> <enterer> opt (Person|Device) The source of the data entry</enterer> <subject> opt (Person|Group) if section different to document</subject> <informant> opt (Person) provided information in section</informant> <content> cond (Any) the actual content of the section</content> <section> cond <!-- Zero+ nested Section --> <!-- Content as for Document.Section --> </section> </section> <extensions> opt See Extensions See Extensions </extensions> <text> mand Narrative Text summary of message, for human interpretation</text> </Document>
Schema for Document and an example (or formatted for browser (§3.6))
Terminology Bindings
| personal | The person authenticated the document in their personal capacity | |
| professional | The person authenticated the document in their professional capacity | |
| legal | The person authenticated the document and accepted legal responsibility for it's content | |
| official | The organization authenticated the document as consistent with their policies and procedures | |
Notes:
The human display of the Document is the collated narrative portions of following resources (in order):
The document narrative should summarise the important parts of the document header that are required to establish clinical context for the document (other than the subject, which is displayed in it's own right). To actually build the combined narrative, simply append all the narratives xhtml fragments. The viewer program can provide it's own stylesheet (.css) for the combined html of the narrative, but cannot change any styles specified internally in the existing narratives.
A document originator is an application that creates a document resource. The originator may create new content resources or assemble already existing content resources while doing so. A document originator has the following responsibilities:
A document recipient is an application that receives documents from a document originator or document management system. The document recipient is responsible for ensuring that received CDA documents are processed and/or rendered in accordance to this specification. A document recipient has the following responsibilities:
The formal definitions for the elements above.
The findings and interpretation of pathology tests performed on tissues and body fluids. This is typically done in a laboratory but may be done in other environments such as at the point of care.
The relative url is /labreports
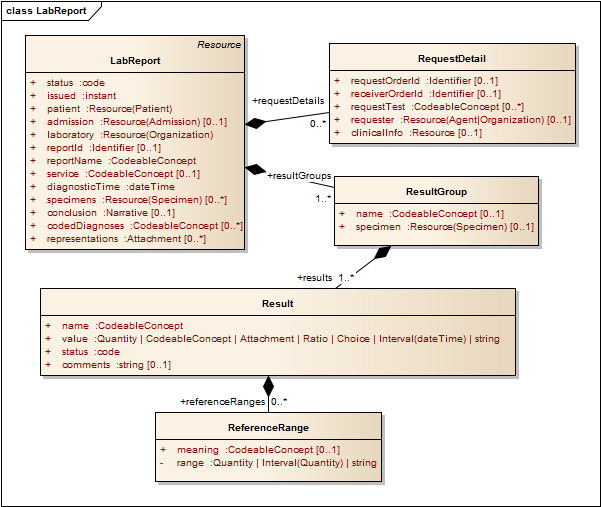
<LabReport xmlns="http://www.hl7.org/fhir"> <id> mand id Master Resource Id, always first in all resources</id> <status> mand code Registered|Interim|Final|Amended|Cancelled|Withdrawn</status> <issued> mand instant date issed for current status</issued> <patient> mand (Patient) The patient the report is about</patient> <admission> opt (Admission) Admission Context</admission> <laboratory> mand (Organization) Responsible Laboratory</laboratory> <reportId> opt id Id for external references to this report</reportId> <requestDetail> <!-- Zero+ --> <requestOrderId> opt Identifier Id assigned by requester</requestOrderId> <receiverOrderId> opt Identifier Receiver's Id for the request</receiverOrderId> <requestTest> Zero+ CodeableConcept Test Requested</requestTest> <requester> opt (Agent|Organization) Responsible for request</requester> <clinicalInfo> opt (Any) Clinical information provided</clinicalInfo> </requestDetail> <reportName> mand CodeableConcept Name for the entire report</reportName> <service> opt CodeableConcept Biochemistry, Haematology etc</service> <diagnosticTime> mand dateTime Effective time of diagnostic report</diagnosticTime> <specimen> Zero+ (Specimen) Specimen (incl. time of collection)</specimen> <resultGroup> <!-- One+ --> <name> opt CodeableConcept What defines the group</name> <specimen> opt (Specimen) Specimen details</specimen> <result> <!-- One+ --> <name> opt CodeableConcept Name or code of the result</name> <value[x]> opt Quantity|CodeableConcept|Attachment| Ratio|Choice|Interval(dateTime)|string Result. [x] = type name</value[x]> <flag> opt code + | ++ | +++ | - | -- | --- </flag> <status> mand code Registered|Interim|Final|Amended|Cancelled|Withdrawn</status> <comments> opt string Comments about result</comments> <referenceRange> <!-- Zero+ --> <meaning> opt CodeableConcept The meaning of this range</meaning> <range[x]> mand Quantity|Interval(Quantity)|string Reference</range[x]> </referenceRange> </result> </resultGroup> <conclusion> opt Narrative Clinical Interpretation of test results</conclusion> <codedDiagnosis> Zero+ CodeableConcept Codes for the conclusion</codedDiagnosis> <representation> One+ Attachment Entire Report as issued</representation> <extensions> opt See Extensions See Extensions </extensions> <text> mand Narrative Text summary of report, for human interpretation</text> </LabReport>
Schema for LabReport and an example (or formatted for browser (§4.1))
Terminology Bindings
| registered | The existence of the result is registered, but there is no result yet available | |
| interim | This is an initial or interim result: data may be missing or verification not been performed | |
| final | The result is complete and verified by the responsible pathologist | |
| amended | The result has been modified subsequent to being Final, and is complete and verified by the responsible pathologist | |
| cancelled | The result is unavailable because the test was not started or not completed (also sometimes called aborted) | |
| withdrawn | The result has been withdrawn following previous Final release | |
| - | ||
| -- | ||
| --- | ||
| + | ||
| ++ | ||
| +++ |
Notes:
One difficult aspect of the design of this resource can be captured with a simple question: “just what is a result?� There is a wide range of variation in the answers to this question; some respond that a result is inherently measurement based, while others focus on the clinical utility of the data item.
Some practical examples:
Which of these are results? For this resource, we have chosen to take an inclusive view; any of these things can be a result, as long as they have a formal code or name that has a clinical meaning, and some kind of (possible) value then they can be a result.
The following simple search/filter parameters are defined for person:
| id | an identifier associated with the report |
| test | the name or code of either a requested test, the report or a report group |
| result | the name or code or result value of a result |
| specimen | Either of the specimens. The parameter is then followed by an additional parameter (separated for a ".") that species search/filter inside specimen |
| patient | The identity of a patient |
| laboratory | The identity of an laboratory |
The standard search parameters also apply (see Searching (§2.3.12)).
The formal definitions for the elements above.
Directions provided by a prescribing practitioner for a specific medication to be administered to an individual.
The relative url is /prescriptions
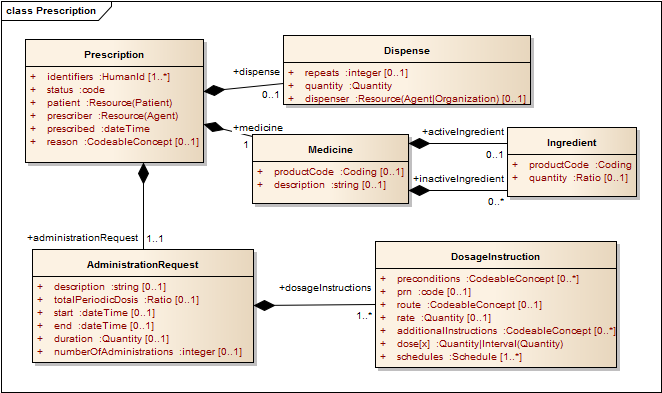
<Prescription xmlns="http://www.hl7.org/fhir"> <id> mand id Master Resource Id, always first in all resources</id> <identifier> mand Zero+ HumanId Prescription identification</identifier> <status> mand code Status: Active|Completed</status> <patient> mand (Patient) Patient receiving medicine</patient> <prescriber> mand (Agent) Prescribing doctor</prescriber> <prescribed> mand dateTime Date/time prescribed</prescribed> <dispense> opt <!-- Details of included dispense request --> <repeats> opt integer Number of repeats</repeats> <quantity> mand Quantity Quantity per repeat</quantity> <dispenser> opt (Agent|Organization) Person to fullfil the requested dispense</dispenser> </dispense> <medicine> mand <!-- Prescribed medicine --> <productCode> cond Coding Coded representation of medicine</productCode> <description> cond string Textual description of medicine</description> <activeIngredient> opt <!-- Zero+ Active substance --> <productCode> mand Coding Coded representation of active ingredient</productCode> <quantity> opt Ratio Relative quantity of active ingredient</quantity> </activeIngredient> <inactiveIngredient> opt <!-- Zero+ Inactive substance --> <productCode> mand Coding Coded representation of inactive ingredient</productCode> <quantity> opt Ratio Relative quantity of inactive ingredient</quantity> </inactiveIngredient> </medicine> <administrationRequest> mand <!-- Instructions for use --> <description> opt string Textual instructions for use</description> <totalPeriodicDosis> opt Ratio Total periodic dosis</totalPeriodicDosis> <start> cond dateTime Startdate for administration</start> <end> cond dateTime Enddate for administration</end> <duration> cond Quantity Total duration of administration</duration> <numberOfAdministrations> cond integer Maximum number of separate administrations</numberOfAdministrations> <dosageInstruction> mand <!-- One+ Dosage instruction --> <precondition> opt Zero+ CodeableConcept Precondition for starting administration</precondition> <prn> opt code Pro re nate: Yes|No</prn> <additionalInstruction> opt Zero+ CodeableConcept Additional instructions</additionalInstruction> <route> opt CodeableConcept Route of administration</route> <dose[x]> mand Quantity|Interval(Quantity) Dose per administration</dose[x]> <rate> opt Quantity Flow-rate for IV</rate> <schedule> mand One+ Schedule Schedule for administration</schedule> </dosageInstruction> </administrationRequest> <reason> opt CodeableConcept Reason for prescription</reason> <extensions> opt See Extensions See Extensions </extensions> <text> mand Narrative Text summary of the prescription, for human interpretation</text> </Prescription>
Schema for Prescription and an example (or formatted for browser (§5.1))
Terminology Bindings
| active | Patient is using the prescribed medicin | |
| completed | Prescription is no longer current | |
| yes | TRUE | |
| no | FALSE | |
Notes:
TODO
There is no content model for the response, except for an HTTP status code.
The following simple search/filter parameters are defined for prescription:
| patient | The identity of a patient to list prescriptions for |
| prescriber | The identity of a prescriber to list prescriptions from |
| startdate | Return only prescriptions made starting from this date |
| enddate | Return only prescriptions made before this date |
| id | search id in any prescription identifiers |
The standard search parameters also apply (see Searching (§2.3.12)).
The formal definitions for the elements above.