
Clinical Practice Guidelines
2.0.0 - STU2
![]()
Clinical Practice Guidelines
2.0.0 - STU2
![]()
This page is part of the Clinical Guidelines (v2.0.0: STU2) based on FHIR (HL7® FHIR® Standard) R4. This is the current published version. For a full list of available versions, see the Directory of published versions
Knowledge assets or artifacts as they are often referred to in FHIR, where an artifact is an instance of an asset. Assets provide the ability to keep domain logic separated and distinct from other system logic in complex systems. In this implementation guide we often refer to knowledge assets and knowledge artifacts interchangeably, though the distinction is very relevant to the knowledge engineer.
The asset meta-model is a model that essentially describes what is required and/or allowed for a given class of knowledge assets. This includes its ‘schema’ (e.g attributes, cardinality), the scope or range of values allow for given attributes, expressions or other formalisms to be used with an asset class, required and optional metadata (often using a metadata metamodel). In FHIR, the means of defining asset metamodels is the FHIR StructureDefinition Resource (though it is also used for definitions of resources other than knowledge assets including all request (e.g. orders) and event (e.g. clinical data element) resources). Furthermore, the PlanDefinition Resource (based on the HL-7 Knowledge Artifact Specification) is a base, or more generic, asset meta-model definition that may be profiled using StructureDefinition to further define additional asset meta-models. The FHIR Library Resource and GraphDefinition Resource are additional FHIR resources used in this limitation guide as definitional resources for accepting meta-models. The asset metamodels (definition of structure including metadata, attributes, requirements and constraints) are defined in the this implementation guide using an approach to Knowledge Artifact Representation in FHIR described in the Clinical Reasoning Module.
Knowledge asset content refers to that which is contained within a specific knowledge asset. This includes the scoped values or expressions for a specific asset’s metadata, attributes, and other formalisms used to express the knowledge contained within the asset. The content must adhere to the rules and constraints imparted by a given asset’s meta-model. Content is what gives a specific asset its meaning, function or behavior, and enables it to perform its intent when reasoned over at ‘run-time’. Metadata about the content may be derived or asserted (e.g. annotated through human or machine processes).
Metadata is data that provides information about the knowledge asset. This may include disk active metadata, structural metadata, administrative metadata, and situating or relational metadata. Descriptive metadata provides information about the nature of the knowledge asset as well as information about the nature of the content of an individual knowledge asset. Structural metadata provide information about the representation(s) and/or formalism(s) used in the knowledge asset (e.g. the metamodel used for the asset and how it was applied for this specific asset). Administrative metadata is information that helps manage the knowledge asset and is inclusive of knowledge engineering lifecycle, governance, and authorization or rights metadata. Situational or relational metadata describes an assets relationship to other assets as well as the totality of its relationships within the knowledge base. Metadata may be further broken down to the following category:
In FHIR, asset metadata is addressed in several ways. First, the FHIR Resources, particularly those that are definitional(e.g., plan definition, activity definition, measure definition, questionnaire) to be used as asset “containers” have their own metadata attributes as defined with each resource. Furthermore, shared metadata elements in FHIR Resources are described https://www.hl7.org/fhir/resource.html and more detailed information about FHIR Metadata may be found (ref), or here (ref). The section on Metadata of the Clinical Reasoning Module on Knowledge Artifact Representation provides a description of how metadata is routinely addressed in FHIR Knowledge Artifact Representations.
Metadata may be semantic, using coded concepts in terminologies and ontologies in order to facilitate numerous functions across the knowledge engineering lifecycle and within a knowledge content management system. Similarly values for metadata may be references to other knowledge assets and or their attributes (including their metadata).
To ensure integrity across all knowledge assets in a knowledge content management system, an asset’s definition (metamodel) often references a common, shared asset metadata meta-model (definition of the metadata that may or must be used across all assets in a common knowledge base). Additional information about and approaches to metadata are described by the Mobilizing Computable Biomedical Knowledge (MCBK) (ref, ref) and OMG (ref)
An expression is a computable language for creating a computer-interpretable representation of specific knowledge. In HL-7 and for the scope of this implementation guide, the expression language used (where it is able to sufficiently express the intended logic behavior) is the Clinical Quality Language (CQL). CQL further has affordances for referencing additional languages (e.g. Java, C#, or Python) akin to remote procedure calls, as well as callouts to services where the needs to express computable logic exceed the limits of CQL.
A declaration is an expression of the structural elements of computable logic (e.g. values for attributes and parameters of a knowledge asset) that does not describe how to compute the logic, rather what the logic is. Declarations express the logic of a computation without describing its control flow (ref). These declarations may then reference and/or be referenced by expressions as described above. The PlanDefinition Resource is a declarative knowledge asset definition in HL-7 FHIR whose meta-model affords the means to reference and or be referenced by CQL or other expression languages. A specific PlanDefinition is a declarative knowledge asset.
No single representation or expression can sufficiently and/or appropriately describe the nature and behavior of many domain concepts using computable formalism. Furthermore, many domain concepts build on and/or reference one another. To address these issues as well as some issues related to scalability and reusability or shareability, many knowledge assets are actually comprised of or composed using other knowledge assets. A CPGPathway, CPGStrategy, and CPGRecommendation are examples of composite asset in this implementation guide.
Furthermore, many knowledge assets may be derived from other knowledge assets (in part or in whole) as a means to reuse and repurpose the content of the knowledge asset from which they were derived. For example, a CPGMetric may derive much of its content from a CPGRecommendation. Derived knowledge assets may be wholly or partially derived from other assets.
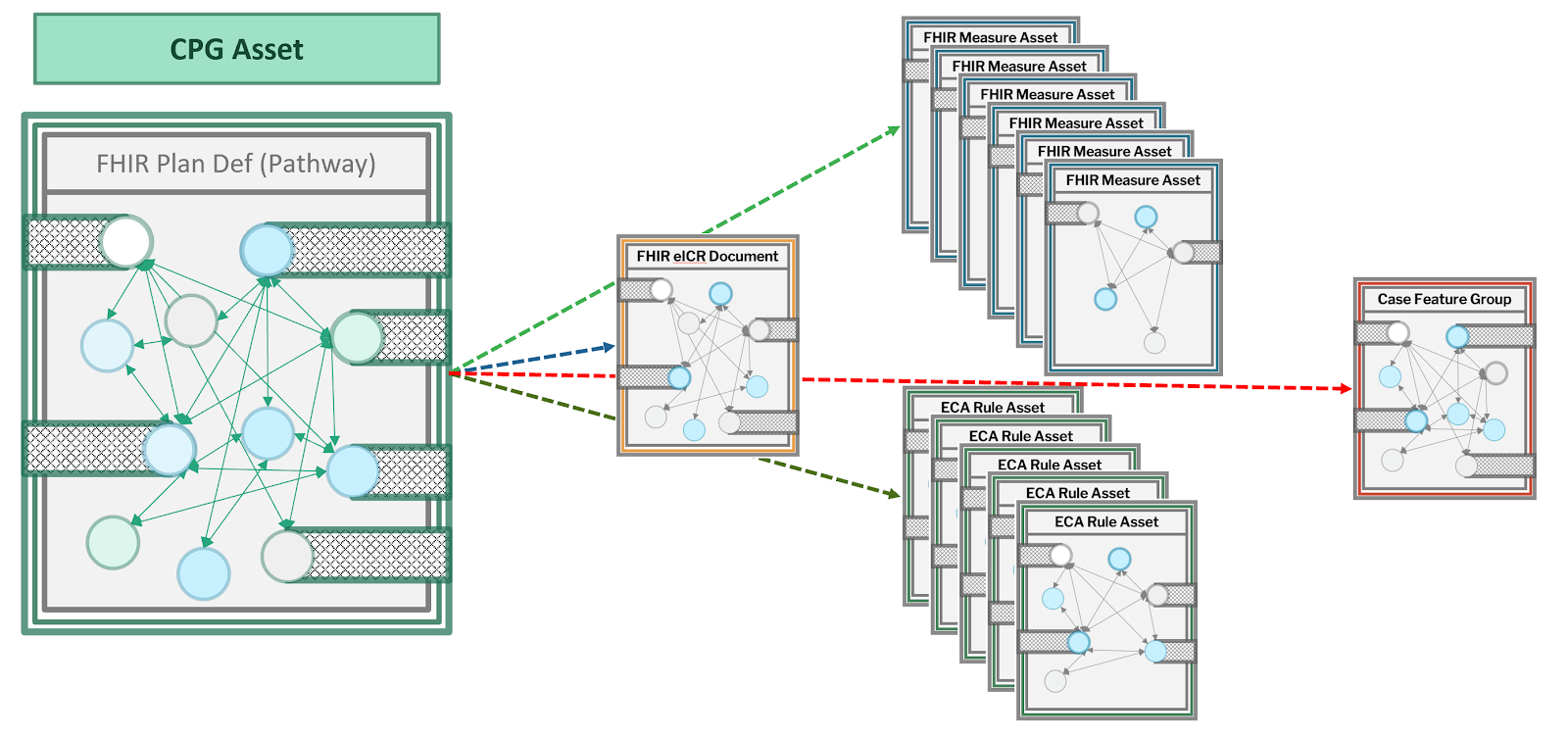
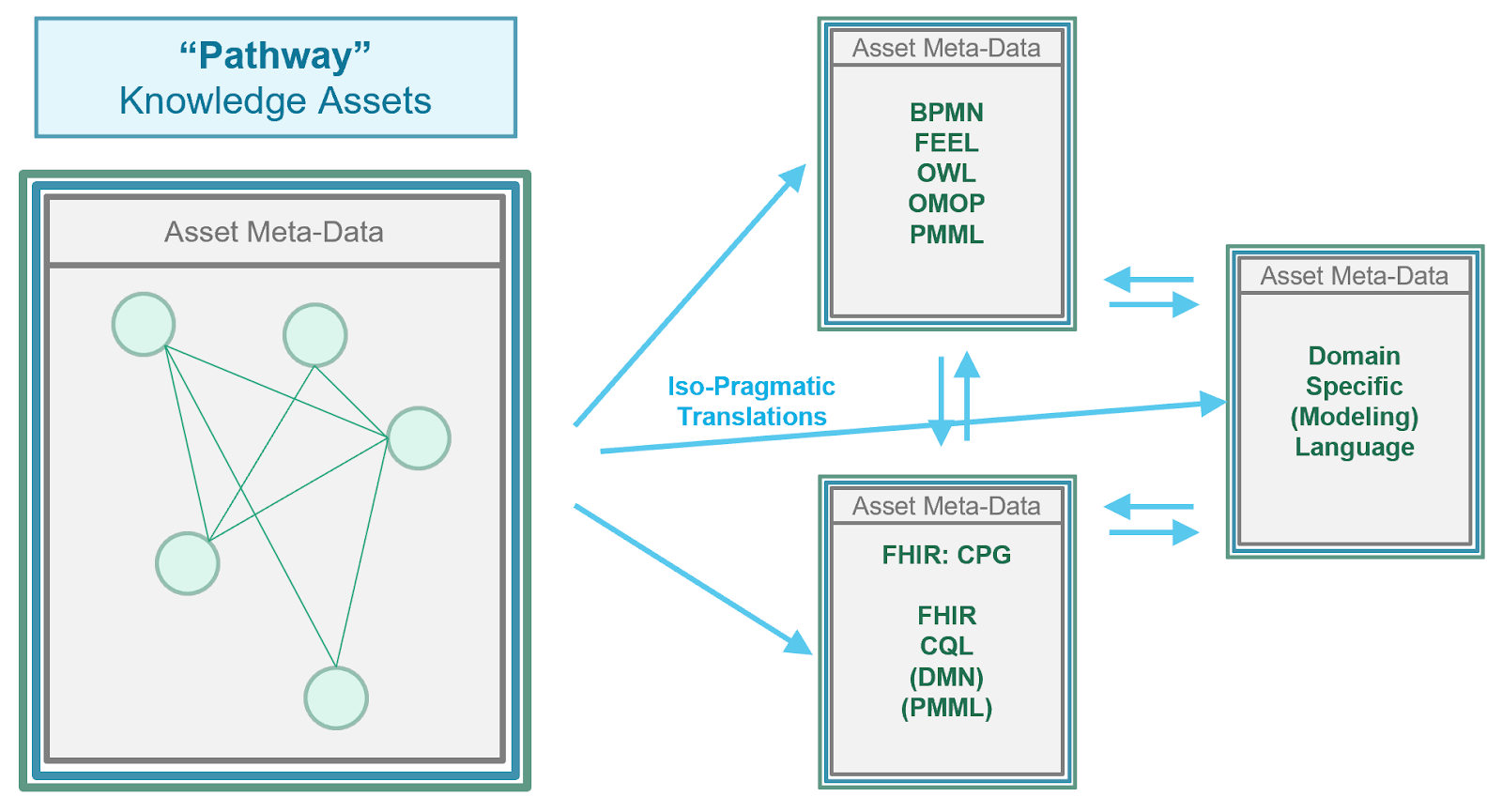
Some knowledge assets may be represented using multiple alternative formalisms (expressions and declarations), yet express the same meaning and intent resulting in identical behavior when reasoning over identical inputs (data elements). This equivalence in computational intent and behavior is known as isopragmatism. This affords the ability to transform (and/or translate) between different formalisms of the same knowledge content. Isopragmatic transformations between such knowledge representations is the knowledge equivalent of iso-semantic transformations between different combinations of information model + terminologies. Reasons to use alternative, isopragmatic representations of knowledge assets include ease-of-use of tooling (e.g. one representation has more capable authoring and/or validation tools) as well as the capabilities that exist within alternative delivery mechanisms and/or implementation environments. For more on isopragmatic knowledge representations see the BPM+ section in Methodology.
IG © 2023+ HL7 International / Clinical Decision Support. Package hl7.fhir.uv.cpg#2.0.0 based on FHIR 4.0.1. Generated 2024-11-26
Links: Table of Contents |
QA Report
| Version History |
 |
Propose a change
|
Propose a change