
Canonical Resource Management Infrastructure Implementation Guide
1.0.0-snapshot - Snapshot
![]()
Canonical Resource Management Infrastructure Implementation Guide
1.0.0-snapshot - Snapshot
![]()
This page is part of the Canonical Resource Management Infrastructure Implementation Guide (v1.0.0-snapshot: STU1 Draft) based on FHIR (HL7® FHIR® Standard) R4. The current version which supersedes this version is 2.0.0. For a full list of available versions, see the Directory of published versions
This Implementation Guide (IG) is a conformance profile, as described in the Conformance section of the HL7 FHIR specification. The following is a conceptual diagram of various systems and specifications involved in FHIR artifact management.
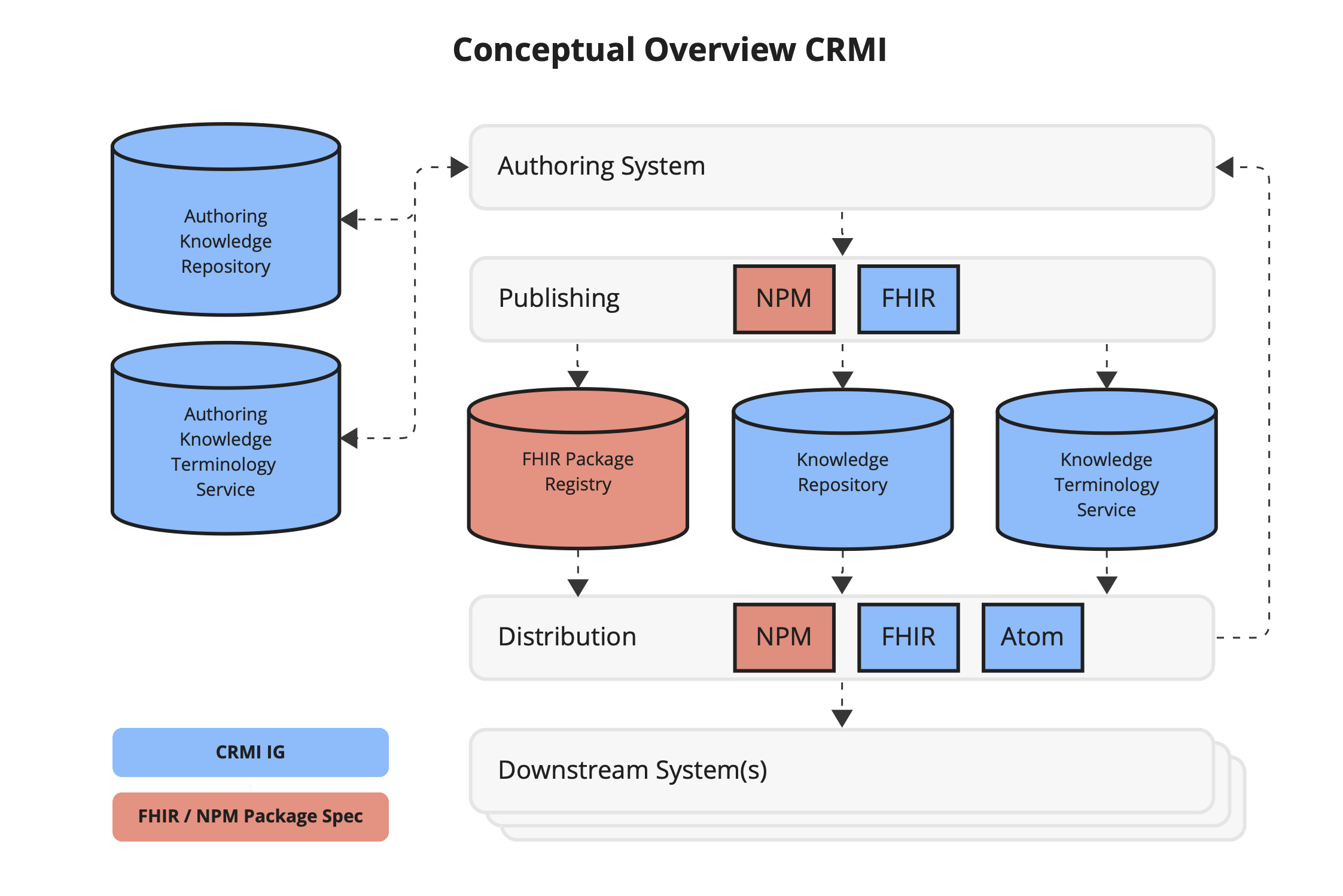
Figure 2.4 Illustrates the management of artifacts as a Canonical Resource Management Infrastructure (CRMI), highlighting the interactions between authoring components, publishing mechanisms such as the Node Package Manager (npm), distribution channels, and downstream systems.
Roles include:
An authoring system supports the development, testing, packaging, and publishing of artifacts. At a minimum, an authoring system must provide for:
Many authoring systems provide additional capabilities such as content validation, change tracking, integrated testing, and more. The focus of this implementation guide is on ensuring that authoring systems can confirm they are managing artifacts in a consistent manner across the artifact lifecycle, from authoring, through publishing, to implementation.
For example, a common authoring system in use in the FHIR artifact development community is:
In this example, the authoring content for the system is stored in a filesystem as text files in a git repository (for example, on GitHub)
This IG also describes capabilities for an authoring repository (i.e. an environment where the authoring system uses a repository to store authoring content, rather than a filesystem). An authoring system can make use of an Authoring Knowledge Repository and Artifact Terminology Service to support the authoring process.
However the content authoring is performed, the capability profiles described in this IG provide a mechanism for ensuring consistent expectations of artifact content.
See Artifact Lifecycle for a description of the artifact lifecycle and artifact management.
An artifact repository is a FHIR server that hosts knowledge artifacts such as profiles, extensions, libraries, and measures. An artifact repository may be simply a distribution service, providing read-only access to content, or it may provide more extensive support for authoring services such as dependency tracing and packaging capabilities, as well as content modification such as drafting, releasing, revising, and reviewing.
See Artifact Repository Service for a complete description of the capabilities provided by an artifact repository.
An artifact terminology service is a FHIR terminology service with specific capabilities to enable management of versioning issues for collections of knowledge artifacts. In particular, support for providing version-binding information as part of terminology operation requests is key to supporting the development of collections of artifacts with extensive terminology references.
See Artifact Terminology Service for a complete description of the capabilities provided by an artifact terminology service.
Publishing refers to the process of surfacing artifacts from the authoring environment to the distribution environment, while distribution refers to the process an implementation uses to retrieve artifacts from a repository.
In the FHIR publishing ecosystem, this is typically done using FHIR Implementation Guides, published as websites which include npm packages containing the artifacts. In addition, these npm packages are registered with the FHIR Package Registry, allowing the packages to be distributed using npm. Implementations typically make use of the artifacts by downloading the packages directly from the IG website, or by integrating with the FHIR npm package registry.
However, this approach to distribution does not adequately address some common use cases for artifact management, including:
This implementation guide provides support for these use cases by describing alternate mechanisms for publishing and distribution. Specifically, the $data-requirements and $package operations support identifying artifact dependencies and packaging artifacts with those dependencies (and only those dependencies), and the Artifact Repository and Artifact Terminology Services describe capabilities for supporting artifact publication and distribution as FHIR APIs.
See Publishing and Distribution for further discussion of these capabilities.
Figure 3.1 below, FHIR-based Knowledge Representation Specifications, depicts four categories of specifications, with representative examples of each category, illustrating how the various pieces can be used together to deliver shareable artifacts. This categorization of implementation guides, though not intended to be exhaustive, provides a useful way to classify types of implementation guides. In particular, the profiles and approaches in the CRMI IG have been adopted from the specification IGs in this diagram and generalized to apply across all types of IGs, specification, model, and content.
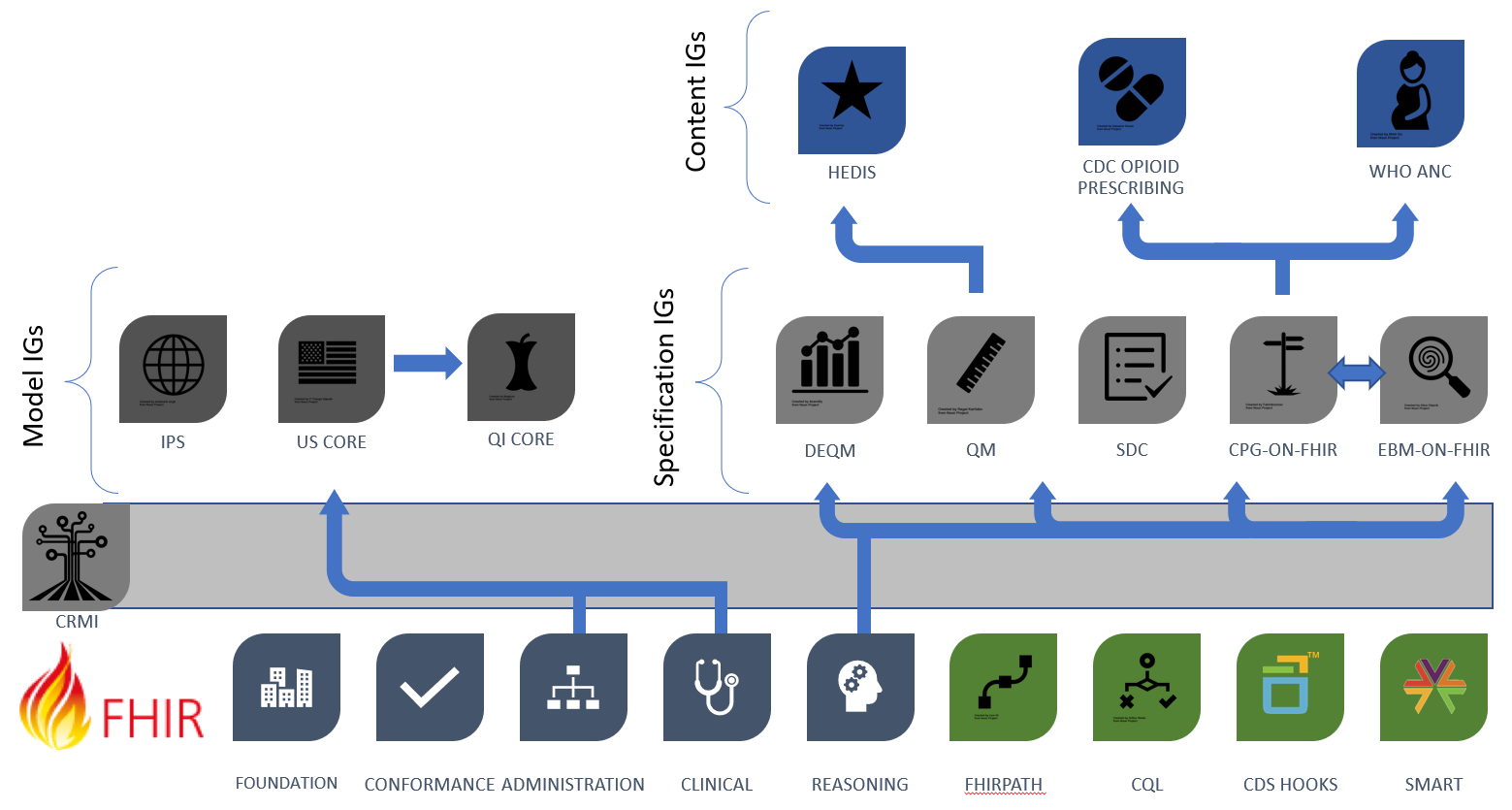
Figure 2.2 Categories of implementation guides: Specification, Model, and Content IGs
As shown in the diagram, the Canonical Resource Management Infrastructure IG provides cross-cutting support for content development across all these types of implementation guides. Future versions of these specifications should consider whether to refactor to make use of the profiles and capabilities provided by this implementation guide.
The foundational standards on the bottom row of the diagram include the layers of FHIR, as well as expression language and integration standards including FHIRPath, Clinical Quality Language (CQL), CDS Hooks, and SMART.
The middle row on the left of the figure shows the Model Implementation Guides, typically derived from FHIR Administration and Clinical resources such as Patient, Encounter, and MedicationRequest. These Model IGs are typically built to address a broad range of use cases, focused on a particular target realm or domain.
The middle row on the right of the figure shows the Specification Implementation Guides, which derive from the FHIR Clinical Reasoning resources to provide implementation guidance and conformance requirements for the creation, distribution, evaluation, and maintenance of shareable clinical knowledge.
In the top row of the figure, the Content Implementation Guides are FHIR Implementation Guides. These IGs are not necessarily balloted as HL7 standards; rather, they use the FHIR publication toolchain to support authoring and distribution as depicted in the rest of the diagram. The content is stewarded by separate authorities such as quality agencies, specialty societies, and guideline developers; groups that have their own governance and maintenance policies. The content IGs conform to the specification IGs on the right of row 2, and typically make use of the model IGs on the left of row 2 to define content focused on a particular realm.
The following diagram illustrates the overall ecosystem of services and capabilities required to support knowledge authoring, distribution, and implementation:
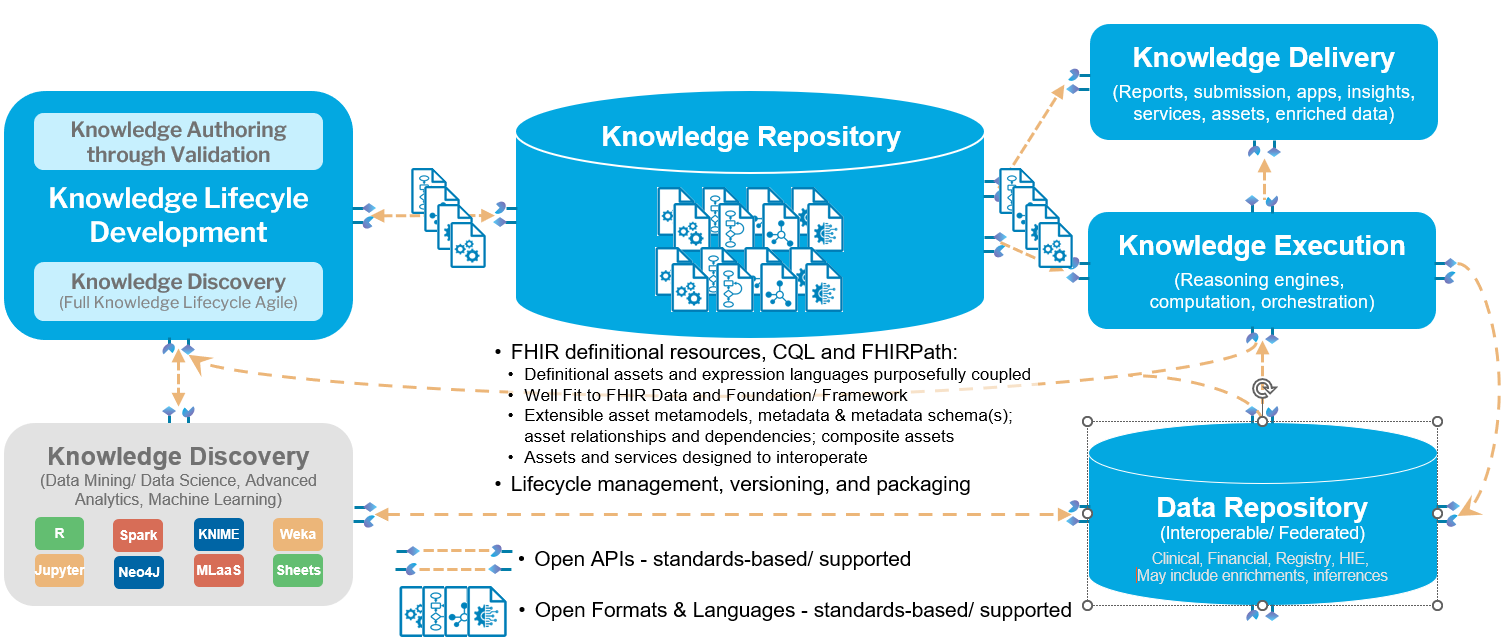
Within this ecosystem, this IG focuses on the following areas:
This implementation guide assumes familiarity with the base FHIR specification, as well as with profiling FHIR and implementation guides. Refer to the Profiling topic in the base specification if needed.
As with any content development effort, FHIR Knowledge Artifacts have a content development lifecycle to create, review, publish, distribute, and implement. This implementation guide is focused on supporting consistent and reliable usage of FHIR Knowledge Artifacts by establishing content development best practices.
This IG has the following aspirations:
The keywords SHALL, SHALL NOT, SHOULD, SHOULD NOT, MAY, and NEED NOT in this document are to be interpreted as defined in RFC 2119. Unlike RFC 2119, however, this specification allows that different applications may not be able to interoperate because of how they use optional features. In particular
Certain elements in the profiles defined in this implementation guide are marked as Must Support. This flag is used to indicate that the element plays a critical role in defining, sharing, and implementing artifacts, and implementations SHALL understand and process the element.
In addition, because artifact specifications typically make use of data implementation guides (e.g. IPS, US Core, QI-Core), the implications of the Must Support flag for profiles used from those implementation guides must be considered.
For more information, see the definition of Must Support in the base FHIR specification.
Conformance Requirement 2.1 (Must Support Elements): ![]()
For resource instances claiming to conform to CRMI IG profiles, Must Support on any profile data element SHALL be interpreted as follows:
IG © 2022+ HL7 International / Clinical Decision Support. Package hl7.fhir.uv.crmi#1.0.0-snapshot based on FHIR 4.0.1. Generated 2024-04-06
Links: Table of Contents |
QA Report
| Version History |
 |
Propose a change
|
Propose a change